Los algoritmos de Machine Learning ai se usan generalmente para muchas cosas diferentes, como detección de fraudes, reconocimiento de imágenes, reconocimiento de voz, recomendaciones de video, automóviles auto-conducidos, detección de spam, enseñar a una computadora a cocinar o jugar ajedrez y mucho más.
Hay muchos beneficios de Machine Learning ai, uno de los cuales es que no es difícil de aprender. Así como tenemos seres humanos, que se comunican utilizando diferentes formas de comunicación como expresiones faciales, gestos, tono de voz, ritmo. También tenemos computadoras que se comunican utilizando datos.
Una gran diferencia entre ambos es que el ser humano aprende de las experiencias pasadas y la computadora necesita que la gente les brinde la información, lo que implica que la enseñanza de la computadora corresponde a la programación.
Machine Learning ai es un nuevo concepto que enseña a las computadoras a aprender como seres humanos. Efectuar tareas a partir de experiencias pasadas.
En este post, exploraremos algunos algoritmos de Machine Learning ai y ejemplos diferentes en los que la computadora aprende de la información (o datos). Así que vamos a sumergirnos.
Algoritmos de Machine Learning ai: Árbol de decisiones.
Digamos que eres vendedor de autos y quieres recomendar autos, aquí E-Porsche, BMW i8 y Mercedes EQS, a tus clientes:

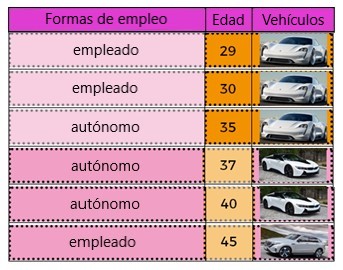
Tener información diversa sobre los clientes, como la edad y las formas de empleo (trabajadores por cuenta propia (autónomos) o empleados). Todos los datos se enumeran en la siguiente tabla:
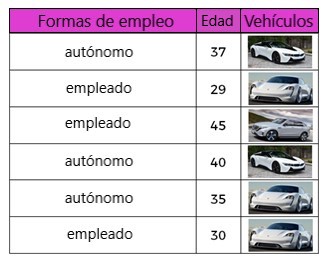
Por ejemplo, en la segunda fila de la tabla, tenemos un cliente que tiene 29 años, está empleado y tiene un E-Porsche. Con los datos proporcionados, la tarea aquí es predecir qué automóvil debe recomendarse al cliente basándose en el empleo o la edad del cliente.
Observando las diferentes formas de empleo y separándolos, tanto para los trabajadores autónomos como para los empleados. propio E-Porsche, que no es adecuado para una división:
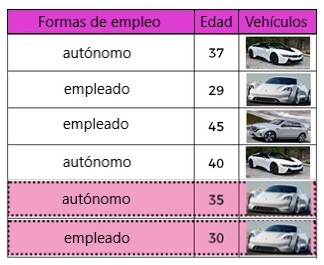
En otro caso, podemos dividir usando la antigüedad de la característica. Al observar los datos de “edad”, los clientes menores de 35 años poseen el auto Mission-E y las personas mayores de 35 años poseen las otras categorías de automóviles.
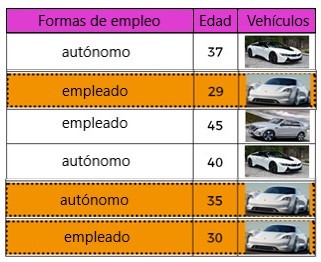
La función que mejor separa los datos es por edad:
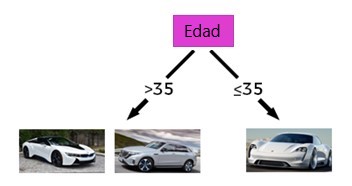
Una vez nos hemos separado por edad, podemos continuar con la función de empleo.
Al separar las funciones, ahora podemos recomendar clientes, menores de 35 años y trabajadores por cuenta propia, el i8 y si el cliente es mayor de 35 años y tiene un Empleador, podemos recomendar el coche EQS. Este método se denomina árbol de decisiones.
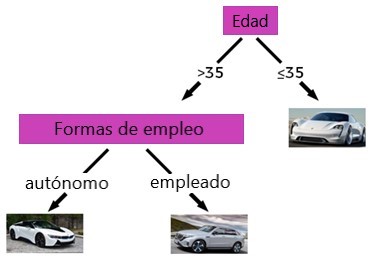
Las decisiones surgen de las preguntas que se hacen. ¿Cuántos años tiene el cliente? ¿Es autónomo o empleado? Si hay un nuevo cliente, podemos usar el árbol de decisiones y recomendarle un automóvil. Si el nuevo cliente es menor de 35 años, le recomendamos la Misión-E.
Este método puede funcionar con características categóricas y numéricas y es fácil de entender. Proporciona una buena interpretación para la representación visual. Vamos a pasar al siguiente método. El siguiente método nos ayudará a filtrar los datos.
Algoritmos de Machine Learning ai: Naive Bayes.
Otro método de Machine Learning ai es Naive Bayes, que es una técnica de clasificación. Es un modelo probabilístico de Machine Learning ai. Funciona bien para tareas como el spam y la clasificación de documentos. Un ejemplo popular con este método es el filtrado de spam.
Lo utilizaremos como clasificador para detectar correos electrónicos no deseados de correos no deseados. ¿Cómo funciona? Para esta tarea, tenemos que echar un vistazo a los datos que ya hemos recibido.
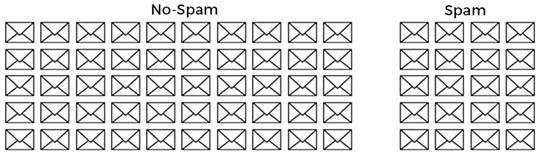
El conjunto de datos contiene 50 correos no deseados y 20 correos no deseados, que se han etiquetado manualmente. Esto hace un total de 70 correos electrónicos:
Definamos y analizamos algunas características que pueden hacer que un correo electrónico sea spam. Por ejemplo, una característica puede ser un correo electrónico sin un asunto.
Ahora analizamos al menos 70 correos electrónicos y encontramos que 4 de cada 50 correos electrónicos no spam y 10 de 20 correos electrónicos no deseados son correos electrónicos sin un asunto:

Con los datos registrados, intentaremos encontrar la probabilidad de que un correo electrónico sin un tema es el spam. Podemos ver que, de nuestros correos electrónicos sin un asunto, cuatro son correos electrónicos no spam, mientras que diez son correos electrónicos no deseados.
Esto nos da la siguiente respuesta:

71,43% es la probabilidad de que un correo electrónico sin un tema sea spam.
Luego podemos etiquetar los correos electrónicos futuros como no spam o spam utilizando la regla de que si se recibe un correo electrónico sin objeto, la probabilidad de que ese correo electrónico sea spam es del 71,43% y clasifica un correo electrónico como spam o no.
Mediante el uso de otras funciones, como la frase que contiene “Eres el gran ganador” o “Reclama tu oferta”. Luego podemos combinar todas las características para clasificar el correo electrónico. Este algoritmo se llama el clasificador Naïve Bayes.
El método también se utiliza para la recomendación, análisis de sentimiento. Se puede implementar fácilmente. El siguiente método que veremos también es simple y es muy adecuado para el análisis de grandes cantidades de datos.
Algoritmos de Machine Learning ai: K-means Clustering.
K-Means es uno de los más algoritmos de Machine Learning ai mas comúnmente utilizados para agrupar objetos (análisis de agrupamiento). Tenemos bicicletas y queremos usarlas para nuestro Sistema de Alquiler de Bicicletas.
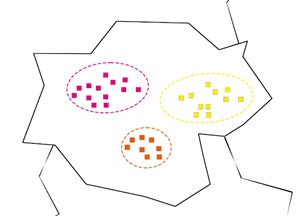
Para este propósito, decidimos colocar tres estaciones de alquiler de bicicletas en un distrito. Estamos haciendo un estudio de un área y encontramos que las personas que viajan más con bicicletas viven en apartamentos, como en el siguiente mapa.
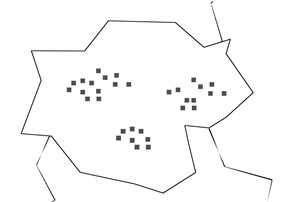
Parece más correcto con esta disposición colocar cada estación en un grupo. porque los apartamentos están cerca uno del otro.
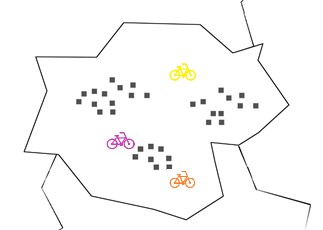
Sin embargo, como dijimos al principio, el hecho es que a la computadora se le debe enseñar cómo hacer una tarea. Eso significa que no sabe cómo hacer esto en este punto.
En este caso, necesitamos usar un nuevo método para encontrar una buena ubicación. Primero colocamos al azar tres estaciones, donde las bicicletas están en la imagen.
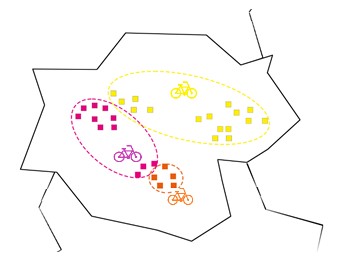
Después de colocar las estaciones, esperamos que la gente alquile bicicletas en las estaciones más cercanas. Dicho esto, los que están cerca de la estación naranja con alquiler de apartamentos en naranja. Los que están cerca de la estación rosa con alquiler de rosa y los que están cerca de la estación amarilla se alquilarán de amarillo.
Pero si miramos la distancia de los habitantes en En los apartamentos amarillos de la estación amarilla, nos damos cuenta de que tiene más sentido colocar la estación en el centro de los apartamentos amarillos y repetir este paso para la estación rosa y amarilla.
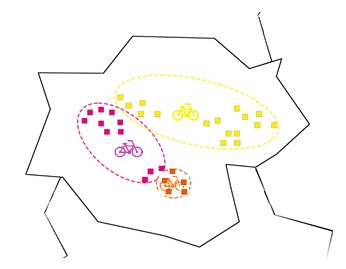
Simplemente cambiando las ubicaciones de las estaciones, Ahora puede reorganizar los apartamentos a sus estaciones más cercanas. Al observar los tres apartamentos al lado de los cinco apartamentos de color naranja.
Podemos ver que están más cerca de la estación de color naranja que de la estación de color rosa, marcamos los de color naranja y hacemos lo mismo con los dos de color amarillo que están al lado del los rosados.

Al mover la estación rosa al centro de sus clientes, encontramos que los tres apartamentos amarillos están más cerca de las estaciones rosadas que de la estación amarilla, por lo que los coloreamos como rosa.

Estación amarilla al centro de los apartamentos amarillos, ya que están más cerca de esta estación.

Este método se llama k-means. Si sabemos cuántos clusters queremos tener al final, entonces podemos usar k-means. Si no tenemos idea de cuántos clústeres, queremos tener. Hay otro algoritmo para eso, llamado agrupación jerárquica.
Agrupación jerárquica
Sin especificar el número de grupos o agrupaciones, agrupaciones, agrupación jerárquica es otro método que se puede utilizar para agrupar los apartamentos o Edificio en el barrio.
Con esta ubicación de apartamentos en un distrito, tendría sentido decir que si dos apartamentos están cerca, entonces los habitantes de los apartamentos pueden alquilar bicicletas en la misma estación. Con esta regla, podemos agrupar los apartamentos de la siguiente manera:
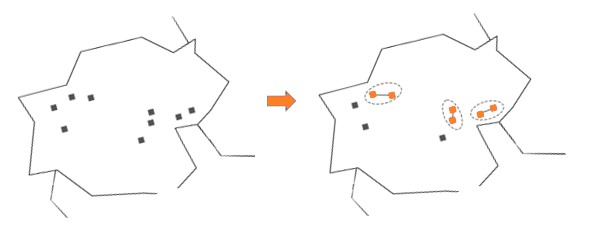
Luego, agrupamos los dos apartamentos más cercanos:
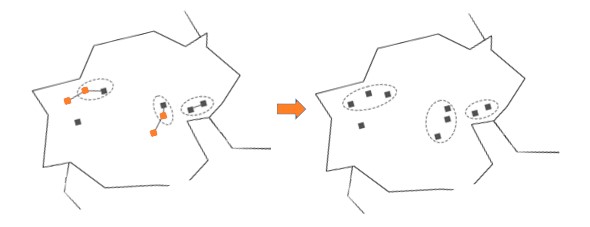
Repetimos el paso anterior, y tendremos el siguiente:
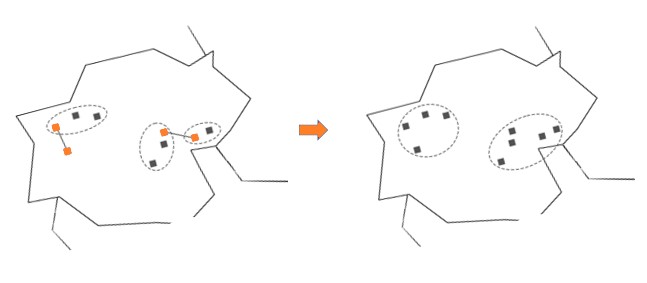
Luego, los apartamentos cercanos más cercanos posibles son los Imágenes marcadas en la imagen. Pero están un poco alejados el uno del otro:
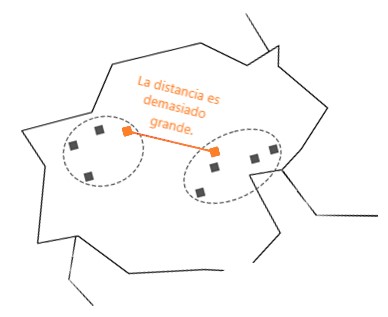
Si la distancia alcanza una cierta longitud, la ejecución del algoritmo se detiene. Este método se denomina agrupación jerárquica y se usa si no sabemos el número de agrupaciones que queremos tener, pero tenemos una idea de cómo debería ser.
Regresión lineal
En este ejemplo, tratamos de estimar los precios de un automóvil según su tamaño en longitud x ancho x alto (LxWxH):

Para ello, hacemos un pequeño estudio. A través de este pequeño estudio, tenemos tres coches. El más pequeño tiene un costo de 15,000 $USD y el auto más grande cuesta 45,000 $USD. Ahora queremos estimar el precio de un automóvil que tiene un tamaño entre los dos automóviles:

Para este propósito, ordenamos los automóviles en una cuadrícula, donde el eje x corresponde al tamaño de los automóviles y la y- Eje al precio de los coches.
Para hacer la tarea un poco más fácil, usamos datos que previamente habíamos registrado en otros autos. Estos están representados por estos puntos violetas.
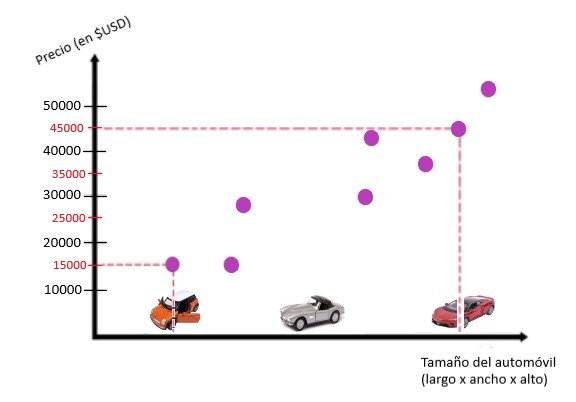
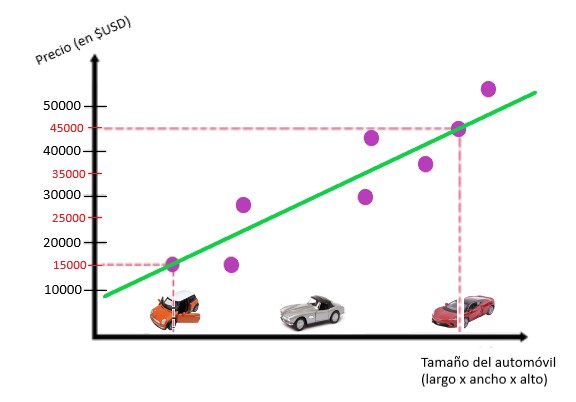
Podemos ver que estos puntos pueden formar una línea. Luego, dibujamos la línea que mejor se adapta a estos puntos violetas:
Con la ayuda de la línea podemos estimar el precio del auto en el medio, y esto corresponde a 30.000 $USD:
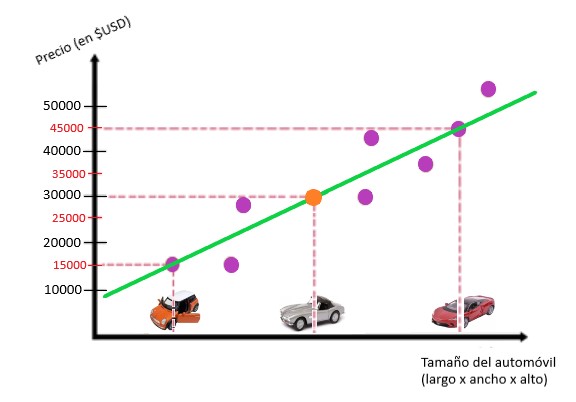
Este método se llama regresión lineal. Para encontrar la línea verde de arriba, que mejor se ajuste a los datos, usamos un método diferente llamado descenso de gradiente. Hagamos una breve parada y hablemos sobre este método.
Pendiente de descenso
Supongamos que estamos en la cima de una montaña y necesitamos encontrar la distancia más corta al pie de la montaña:
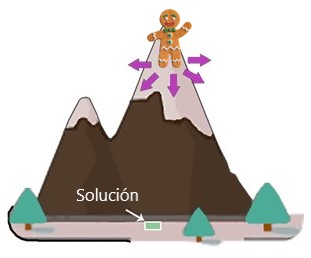
Podemos llegar al pie de la montaña paso a paso. Primero necesitamos encontrar la dirección apropiada que nos permita bajar más la montaña. Luego nos movemos en esa dirección:
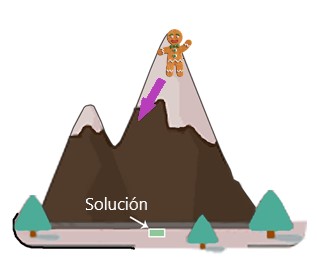
Después de eso, repetimos este proceso y damos un paso en la dirección correcta:
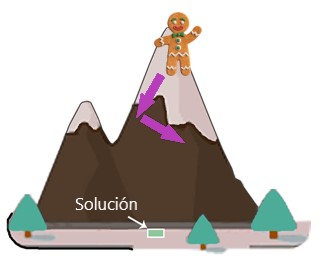
Repetimos la acción hasta que llegamos al pie de la montaña:
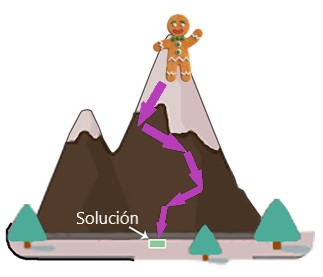
Este es el algoritmo de descenso de gradiente. Es uno de los algoritmos de Machine Learning ai muy utilizado en el aprendizaje automático. Para resolver nuestro problema de montaña, tomamos pequeños pasos en la dirección correcta hasta que alcancemos el pie de la montaña (la solución).
Regresión lineal – suite
Ahora retrocedemos hacia el método donde usamos una línea lineal para encontrar las mejores coincidencias de datos. Todavía estábamos en regresión lineal tratando de explicar cómo encontrar la línea que mejor coincida con los datos.
Intentemos con cuatro puntos y encontremos una línea que se adapte mejor a estos cuatro puntos. Como computadora, no sabemos cómo hacerlo, así que primero dibujamos una línea por casualidad:

Ahora verificamos qué tan buena o mala es la que mejor se adapta a los datos. Esto se hace calculando el error. Para ello, calculamos la distancia de los cuatro puntos a la línea recta. Y luego agregamos estas distancias para obtener el error:
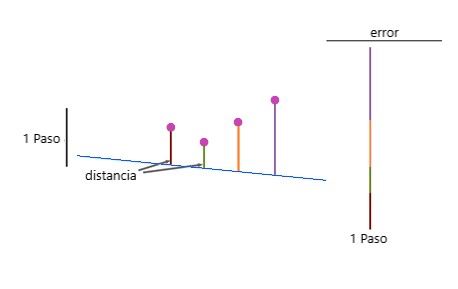
Luego, movemos la línea en una dirección diferente, calculamos el error y vemos que el error se ha reducido:
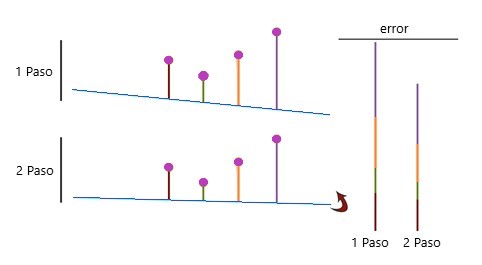
Tomamos este paso, repetimos el proceso y minimizamos el error hasta que encontremos una buena solución:
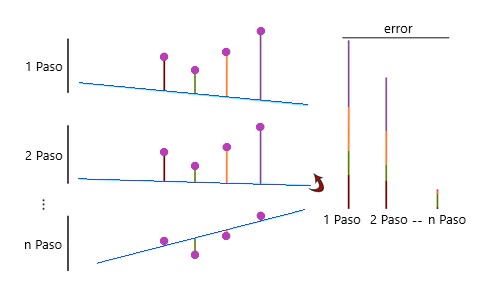
Este proceso de minimización del error se realiza mediante el descenso del degradado. Cuando estamos en la cima de la montaña, tenemos un gran error. Cada paso que tomamos en la dirección correcta, minimizamos el error.
En ejemplos reales, no queremos trabajar con distancias negativas, por lo que usamos el cuadrado en su lugar. Esto se denomina método de mínimos cuadrados.
Regresión logística
Para este ejemplo, recibimos la tarea de clasificar tumores cerebrales benignos y malignos.
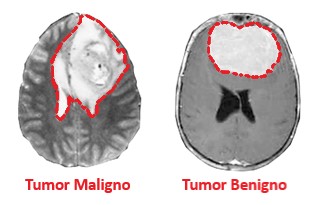
Básicamente, tumores cerebrales benignos pueden distinguirse de los tumores cerebrales malignos con las características que generalmente crecen lentamente (y dañan el tejido circundante principalmente al aumentar la presión) y tienen menos probabilidades de recurrir que los tumores malignos, que crecen rápidamente con la capacidad de invadir el tejido sano.
Aquí usaremos estas dos características, la velocidad de crecimiento y el grado de recurrencia del tumor para clasificar esos dos tipos de tumores cerebrales.
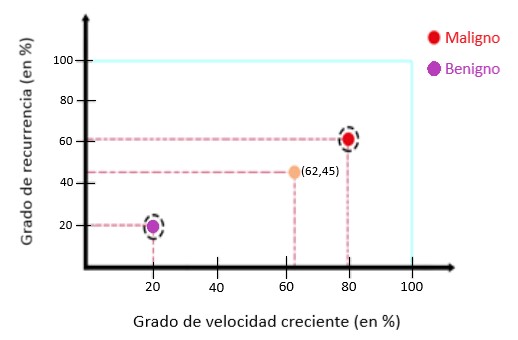
En este ejemplo, hemos registrado algunos datos con los parámetros, por ejemplo. grado de velocidad de crecimiento del 20%, grado de recurrencia del 20% para los datos x, que es un tumor benigno.
Para los datos y, tenemos un grado de velocidad de crecimiento del 79%, grado de recurrencia del 61%, que es un tumor maligno. Ahora tenemos nuevos datos, con un grado de velocidad de crecimiento del 62%, grado de recurrencia del 45%.
Los colores definen la etiqueta de clase a la que pertenece cada instancia. Con los datos que tenemos, queremos determinar qué tipo de tumor es.
Para este propósito, organizamos los datos en una cuadrícula, donde el eje x corresponde a la velocidad de crecimiento y el eje y al grado de recurrencia:
Utilizamos datos previamente registrados de tumores malignos y benignos:
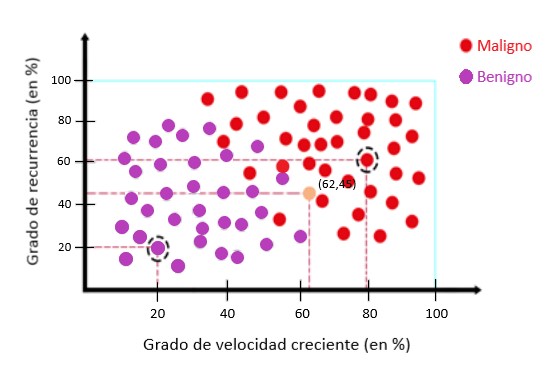
Mirando más de cerca los puntos, podemos ver que los puntos se pueden separar con una línea. Esta línea es el modelo:
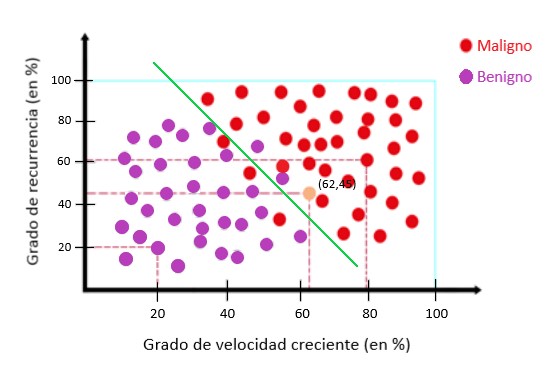
La mayoría de los puntos rojos están por encima de la línea verde y la mayoría de los puntos violetas están por debajo de la línea. Cada vez que tengamos un nuevo punto, podremos asignarlo a un tipo de tumor utilizando el modelo.
Los datos sobre la línea son los tumores malignos y los datos debajo de la línea son los tumores benignos. Para los nuevos datos con las coordenadas podemos decir que este tumor es maligno. Este método se llama regresión logística.
Al igual que con la regresión lineal, examinamos el método para encontrar esta línea que separa los datos. Tomemos un ejemplo simple e intentemos encontrar la línea que mejor separa los datos, los puntos rojos de los puntos violetas.
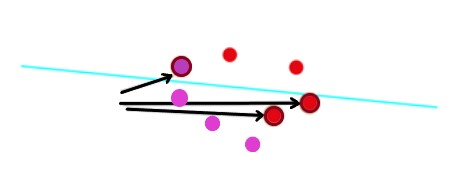
En nuestro ejemplo, tenemos dos puntos rojos y un punto violeta, que significa tres errores. Intentamos minimizar el error utilizando el descenso de gradiente. Si movemos la línea en la dirección correcta, podemos ver que el error está minimizado:
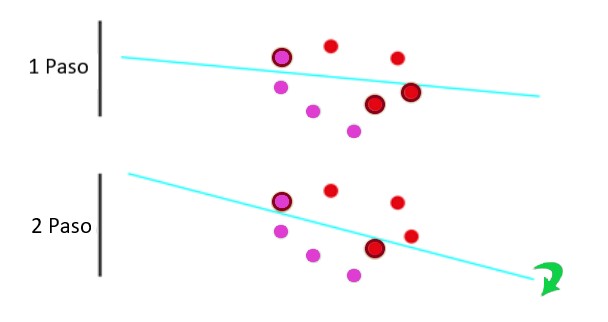
Ahora solo tenemos dos errores. Y luego repetimos el proceso hasta que no tengamos más errores:
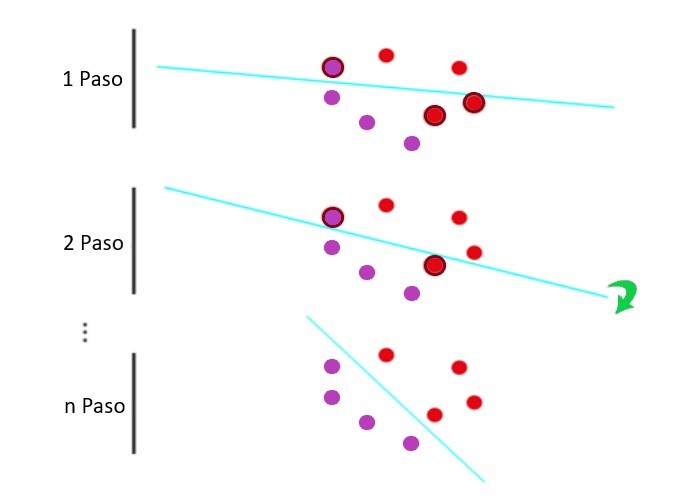
Con ejemplos reales, no intentamos minimizar el error, sino que utilizamos una función llamada función de pérdida de registro, que pesa el número de errores. Tenemos dos de ocho puntos que no están clasificados correctamente.
La función de pérdida de registro asignará una penalización grande a los puntos incorrectos y una penalización pequeña a los puntos correctos.
Agregamos todas las penalizaciones de los puntos respectivos para obtener la función de pérdida de registro. Para que esto quede más claro, hemos reemplazado esta multa por un número para una multa grande y para una multa pequeña. En el segundo paso, vemos que el error es mayor que en el siguiente:
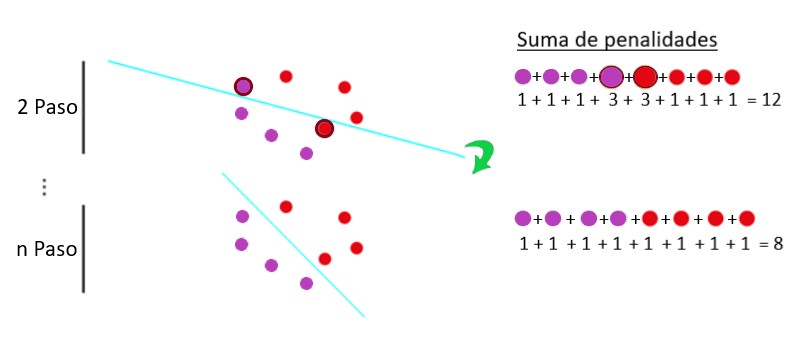
El procedimiento aquí es minimizar la función de error y encontrar la línea que mejor separa los datos.
Ahora sabemos un poco sobre los algoritmos de Machine Learning ai. Si desea seguir aprendiendo más sobre algoritmos de Machine Learning ai puede continuar leyendo la parte 2.