Algoritmo KNN de Machine Learning
El algoritmo KNN de Machine Learning o de k-vecinos más cercanos (K-Nearest Neighbors o KNN) es un algoritmo de aprendizaje automático supervisado, simple y fácil de implementar que se puede utilizar para resolver problemas de clasificación y regresión. Analicemos eso.
Una explicación de manera simple
Un algoritmo de Machine Learning (a diferencia de un algoritmo de aprendizaje automático no supervisado) es uno que se basa en datos de entrada etiquetados para aprender una función que produce un resultado apropiado cuando se le dan nuevos datos sin etiqueta.

Imagine que una computadora es un niño, somos su supervisor (por ejemplo, padre, tutor o maestro) y queremos que el niño (computadora) sepa cómo es un perro.
Le mostraremos al niño varias imágenes diferentes, algunas de las cuales son perros y el resto podrían ser imágenes de cualquier cosa (gatos, cabras, cerdos, etc.)
Cuando vemos un perro, gritamos “¡perro!” Cuando no es un perro, gritamos “¡no, no perro!” Después de hacer esto varias veces con el niño, les mostramos una imagen y preguntamos “¿perro?” y ellos dicen (“la mayoría de las veces”) “¡perro!” o “no, no” perro! “dependiendo de lo que es la imagen. Eso es aprendizaje automático supervisado.

Los algoritmos de Machine Learning supervisados se usan para resolver problemas de clasificación o regresión.
Un problema de clasificación tiene un valor discreto como resultado. Por ejemplo, “le gusta la pizza con piña” y “no le gusta la pizza con piña” son discretos. No hay término medio. La analogía anterior de enseñar a un niño a identificar un cerdo es otro ejemplo de problema de clasificación.


Esta imagen muestra un ejemplo básico de cómo se verían los datos de clasificación. Tenemos un predictor (o conjunto de predictores) y una etiqueta. En la imagen, podríamos intentar predecir si a alguien le gusta la piña (1) en su pizza o no (0) en función de su edad (el predictor).
Es una práctica estándar representar la salida (etiqueta) de un algoritmo de clasificación como un número entero como 1, -1 o 0. En este caso, estos números son puramente representación.
Las operaciones matemáticas no deberían realizarse en ellos porque hacerlo no tendría sentido. Piense por un momento, ¿qué es “le gusta la piña” + “no le gusta la piña”? Exactamente. No podemos agregarlos, por lo que no deberíamos agregar sus representaciones numéricas.
Un problema de regresión tiene un número real (un número con un punto decimal) a medida que sale. Por ejemplo, podríamos usar los datos en la tabla a continuación para estimar el peso de una persona dada su altura.


Datos utilizados en un análisis de regresión se verá similar a los datos que se muestran en la imagen de arriba. Tenemos:
- Variable independiente (o un conjunto de variables independientes).
- Variable dependiente (lo que intentamos adivinar dadas nuestras variables independientes).
Por ejemplo, podríamos decir que la altura es la variable independiente y el peso es la variable dependiente.
Además, cada fila se llama típicamente un ejemplo una observación o un punto de datos mientras que cada columna (sin incluir el etiqueta / variable dependiente) a menudo se llama un predictor, dimensión, variable independiente o característica.
Un algoritmo de aprendizaje automático no supervisado hace uso de datos de entrada sin etiquetas -en otro palabras, ningún maestro (etiqueta) que le dice al niño (computadora) cuándo es correcto o cuándo se ha cometido un error para que pueda autocorregirse.
A diferencia del aprendizaje supervisado que intenta aprender una función que nos permitirá hacer predicciones dadas algunos datos nuevos sin etiqueta, el aprendizaje no supervisado intenta aprender la estructura básica de los datos para darnos más información sobre los datos.
KNN de Machine Learning (K-Nearest Neighbors)
El algoritmo KNN de Machine Learning supone que existen cosas similares muy cerca. En otras palabras, cosas similares están cerca la una de la otra.
“Pájaros del mismo plumaje se juntan”:
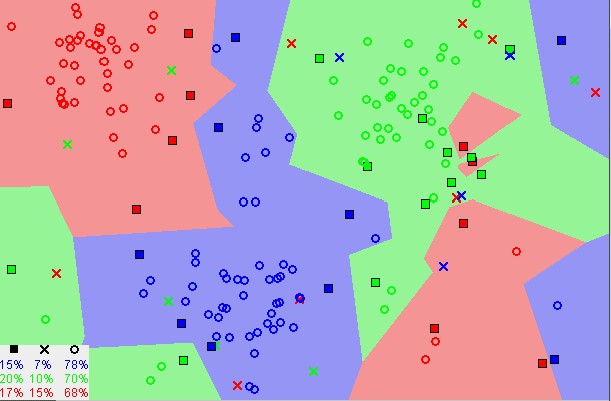
Aviso en la imagen de arriba que la mayoría de las veces, puntos de datos similares están cerca el uno del otro. El algoritmo KNN de Machine Learning depende de que esta suposición sea lo suficientemente cierta para que el algoritmo sea útil.
KNN captura la idea de similitud (a veces llamada distancia, proximidad o cercanía) con algunas matemáticas que podríamos haber aprendido en nuestra infancia, calculando la distancia entre puntos en un gráfico.
Nota: Es necesario comprender cómo calculamos la distancia entre puntos en un gráfico antes de continuar. Si no está familiarizado o necesita una actualización sobre cómo se realiza este cálculo, lea atentamente “ Distancia entre 2 puntos ” en su totalidad, y regrese.
Hay otras formas de calculando la distancia, y de una manera puede ser preferible dependiendo del problema que estamos resolviendo. Sin embargo, la distancia en línea recta (también llamada distancia euclidiana) es una elección popular y familiar.
Algoritmo KNN de Machine Learning (K-vecinos más cercanos)
- Carga los datos.
- Inicializa K a tu número elegido de vecinos.
- Para cada ejemplo en los datos.
- Calcule la distancia entre el ejemplo de consulta y el ejemplo actual a partir de los datos.
- Agregue la distancia y el índice del ejemplo a una colección ordenada.
- Clasifique la colección ordenada de distancias e índices desde el más pequeño hasta el más grande (en orden ascendente) por las distancias.
- Elija las primeras K entradas de la colección ordenada.
- Obtenga las etiquetas de las entradas K seleccionadas.
- Si es regresión, devuelva la media de las etiquetas K.
- Si la clasificación es, devuelva el modo de las etiquetas K.
La implementación KNN (desde cero)
from collections import Counter
import math
def knn(data, query, k, distance_fn, choice_fn):
neighbor_distances_and_indices = []
# 3. For each example in the data
for index, example in enumerate(data):
# 3.1 Calculate the distance between the query example and the current
# example from the data.
distance = distance_fn(example[:-1], query)
# 3.2 Add the distance and the index of the example to an ordered collection
neighbor_distances_and_indices.append((distance, index))
# 4. Sort the ordered collection of distances and indices from
# smallest to largest (in ascending order) by the distances
sorted_neighbor_distances_and_indices = sorted(neighbor_distances_and_indices)
# 5. Pick the first K entries from the sorted collection
k_nearest_distances_and_indices = sorted_neighbor_distances_and_indices[:k]
# 6. Get the labels of the selected K entries
k_nearest_labels = [data[i][-1] for distance, i in k_nearest_distances_and_indices]
# 7. If regression (choice_fn = mean), return the average of the K labels
# 8. If classification (choice_fn = mode), return the mode of the K labels
return k_nearest_distances_and_indices , choice_fn(k_nearest_labels)
def mean(labels):
return sum(labels) / len(labels)
def mode(labels):
return Counter(labels).most_common(1)[0][0]
def euclidean_distance(point1, point2):
sum_squared_distance = 0
for i in range(len(point1)):
sum_squared_distance += math.pow(point1[i] - point2[i], 2)
return math.sqrt(sum_squared_distance)
def main():
'''
# Regression Data
#
# Column 0: height (inches)
# Column 1: weight (pounds)
'''
reg_data = [
[65.75, 112.99],
[71.52, 136.49],
[69.40, 153.03],
[68.22, 142.34],
[67.79, 144.30],
[68.70, 123.30],
[69.80, 141.49],
[70.01, 136.46],
[67.90, 112.37],
[66.49, 127.45],
]
# Question:
# Given the data we have, what's the best-guess at someone's weight if they are 60 inches tall?
reg_query = [60]
reg_k_nearest_neighbors, reg_prediction = knn(
reg_data, reg_query, k=3, distance_fn=euclidean_distance, choice_fn=mean
)
'''
# Classification Data
#
# Column 0: age
# Column 1: likes pineapple
'''
clf_data = [
[22, 1],
[23, 1],
[21, 1],
[18, 1],
[19, 1],
[25, 0],
[27, 0],
[29, 0],
[31, 0],
[45, 0],
]
# Question:
# Given the data we have, does a 33 year old like pineapples on their pizza?
clf_query = [33]
clf_k_nearest_neighbors, clf_prediction = knn(
clf_data, clf_query, k=3, distance_fn=euclidean_distance, choice_fn=mode
)
if __name__ == '__main__':
main()
Elección del valor correcto para K
Para seleccionar la K que es adecuada para sus datos, ejecutamos el algoritmo KNN varias veces con diferentes valores de K y elegimos la K que reduce la cantidad de errores que encontramos mientras mantenemos la habilidad del algoritmo para hacer predicciones con precisión cuando se le dan datos que no ha visto antes.
Aquí hay algunas cosas a tener en cuenta:
- A medida que disminuimos el valor de K a 1, nuestras predicciones se vuelven menos estables. Piénselo por un minuto, imagine K=1 y tenemos un punto de consulta rodeado por varios rojos y uno verde (estoy pensando en la esquina superior izquierda del gráfico coloreado de arriba), pero el verde es el vecino más cercano. Razonablemente, pensaríamos que lo más probable es que el punto de consulta sea rojo, pero debido a que K = 1, KNN predice incorrectamente que el punto de consulta es verde.
- Inversamente, a medida que aumentamos el valor de K, nuestras predicciones se vuelven más estables debido a la votación mayoritaria/promedio y, por lo tanto, es más probable que hagamos predicciones más precisas (hasta cierto punto). Con el tiempo, comenzamos a presenciar un número cada vez mayor de errores. Es en este punto que sabemos que hemos llevado el valor de K demasiado lejos.
- En los casos en los que tomamos una votación mayoritaria (por ejemplo, eligiendo la moda en un problema de clasificación) entre etiquetas, generalmente hacemos que K sea un número impar para tener un desempate..
Ventajas
- El algoritmo es simple y fácil de implementar.
- No es necesario construir un modelo, ajustar varios parámetros o hacer suposiciones adicionales.
- El algoritmo es versátil. Puede usarse para clasificación, regresión y búsqueda (como veremos en la siguiente sección).
Desventajas
- El algoritmo se vuelve significativamente más lento a medida que aumenta el número de ejemplos y / o predictores / variables independientes.
KNN en la práctica
La desventaja principal de KNN de volverse significativamente más lenta a medida que aumenta el volumen de datos hace que sea una elección poco práctica en entornos donde las predicciones deben hacerse rápidamente.
Además, existen algoritmos más rápidos que pueden producir resultados de clasificación y regresión más precisos. Sin embargo, siempre que tenga suficientes recursos informáticos para manejar rápidamente los datos que está utilizando para hacer predicciones.
KNN puede ser útil para resolver problemas que tienen soluciones que dependen de identificar objetos similares. Un ejemplo de esto es usar el algoritmo KNN en los sistemas de recomendación, una aplicación de KNN-search.
Sistemas de recomendación
A escala, esto sería como recomendar productos en Amazon, artículos en Medium, películas en Netflix o videos en YouTube. Aunque podemos estar seguros de que todos utilizan medios más eficientes para hacer recomendaciones debido al enorme volumen de datos que procesan.
Sin embargo, podríamos replicar uno de estos sistemas de recomendación a menor escala utilizando lo que hemos aprendido aquí en este artículo. Construyamos el núcleo de un sistema de recomendación de películas.
¿Qué pregunta intentamos responder?
Dado nuestro conjunto de datos de películas, ¿Cuáles son las cinco películas más similares a una consulta de película?
Recopilar datos de películas
Si trabajáramos en Netflix, Hulu o IMDb, podríamos obtener los datos de su almacén de datos. Como no trabajamos en ninguna de esas empresas, tenemos que obtener nuestros datos por otros medios. Podríamos utilizar algunos datos de películas del repositorio de aprendizaje automático de la UCI, el conjunto de datos de IMDb o crear minuciosamente el nuestro propio.
Explorar, limpiar y preparar los datos
Dondequiera que obtuvimos nuestros datos, puede haber algunas cosas incorrectas que necesitamos corregir para prepararlo para el algoritmo KNN de Machine Learning.
Por ejemplo, los datos pueden no estar en el formato que el algoritmo espera, o pueden faltar valores que debemos llenar o eliminar de los datos antes de conectarlos al algoritmo.
Nuestra implementación KNN anterior se basa en datos estructurados. Necesita estar en formato de tabla. Además, la implementación asume que todas las columnas contienen datos numéricos y que la última columna de nuestros datos tiene etiquetas en las que podemos realizar alguna función. Entonces, donde sea que tengamos nuestros datos, tenemos que hacerlo conforme a estas restricciones.
Los datos a continuación son un ejemplo de cómo se asemejan nuestros datos limpios. Los datos contienen treinta películas, incluidos los datos de cada película en siete géneros y sus calificaciones de IMDB.
La columna de etiquetas tiene todos los ceros porque no estamos usando este conjunto de datos para la clasificación o regresión.
| Movie ID | Movie Name | IMDB Rating | Biography | Drama | Thriller | Comedy | Crime | Mystery | History | Label |
| 58 | The Imitation Game | 8 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 8 | Ex Machina | 7.7 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 46 | A Beautiful Mind | 8.2 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 62 | Good Will Hunting | 8.3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 97 | Forrest Gump | 8.8 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 98 | 21 | 6.8 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 31 | Gifted | 7.6 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Travelling Salesman | 5.9 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 51 | Avatar | 7.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 47 | The Karate Kid | 7.2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 50 | A Brilliant Young Mind | 7.2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 49 | A Time To Kill | 7.4 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| 30 | Interstellar | 8.6 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 94 | The Wolf of Wall Street | 8.2 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 6 | Black Panther | 7.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 73 | Inception | 8.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 44 | The Wind Rises | 7.8 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 65 | Spirited Away | 8.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 48 | Finding Forrester | 7.3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 27 | The Fountain | 7.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 57 | The DaVinci Code | 6.6 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 57 | Stand and Deliver | 7.3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 14 | The Terminator | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 69 | 21 Jump Street | 7.2 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 98 | The Avengers | 8.1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 17 | Thor: Ragnarok | 7.9 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 12 | Spirit: Stallion of the Cimarron | 7.1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | Hacksaw Ridge | 8.2 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 86 | 12 Years a Slave | 8.1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 46 | Queen of Katwe | 7.4 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
Además, hay relaciones entre las películas que no lo harán tener en cuenta (por ejemplo, actores, directores y temas) cuando se usa el algoritmo KNN de Machine Learning simplemente porque los datos que capturan esas relaciones faltan en el conjunto de datos.
En consecuencia, cuando ejecutamos el algoritmo KNN en nuestros datos, la similitud se basará únicamente en los géneros incluidos y las calificaciones IMDB de las películas.
Use el algoritmo
Imagínese por un momento. Estamos navegando en el sitio web de MoviesXb, un spin-off ficticio de IMDb, y encontramos The Post . No estamos seguros de querer verlo, pero sus géneros nos intrigan; tenemos curiosidad acerca de otras películas similares.
Nos desplazamos hacia abajo a la sección “Más me gusta” para ver qué recomendaciones hará MoviesXb, y los engranajes algorítmicos comienzan a cambiar.
El sitio web de MoviesXb envía una solicitud a su back-end para las 5 películas que son más similares a The Post . El back-end tiene un conjunto de datos de recomendación exactamente igual al nuestro.
Comienza por crear la representación de fila (más conocida como vector de función ) para The Post luego ejecuta un programa similar al siguiente para buscar las 5 películas que son más similar a The Post y finalmente envía los resultados al sitio web de MoviesXb.
from knn_from_scratch import knn, euclidean_distance
def recommend_movies(movie_query, k_recommendations):
raw_movies_data = []
with open('movies_recommendation_data.csv', 'r') as md:
# Discard the first line (headings)
next(md)
# Read the data into memory
for line in md.readlines():
data_row = line.strip().split(',')
raw_movies_data.append(data_row)
# Prepare the data for use in the knn algorithm by picking
# the relevant columns and converting the numeric columns
# to numbers since they were read in as strings
movies_recommendation_data = []
for row in raw_movies_data:
data_row = list(map(float, row[2:]))
movies_recommendation_data.append(data_row)
# Use the KNN algorithm to get the 5 movies that are most
# similar to The Post.
recommendation_indices, _ = knn(
movies_recommendation_data, movie_query, k=k_recommendations,
distance_fn=euclidean_distance, choice_fn=lambda x: None
)
movie_recommendations = []
for _, index in recommendation_indices:
movie_recommendations.append(raw_movies_data[index])
return movie_recommendations
if __name__ == '__main__':
the_post = [7.2, 1, 1, 0, 0, 0, 0, 1, 0] # feature vector for The Post
recommended_movies = recommend_movies(movie_query=the_post, k_recommendations=5)
# Print recommended movie titles
for recommendation in recommended_movies:
print(recommendation[1])
Cuando ejecutamos este programa, vemos que MoviesXb recomienda 12 Years A Slave Hacksaw Ridge Reina de Katwe The Wind Rises y A Beautiful Mind .
Ahora que comprendemos completamente cómo funciona el algoritmo KNN de Machine Learning, podemos explicar exactamente cómo llegó el algoritmo KNN a hacer estas recomendaciones. ¡Felicitaciones!
Resumen
El algoritmo de k vecinos más cercanos (KNN) es un algoritmo de aprendizaje automático simple y supervisado que se puede utilizar para resolver problemas de clasificación y regresión. Es fácil de implementar y comprender, pero tiene el gran inconveniente de volverse significativamente más lento a medida que crece el tamaño de los datos en uso.
KNN funciona encontrando las distancias entre una consulta y todos los ejemplos en los datos, seleccionando el número especificado de ejemplos (K) más cercanos a la consulta, luego vota por la etiqueta más frecuente (en el caso de clasificación) o promedia las etiquetas (en el caso de la regresión).
En el caso de la clasificación y la regresión, vimos que elegir la K adecuada para nuestros datos se hace probando varias K y eligiendo la que funciona mejor.
Finalmente, analizamos un ejemplo de cómo se podría utilizar el algoritmo KNN en sistemas de recomendación, una aplicación de búsqueda KNN.
Si aprendiste algo nuevo o disfrutaste este artículo, por favor apláudelo 👏 y compártelo para que otros lo vean. No dude en dejar un comentario también.

Codificar datos categóricos en aprendizaje automático

Aprendizaje automático y movimiento de partículas en líquidos: un enlace elegante
