El aprendizaje automatico
En este post sobre el aprendizaje automatico, veremos sus diferentes tipos y también cuándo y dónde se utilizan.
Términos comunes utilizados:
- Datos etiquetados: Debe constar de un conjunto de datos, un ejemplo incluiría todas las imágenes de gatos o perros en una carpeta, todos los precios de la casa según el tamaño, etc.
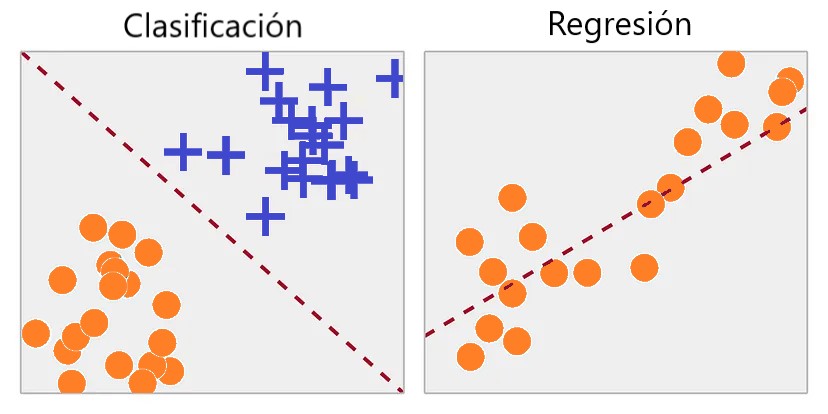
- Clasificación: Separación en grupos con valores definidos, por ejemplo, 0 o 1, gato o perro o naranja, etc.
- Regresión: Estimación de los valores o relaciones más probables entre las variables. P.ej. estimación del precio de la casa según el tamaño.
- Asociación: Descubrir relaciones interesantes entre variables en grandes bases de datos donde la conexión encontrada es crucial.
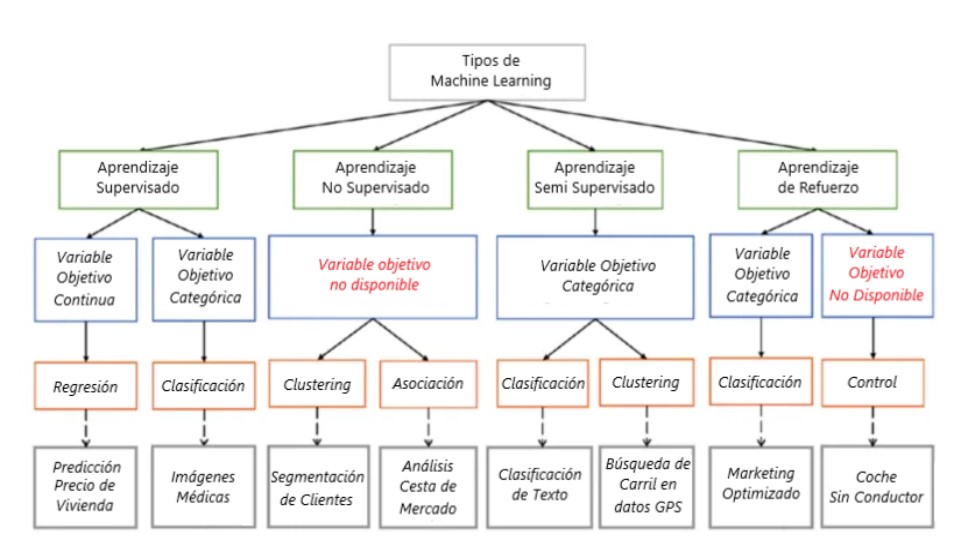
En el aprendizaje automatico hay cuatro tipos de (algunos podrían decir tres, aquí iremos con cuatro “ más, mejor, ¡¡bien! “).
El aprendizaje automatico y sus tipos
1. El aprendizaje automatico Supervisado
” El resultado o salida de la entrada dada se conoce antes que ella misma” y la máquina debe poder mapear o asignar la entrada dada a la salida. Varias imágenes de un gato, un perro, una naranja, una manzana, etc. aquí las imágenes están etiquetadas.
Se introduce en la máquina para entrenamiento y la máquina debe identificarlo. Así como a un niño humano se le muestra un gato y se lo dice, cuando ve un gato completamente diferente entre otros todavía lo identifica como un gato, aquí se emplea el mismo método.

Puntos clave:
- Aquí se resuelven principalmente los problemas de regresión y clasificación.
- Aquí se utilizan datos etiquetados para el entrenamiento.
- Algoritmos populares: regresión lineal, máquinas de vectores de soporte (SVM), redes neuronales, árboles de decisión, Naive Bayes, vecino más cercano.
- Se utiliza principalmente en el modelado de predicción .
2. El aprendizaje automatico No Supervisado
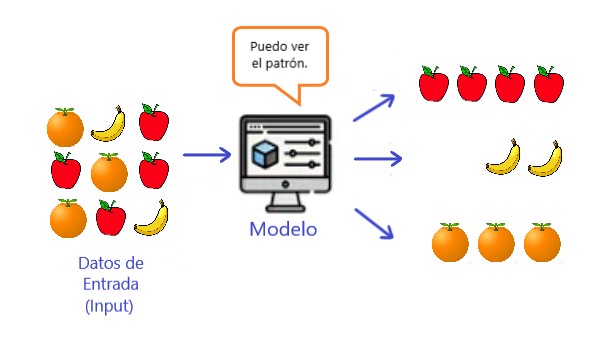
“Se desconoce el resultado o resultado de las entradas dadas”, aquí se proporcionan los datos de entrada y se ejecuta el modelo en ellos.
La imagen o la entrada proporcionada se agrupan aquí y se pueden encontrar ideas sobre las entradas aquí (que es la mayor parte de los datos disponibles del mundo real). Los principales algoritmos incluyen algoritmos de agrupamiento() o Clustering algorithms( ) y algoritmos en el aprendizaje automatico.
Puntos clave:
- Se utiliza para problemas de agrupación (agrupación), detección de anomalías (en bancos para transacciones inusuales) donde es necesario encontrar relaciones entre los datos proporcionados.
- Los datos sin etiquetar se utilizan en el aprendizaje no supervisado.
- Algoritmos populares: agrupación de k-medias, regla de asociación.
- Se utiliza principalmente en modelado descriptivo.
3. El aprendizaje automatico Semi Supervisado
Está entre el aprendizaje automatico supervisado y el no supervisado . Donde la combinación se utiliza para producir los resultados deseados y es la más importante en escenarios del mundo real donde todos los datos disponibles son una combinación de datos etiquetados y no etiquetados .
4. Machine Learning Reforzado
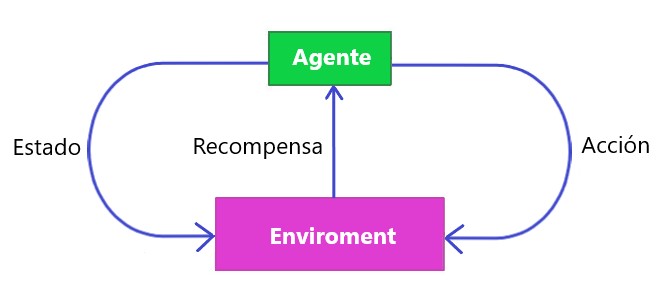
la máquina está expuesta a un entorno donde se entrena mediante el método de prueba y error , aquí se entrena para tomar una decisión muy específica. La máquina aprende de experiencias pasadas e intenta capturar el mejor conocimiento posible para tomar decisiones precisas basadas en la retroalimentación recibida.
Puntos clave:
- El refuerzo básico se modela como el proceso de decisión de Markov.
- El algoritmo más popular utilizado aquí es Q-Learning , Deep Adversarial Networks.
- Sus aplicaciones prácticas incluyen juegos de mesa en la computadora, como ajedrez y GO . Los autos autónomos también utilizan este aprendizaje.
Para resumir lo anterior, vea la imagen a continuación:
Asegúrate de seguirme en linkedin , twitter e Instagram para obtener más actualizaciones. Y además, si te gustó este artículo, asegúrate de aplaudir y compartirlo.





