
Machine Learning Parte 3 – Selección de métricas de evaluación correcta: Métricas de clasificación.
Machine Learning , un tema que hemos visto en el artículo anterior Parte 1 y Parte 2 en el cual discutimos las métricas para los problemas de regresión. En este artículo se presentan las métricas de evaluación de clasificación.
Presentemos primero las principales métricas de clasificación usadas en Machine Learning:
- Matriz de confusión o error
- Precisión
- Recall o sensibilidad o TPR (Tasa positiva real)
- Precisión
- Especificidad o TNR (Tasa negativa real)
- F1-Score
- Área bajo la curva de funcionamiento del receptor (ROC) (AUC)
- Pérdida logarítmica
- Cohen’s Kappa
Machine Learning: Confusion Matrix
Confusión o error Matrix es una tabla que describe el rendimiento de un modelo supervisado de Machine Learning en los datos de prueba, donde se desconocen los verdaderos valores. Se llama “matriz de confusión” porque hace que sea fácil detectar dónde el sistema está confundiendo dos clases.

- True Positives (TP): cuando la clase real del punto de datos era 1 (Verdadero) y la predicha es también 1 (Verdadero)
- Verdaderos Negativos (TN): cuando la clase real del punto de datos fue 0 (Falso) y el pronosticado también es 0 (Falso).
- False Positives (FP): cuando la clase real del punto de datos era 0 (False) y el pronosticado es 1 (True).
- False Negatives (FN): Cuando la clase real del punto de datos era 1 (Verdadero) y el valor predicho es 0 (Falso).

El escenario ideal que todos queremos es que el modelo dé 0 False Positives y 0 False Negatives.
Por ejemplo para la imagen siguiente se ilustra el resultado de una función “confusion_matrix” de sklearn, utilizada para un problema de clasificación en el que estamos prediciendo si una persona tiene cáncer o no.

Vamos a dar una etiqueta a nuestra variable de destino:
1 : cuando una persona tiene cáncer
0: Cuando una persona NO está teniendo cáncer.
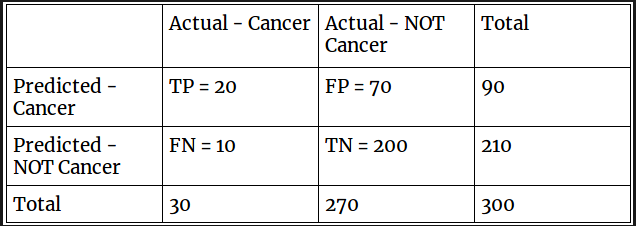

La matriz de confusión en en sí mismo no es una medida de desempeño como tal, pero casi todas las métricas de desempeño se basan en la matriz de confusión y los números dentro de ella.
Minimizando falsos negativos VS falsos positivos
En el ejemplo del problema de detección de cáncer digamos que de 100 personas, solo 5 personas tienen cáncer Definitivamente queremos capturar todos los casos de cáncer y podríamos terminar haciendo una clasificación cuando la persona que realmente NO tiene cáncer se clasifica como cancerosa.
Esto podría estar bien ya que perder a un paciente con cáncer será un gran error ya que no se realizarán más exámenes. Por lo tanto, es mejor minimizar los falsos negativos en este caso
Consideremos ahora un problema de detección de spam por correo electrónico y que está esperando un correo electrónico importante como una respuesta de un reclutador o esperando una carta de admisión de una universidad.
Asigne una etiqueta a la variable de destino y diga:
1:”El correo electrónico es un correo no deseado” y
0:”El correo electrónico no es un correo no deseado”
Supongamos que el Modelo clasifica ese correo electrónico importante que usted están esperando desesperadamente, como Spam (caso de falso positivo).
Por lo tanto, en el caso de la clasificación de correos electrónicos no deseados, minimizar los falsos positivos es más importante que los falsos negativos.
Machine Learning: Accuracy (Precisión)
Es el porcentaje total de elementos clasificados correctamente.
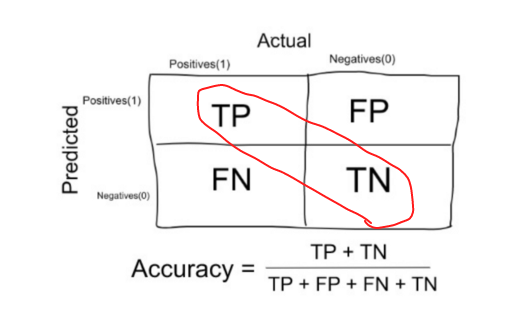

Por lo tanto, para nuestro ejemplo: Precisión = (20 + 200) / (20 + 10 + 70 + 200) = 220/300.
Es la medida más directa de la calidad de los clasificadores. Es un valor entre 0 y 1. Cuanto más alto, mejor.
Esta métrica es tan intuitiva y natural, de hecho, que las personas a menudo la utilizan sin pensarlo dos veces, aunque ciertamente no es apropiado en muchos casos.
Desventaja significativa
Obviamente la mejor constante para predecir en el caso de precisión es la clase más frecuente. Sin embargo, esto puede ocasionar problemas si las clases de variables de destino en los datos no están balanceadas.
Ejemplo: Digamos que tenemos 10 gatos y 90 perros en nuestro conjunto de trenes.


Si siempre predijimos un perro para cada objeto, entonces la precisión sería sea 0,9. Pero de hecho, su modelo simplemente predice la clase de perro sin importar cuál sea la entrada.
Entonces, el problema es que la precisión de la línea de base puede ser muy alta para un conjunto de datos, incluso del 99%, y eso lo hace difícil para interpretar los resultados.
Por lo tanto, Accuracy es una buena medida cuando las clases de variables de destino en los datos están casi equilibradas.
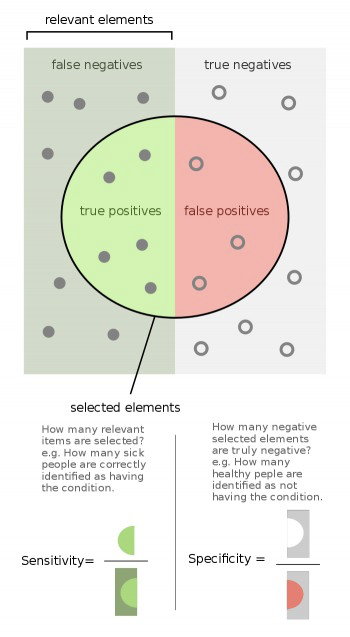
Machine Learning: Recall, Sensibilidad o TPR (Tasa de True Positive)
Es el número de elementos identificados correctamente como positivos del total de positivos verdaderos.

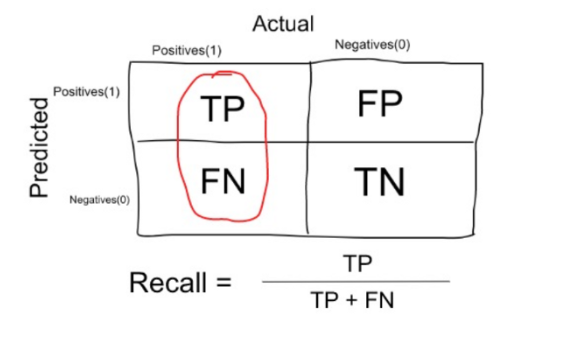
Por lo tanto, para nuestro ejemplo: Recall = 20 / (20 + 10) = 20/30
Machine Learning: Precisión
Es el número de elementos identificados correctamente como positivo de un total de elementos identificados como positivos.
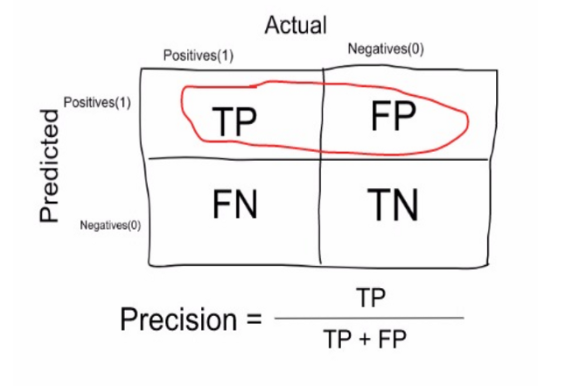

Por lo tanto, para nuestro ejemplo: Precisión = 20 / (20 + 70) = 20/90
Precisión VS Recall
Está claro que recall nos da información sobre el rendimiento de un clasificador con respecto a falsos negativos (cuántos fallaron), mientras que la precisión nos proporciona información sobre su rendimiento con respecto a los falsos positivos (cuántos capturados).
Precisión trata de ser preciso. Entonces, incluso si logramos capturar solo un caso de cáncer y lo capturamos correctamente, entonces somos 100% precisos.
Recall no se trata tanto de capturar casos correctamente sino más de capturar todos los casos que tener “cáncer” con la respuesta como “cáncer”. Entonces, si siempre decimos cada caso como “cáncer”, tenemos un recall del 100%.
Entonces, básicamente, si queremos enfocarnos más en minimizar los falsos negativos, deseamos que nuestro recall sea lo más cercano posible al 100% sin la precisión es muy mala y si queremos enfocarnos en minimizar los falsos positivos, entonces nuestro enfoque debe orientarse a hacer que la Precisión sea lo más cercana posible al 100%.
Especificidad o TNR (Tasa Negativa Verdadera)
Es el número de ítems correctamente identificados como negativos fuera del total de negativos.

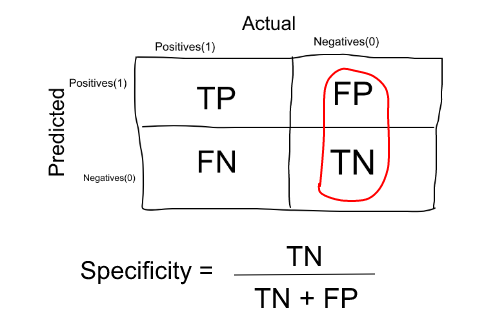
Entonces, para nuestro ejemplo: Precisión = 70 / (200 + 70) = 70/270.
La especificidad es exactamente lo opuesto a Recall.
Otras dos matrices que casi nunca se usan son:
1. Tasa de falso positivo o Error tipo I: Número de elementos identificados erróneamente como positivos de total negativos verdaderos- FP / ( FP + TN)
2. Tasa falso negativo o error de tipo II: Número de elementos identificados erróneamente como s negativo del total de verdaderos positivos: FN / (FN + TP)
Ejemplo: En el ejemplo de detección de cáncer, consideremos que contiene 100 personas, solo 5 personas tienen cáncer. Predicemos que todos los pacientes tienen cáncer:
Entonces, TP=5, FP=95 and TN=FN=0
Precision = 5/(5+95)=5%
Recall = 5/(5+0)=100%
Specificity=0/(0+5) =0%

Puntuación F1
Siempre es mejor establecer como científico de datos una métrica de evaluación de un solo número para que su equipo luego optimice.
La precisión es un ejemplo de una métrica de evaluación de un solo número y le permite comparar rápidamente dos clasificadores.
Si el clasificador A obtiene el 97% de precisión y el clasificador B obtiene el 90% de precisión, juzgamos que el clasificador A es superior.
Por el contrario, precisión y recall no es una medida de evaluación de un solo número: da dos 2 números para evaluar su clasificador.
Suponga que sus algoritmos funcionan de la siguiente manera:
Recordatorio de precisión del clasificador A 95% 90% B 98% 85%, ninguno de los clasificadores es obviamente superior, por lo que no lo guiará inmediatamente hacia la selección de uno.
Es mejor si podemos obtener una sola puntuación que representa tanto Precisión (P) como recall (R).
Una forma de hacerlo es simplemente tomar su media aritmética. es decir, (P + R) / 2 donde P es Precisión y R es Recall. Pero eso es bastante malo en algunas situaciones.
Veamos un ejemplo
Supongamos que en nuestro modelo de Machine Learning tenemos 100 transacciones con tarjeta de crédito, de las cuales 97 son legítimas y 3 son fraude y digamos que surgió un modelo que predice todo como fraude. (Horrible, verdad!?)
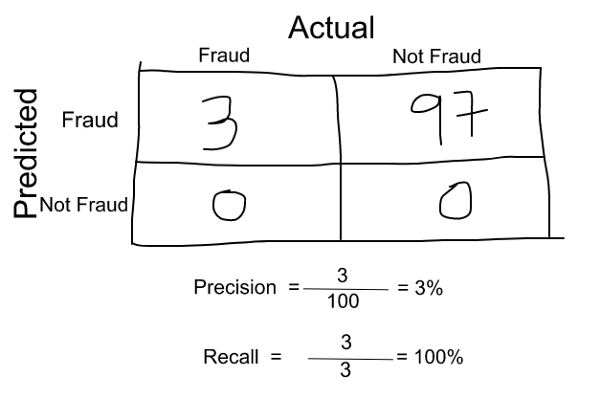
Precisión y recall para el ejemplo se muestra en la figura siguiente.
 Ahora, si simplemente tomamos la media aritmética de ambos, entonces sale casi el 51%.
Ahora, si simplemente tomamos la media aritmética de ambos, entonces sale casi el 51%.No deberíamos dar un puntaje tan moderado a un modelo terrible ya que solo está prediciendo cada transacción como fraude.
Entonces, necesitamos algo más equilibrado que la media aritmética y eso es una media armónica.

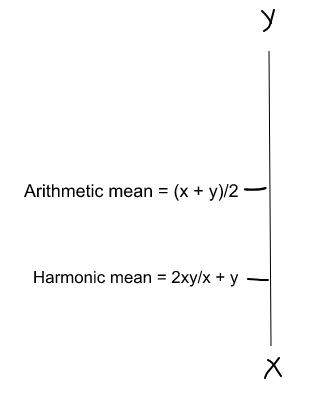
Para nuestro ejemplo anterior, F1 Score = Harmonic Mean(Precision, Recall)
F1 Score = 2 * Precision * Recall / (Precision + Recall) = 2*3*100/103 = 5%
Entonces, si un número es realmente pequeño entre la precisión y el recall.
El puntaje F1 levanta una bandera y está más cerca del número más pequeño que el más grande, dando al modelo un puntaje apropiado en lugar de solo una media aritmética.
La media armónica es una especie de promedio cuando xey son iguales. Pero cuando xey son diferentes, entonces está más cerca del número más pequeño en comparación con el número más grande.
Cómo calcular la precisión / recall para la clasificación multiclase en Machine Learning?
Los valores reales están representados por columnas. Los valores predichos están representados por filas. La matriz de confusión es para el dataset MNIST .

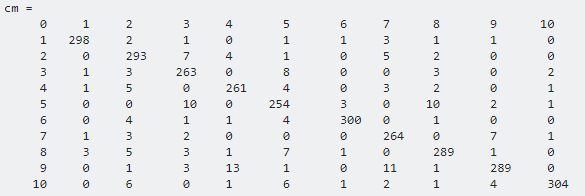
Para la clase x:
- Verdadero positivo: posición diagonal, cm (x, x).
- Falso positivo : suma de la columna x (sin diagonal principal), suma (cm (:, x)) – cm (x, x).
- Falso negativo: suma de la fila x (sin diagonal principal), suma (cm (x, :), 2) -cm (x, x).
Para encontrar un valor para todo el modelo:
- Calcule precision, recall y F1 score siguiendo la fórmula anterior para cada clase
- Promedio general clases (con o sin ponderación).
Mensaje para llevar a casa
Ahora sabemos que la próxima vez que escuche a alguien hablar sobre precisión o precisión del 99%, sabrá que debe consultarle sobre las demás métricas que discutimos en esta publicación.
Si te gusto este artículo también puedes leer otros dos temas interesantes de la Parte 1 y Parte 2 que incursiona en las Métricas de regresión (MSE)
Gracias por leer y yo estoy esperando para escuchar sus preguntas:)
Esté atento y Feliz Machine Learning!.
PD Si quiere aprender más sobre el mundo del Machine Learning, también puede seguirme en Instagram , encuéntreme en linkedin o en Facebook. Me encantaría saber de usted.