Aprendizaje automatizado: Algoritmos Parte 2

En la primera parte explicamos qué es Machine Learning y algunos algoritmos de aprendizaje automatizado. En esta nueva parte profundizaremos y veremos más métodos que pueden ayudarnos a enseñar a la máquina a realizar una tarea.
Aprendizaje automatizado: Algoritmo SVM (Máquina de vectores de soporte)
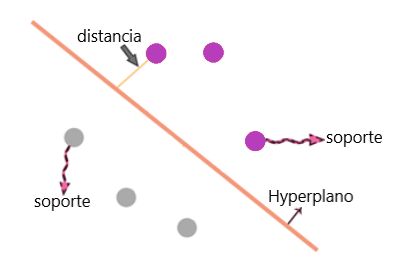
Ahora vemos otro método para pensar más. En el ejemplo, tenemos tres puntos violetas y tres grises separados por más de una línea:
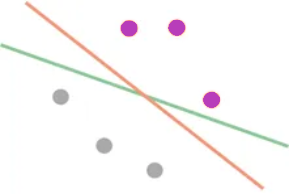
Ahora investigaremos cuál de las líneas se ajusta mejor a los datos:
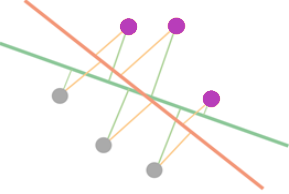
Podemos ver que la línea verde está muy cerca de los puntos , mientras que la línea naranja no está tan cerca de los puntos. La línea naranja parece estar lo suficientemente alejada de los puntos y así poder separarlos bien.
La línea naranja gana aquí sobre la línea verde. A partir de la regresión de registros, debemos explicar cómo encontrar la línea que mejor se ajuste a los puntos.
Debemos trabajar con las distancias desde los puntos hasta las líneas. Aquí podemos ver la distancia de cada punto a las líneas y encontramos que el mínimo debajo de estas distancias es la distancia a la distancia a la que se encuentra el punto respectivo de las líneas:
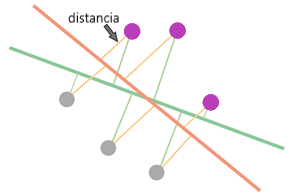
Al solo observar el mínimo de las seis distancias, podemos ignorar los puntos que están muy lejos de las líneas:
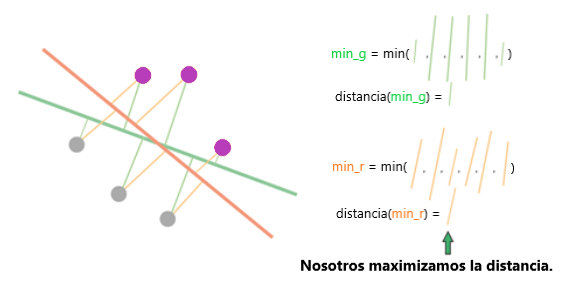
De esto, podemos concluir que la línea naranja separa mejor los datos, ya que el mínimo para la línea naranja es mayor que el mínimo de la línea verde. El objetivo aquí es maximizar las distancias utilizando el descenso del degradado como en los métodos anteriores.
El algoritmo se denomina máquina de vectores de soporte (SVM). Los vectores de soporte aquí son los puntos que están cerrados al hiperplano. La línea naranja es el hiperplano que segrega los puntos. La SVM se puede usar para tareas de clasificación.
Aprendizaje automatizado: Algoritmo de Redes neuronales
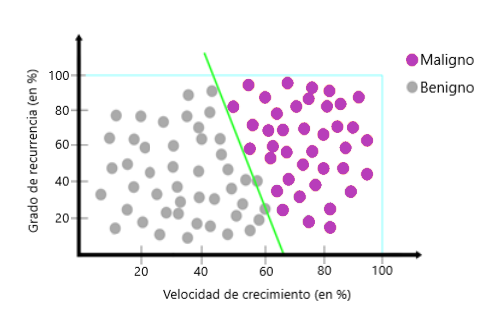
Aquí continuaremos con nuestros datos de tumores. Los datos ahora están ordenados como en la siguiente imagen. Es un modelo nuevo:
Algunas veces los datos se pueden organizar de la siguiente manera:
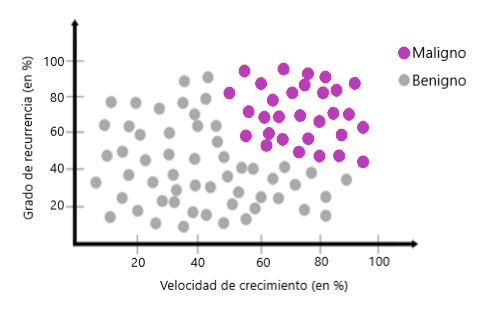
Desafortunadamente, en este caso, no podemos usar una línea para separar los datos:
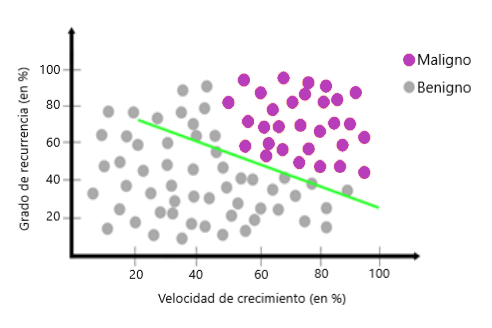
Podemos usar más de una línea o un círculo para separar los datos:
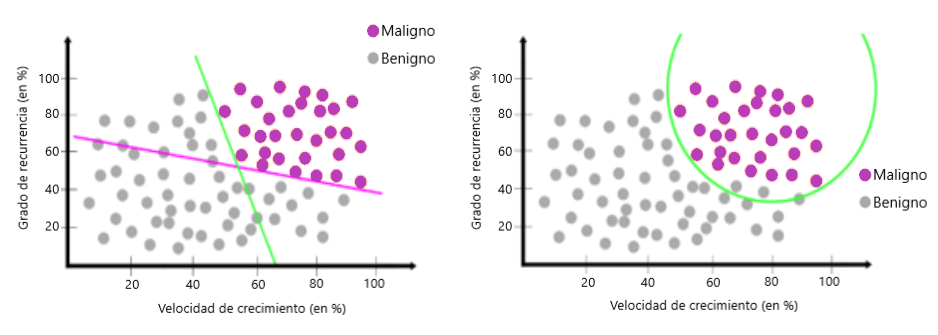
Al usar el descenso de degradado, podemos minimizar la función de error y encontrar estas líneas. Este método se llama red neuronal. El nombre proviene de la inspiración sobre cómo funciona el cerebro humano, especialmente cuando se realizan múltiples tareas. P.ej. un humano puede ir a la calle mientras manipula su teléfono celular (lo que podría ser peligroso).
Ahora digamos que tenemos una computadora con menos energía y que no puede hacer más de una tarea al mismo tiempo. Si queremos saber si un nuevo dato pertenece al tipo de tumor maligno, por ejemplo, tenemos que separar la gran tarea en muchas tareas pequeñas. La primera tarea o pregunta sería: ¿los nuevos datos sobre la línea púrpura?
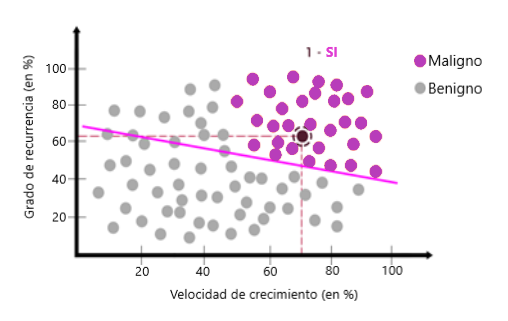
La respuesta es sí. La siguiente pregunta sería: ¿Son estos nuevos datos sobre la línea verde?
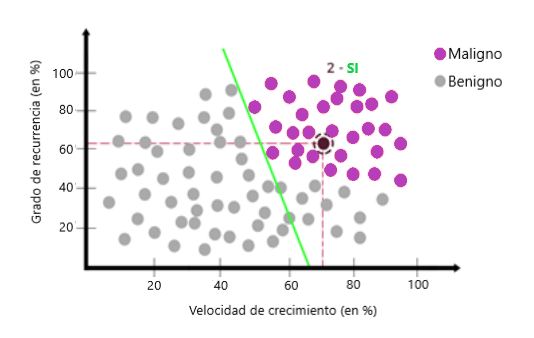
La respuesta también sería sí. Con las dos respuestas como sí, podemos concluir que los nuevos datos son un tumor maligno:
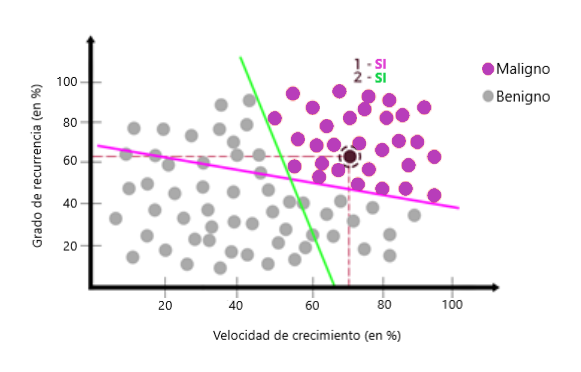
Por lo tanto, podemos completar las otras regiones con sí o no:
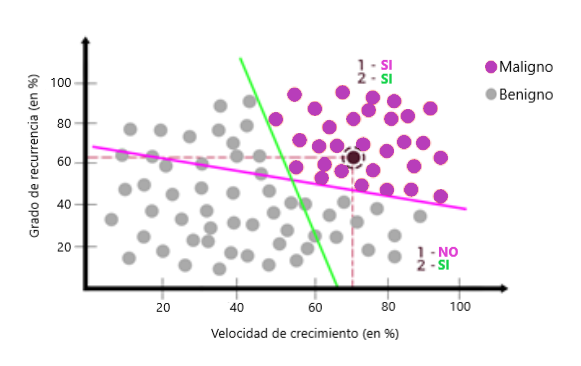
Entonces, el área en la parte inferior derecha tendría las respuestas 1- No / 2-sí. En el área superior izquierda, tendríamos 1-Sí / 2-No y, finalmente, en el área inferior izquierda, tendríamos 1-No / 2-No. Ahora podemos representar las tareas en un gráfico con nodos como:

Para este pequeño gráfico con nodos verdes, planteamos la pregunta, si los datos con coordenadas (grado de recurrencia = 70%, grado de velocidad de crecimiento = 20%) han terminado La línea verde o no, y la respuesta es no.
El mismo proceso se realiza con otro gráfico, donde la otra pregunta, si los datos con coordenadas (recurrencia grad = 70%, velocidad de crecimiento grad = 20%) está sobre la línea púrpura o no, y la respuesta es no.

Y para la siguiente pregunta, simplemente combinamos la salida de los dos gráficos anteriores a un nuevo nodo.

Esta combinación de dos valores se realiza mediante la lógica AND. Echemos un vistazo a este operador AND.

Toma dos entradas, Sí y No (o como números 0 y 1) y tiene una salida. Si ingresamos Sí y No (o 1 y 0), la salida sería No (o 0). Si las entradas son No y No (o 0 y 0), la salida sería No (o 0).
La combinación del nuevo nodo con los dos gráficos pequeños se llama red neuronal. En la red neuronal, primero tenemos la capa de entrada donde ingresamos el grado de recurrencia = 70% y el grado de velocidad de crecimiento = 20%.
Luego, la información sobre el graduado en la capa de entrada se reenvía a la capa intermedia. Desde el nodo en la capa media vienen las respuestas no y sí. Estos se reenvían a la capa de salida y serán evaluados por la lógica y, y la salida de la lógica y la red neuronal es un número

Se pueden agregar capas y nodos adicionales a esta red para resolver tareas más complejas

Este es un algoritmo de aprendizaje automatizado poderoso y excelente. Se usa en muchos proyectos como sistemas de asistencia al conductor, reconocimiento de escritura cursiva, detección de bombas en maletas utilizando TNA (Análisis de neutrones térmicos) y quizás en la lectura de la mente futura y muchos más.
Algoritmo de Método del kernel
En este nuevo ejemplo Veremos un nuevo método que puede transformar datos linealmente no separables en datos linealmente separables. Tenemos los puntos organizados de la siguiente manera.

En estos casos, no es posible usar una línea para separar los puntos.

Aquí tenemos que proceder de manera diferente. Podemos imaginar que los puntos se muestran en una cuadrícula y luego los separamos mediante una curva.

Del mismo modo, podemos imaginar que los puntos están en el espacio y usar un plan para separarlos. Para ello añadimos un eje adicional, el eje z.
Luego, los dos puntos rojos se mueven a través del eje z al hacer coincidir las coordenadas (x, y) de los puntos en 2D con las coordenadas (x, y, z) en 3D, donde z puede ser una ecuación que depende de x o y como x³y , x + y²,… Posteriormente, podremos separar los puntos usando un plan.

Los dos trucos son los mismos. Este enfoque se utiliza principalmente en la máquina de vectores de soporte y se denomina truco del núcleo. Continuaremos aquí con los puntos dispuestos como en (a) y la curva como separador. Para separar los puntos, trabajaremos con algunas ecuaciones que podrían ayudarnos a separar los puntos. Tenemos xy, x + y, x², x³.
Las coordenadas de los puntos se aplican en las ecuaciones. Las salidas nos darán más información sobre qué tan bien las ecuaciones o funciones pueden separar los puntos. Usamos una tabla para mostrar los resultados.

La primera línea corresponde a las coordenadas de los puntos (de izquierda a derecha) y la primera columna contiene las ecuaciones. Podemos ver todos los resultados en la tabla. P.ej. para (4,0) en x³, que hace 5x5x5 = 125, para (1,3) en x + y, tenemos 1 + 3 = 4.
Ahora la pregunta es, qué ecuación separa los puntos. Primero, tenemos x + y. Podemos ver que las coordenadas de dos puntos azules y dos puntos rojos tienen los mismos resultados, 4.
Por lo tanto, la ecuación no puede separar los puntos. Para x² y x³, se puede ver que hay diferentes resultados para los puntos azul y rojo y que los valores de los puntos rojos están entre los valores de los puntos azules. Por lo tanto, estas ecuaciones tampoco pueden separar los puntos.
Finalmente, tenemos xy y notamos que los puntos azules tienen el mismo valor 0 y los puntos rojos tienen el mismo valor 3. La función puede separar los puntos porque nos da un valor único para los puntos rojos y otro valor único para los puntos rojos. puntos azules.
Tenemos xy = 0 para los puntos azules y xy = 3 para los puntos rojos. Sabemos que 1 y 2 están entre y 0 y 3, por lo que 1 y 2 separan 0 y 3. Esto nos da las ecuaciones xy = 1 y xy = 2 y, por lo tanto, las funciones y = 1 / x y y = 2 / x.

De esto, concluimos que la función 1 / x (o 2 / x) separa los puntos en el plan.

Con el método, los datos no lineales se pueden asignar a una dimensión superior (n-dim ) espacio. En este nuevo espacio, los datos se pueden separar fácilmente mediante un plano o una curva. Este método se puede utilizar para el reconocimiento de escritura a mano, reconstrucción 3D, geoestadística y muchos más.
Aprendizaje automatizado: Conclusión
En este artículo, dividido en dos partes, hemos visto varios algoritmos importantes utilizados en el aprendizaje automatizado. El objetivo era explicarles los algoritmos de una manera simple usando varios ejemplos. Ahora llegamos al final de nuestra “inmersión fácil”.

Así que les deseo mucha diversión en el hermoso mundo del aprendizaje automatizado.





