Hoy usaremos XGBoost Boosted Trees para la regresión sobre el conjunto de datos oficial del índice de desarrollo humano. ¿Quién dijo que el aprendizaje automático era todo sobre la clasificación?
XGBoost: ¿Qué es?
XGBoost es un marco de Python que nos permite entrenar XGBoost Boosted Trees explotando el paralelismo de múltiples núcleos. También está disponible en R, aunque no lo cubriremos aquí.
La tarea: Regresión
Los árboles impulsados son un Modelo de aprendizaje automático para la regresión. Es decir, dado un conjunto de entradas y etiquetas numéricas, estimarán la función que genera la etiqueta con su entrada correspondiente.
Sin embargo, a diferencia de la clasificación, estamos interesados en valores continuos, y no en un conjunto discreto de clases, para el etiquetas.
Por ejemplo, podemos querer predecir la altura de una persona debido a su peso y edad, en lugar de, digamos, etiquetarla como hombre, mujer u otra.
Para cada árbol de decisión, comenzaremos por root, y muévete hacia la izquierda o hacia la derecha según el resultado de la decisión. Al final, devolveremos el valor en la hoja que alcanzamos.
Modelo de XGBoost Boosted Trees: ¿Qué son los árboles impulsados por degradado?
Los árboles reforzados son similares a los bosques aleatorios: son una amalgama de árboles de decisión. Sin embargo, cada hoja devolverá un número (o vector) en el espacio que estamos pronosticando.
Para la clasificación, generalmente devolveremos el promedio de las clases para los elementos del conjunto de entrenamiento que caen en cada hoja. En regresión, generalmente devolveremos el promedio de las etiquetas.
Sin embargo, en cada nodo no hoja, el árbol tomará una decisión: una comparación numérica entre el valor de una característica determinada y un umbral.
Hasta aquí, Esto solo sería un bosque de regresión. ¿Dónde está la diferencia?
XGBoost Boosted Trees vs Random Forest: la diferencia
Cuando entrenamos un XGBoost Boosted Tree, a diferencia de los bosques aleatorios, cambiamos las etiquetas cada vez que agregamos un nuevo árbol.
Para cada nuevo árbol, actualizamos las etiquetas restando la suma de las predicciones de los árboles anteriores, multiplicada por una cierta tasa de aprendizaje.
De esta manera, cada árbol aprenderá a corregir los errores de los árboles anteriores.
En consecuencia, en la fase de predicción, simplemente devolveremos la suma de las predicciones de todos los árboles, multiplicada por la velocidad de aprendizaje.
Esto también significa que, a diferencia de los bosques aleatorios o los árboles en bolsas, este modelo hará overfit si aumentamos la cantidad de árboles arbitrariamente. Sin embargo, aprenderemos a explicar esto.
Para obtener más información sobre XGBoost Boosted Trees, te recomiendo que leas los documentos oficiales de XGBoost . Me enseñaron mucho y explicaron los conceptos básicos mejor y con imágenes más bonitas.
Usar XGBoost Boosted Trees con Python
La API de XGBoost es bastante sencilla, pero también aprenderemos un poco acerca de sus hiperparámetros. En primer lugar, sin embargo, les mostraré la misión de hoy.
Conjunto de datos de hoy: Datos públicos de HDI
El Conjunto de datos de HDI contiene mucha información sobre el nivel de desarrollo de la mayoría de los países, analizando muchas métricas y áreas a lo largo de las décadas.
Para el artículo de hoy, decidí solo para ver los datos del último año disponible: 2017. Esto es solo para mantener las cosas recientes.
También tuve que realizar un poco de remodelación y limpieza de datos para hacer que el conjunto de datos original fuera más manejable y, en particular, consumible one.
El repositorio de GitHub para este artículo está disponible aquí y lo invito a seguirlo junto con el Cuaderno de Jupyter. Sin embargo, me gustaría agregar los fragmentos más relevantes aquí.
Preproceso de los datos con pandas
En primer lugar, leeremos el conjunto de datos en la memoria. Dado que contiene una columna completa para cada año y una fila para cada país y métrica, es bastante incómodo de administrar.
Lo reformularemos en algo como lo siguiente:
{country: {metric1: value1 , metric2: value2, etc.}
by country in countries}
Para que podamos incluirlo en nuestro modelo XGBoost. Además, como todas estas métricas son numéricas, no se necesitará más preprocesamiento antes del entrenamiento.
import pandas as pd import xgboost as xgb df = pd.read_csv("2018_all_indicators.csv") df = df [['dimension','indicator_name','iso3','country_name','2017']] df.shape # (25636, 5) df = df.dropna() # get rid of NaNs df.shape # (12728, 5) df.iso3.unique(). shape # 195 countries
Este fragmento de código elimina las filas que tienen un valor de NaN y también nos dice que tenemos 195 países diferentes.
Si alguna de estas operaciones es nueva para usted, o si tiene algún problema para seguir, intente leer mi introducción a pandas antes de continuar.
Para ver todos los indicadores disponibles (métricas) que proporciona el conjunto de datos, usaremos el método único.
df['indicator_name'].unique()
Hay muchos (97) de ellos, así que no los enumeraré aquí. Algunas se relacionan con la salud, otras con la educación, otras con la economía y otras con los derechos de las mujeres.
Pensé que lo más interesante para nuestra etiqueta sería la esperanza de vida, ya que creo que es una métrica bastante reveladora sobre una
Por supuesto, siéntase libre de probar este mismo código con una etiqueta diferente, ¡y pídame los resultados!
También de la enorme lista de indicadores, simplemente elegí unos pocos a mano que pensé se correlacionaría con nuestra etiqueta (o no), pero podríamos haber elegido otras.
Aquí está el código para convertir nuestro conjunto de datos de forma extraña en algo más aceptable.
def add_indicator_to (dictionary, indicator):
indicator_data = df [df['indicator_name'] == ind[icator]
zipped_values = zip (list (indicator_data ['iso3']), list (indicator_data ['2017']))
for k , v in zipped_values:
try:
dictionary [k][indicator] = v % held by women)',
'Infants lacking immunization, meals (% of one-year-olds)',
except:
print("failed with key:" + k + "en" + indicator)
indic = {}
indicators = [ 'Share of seats in parliament (% held by women)',
'Infants lacking immunization, measles (% of one-year-olds)',
'Youth unemployment rate (female to male ratio)',
'Expected years of schooling (years)', 'Expected years of schooling, female (years)',
'Expected years of schooling, male (years)', 'Unemployment, total (% of labor force)',
'Unemployment, youth (% ages 15–24)', 'Vulnerable employment (% of total employment)', ]
To indicator in indicators:
add_indicator_to (indicator, indicator)
Finalmente, después de convertir nuestro diccionario en un DataFrame, me di cuenta de que estaba transpuesto: sus columnas eran lo que deberían haber sido sus filas y viceversa. Así es como lo arreglé.
final_df = pd.DataFrame(indic).transpose()
Análisis de correlación de características
Supuse que las características que elegí serían buenas para la regresión, pero esa suposición se basó solo en mi intuición.
Así que decidí comprobar si se mantuvo. Estadística. Así es como hice una matriz de correlación.
import seaborn as sns
import matplotlib.pyplot as plt
% matplotlib inline fig = sns.heatmap(final_df.corr())
plt.title("correlation heatmap")
plt.tight_layout()
plt.savefig("correlation_heatmap", figsize = (96,72))
Y aquí está el resultado:
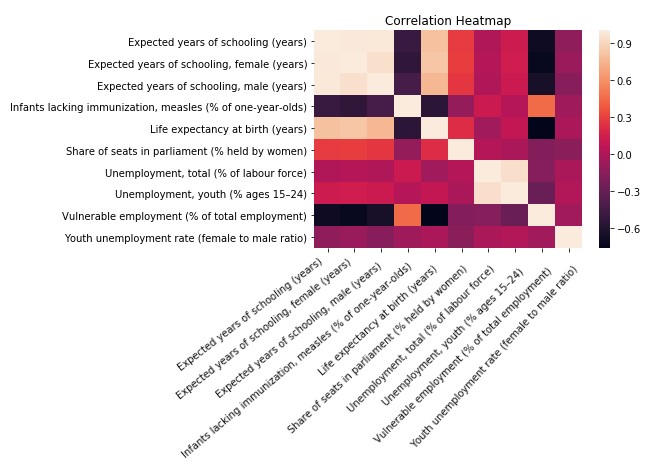
Como se esperaba, la esperanza de vida al nacer está altamente correlacionada con la vacunación (¡toma eso, anti-vaxxers!), Falta de empleo vulnerable, y educación.
Yo esperaría que el modelo usara estas mismas características (las que muestran las correlaciones más altas o más bajas) para predecir la etiqueta.
Afortunadamente, XGBoost incluso nos proporciona un método de importancia de feature_importance, para verificar qué El modelo está basando sus predicciones en.
Esta es una gran ventaja de XGBoost Boosted Trees sobre, por ejemplo, Neural Networks, donde explicar las decisiones de los modelos a alguien puede ser muy difícil, e incluso convencernos a nosotros mismos de que el modelo es razonable. difícil. Pero más sobre eso más adelante.
Entrenando el modelo XGBoost Boosted Trees
¡Finalmente es tiempo de entrenar! Después de todo ese procesamiento, esperarías que esta parte fuera complicada, ¿verdad? Pero no lo es, es solo una simple llamada de método.
Primero nos aseguraremos de que no haya superposición entre nuestros datos de entrenamiento y pruebas.
# The features we use to train the model obviously cannot contain the tag. train_features = [feature for feature in list(final_df) if feature != life_expec] train_df = final_df.iloc [:150][train_features] train_label = final_df.iloc [:150][life_expec] test_df = final_df.iloc [150:] [train_features] test_label = final_df.iloc [150:] [life_expec]
Y ahora, aquí está lo que has estado esperando. Este es el código para entrenar un modelo XGBoost.
import xgboost as xgb dtrain = xgb.DMatrix(train_df, label = train_label) dtest = xgb.DMatrix(test_df, label = test_label) # specify parameters via map param = {'max_depth': 6, 'eta': 1, # this is the default anyway 'colsample_bytree': 1 # this is the default anyway } num_round = 15 initial_trees = xgb.train(param, dtrain, num_round)
Notarás que el código para entrenar realmente al modelo y el que genera las predicciones son bastante simples. Sin embargo, antes de eso, hay un poco de configuración.
Esos valores que ve allí son los hiperparámetros del modelo, que especificarán ciertos comportamientos al entrenar o predecir.
XGBoost Hyperparameters Primer
max_depth se refiere a la profundidad máxima permitida para cada árbol en el conjunto. Si este parámetro es más grande, los árboles tienden a ser más complejos y, por lo general, se adaptarán más rápido (en igualdad de condiciones).
eta es nuestra tasa de aprendizaje. Como dije anteriormente, multiplicará la salida de cada árbol antes de ajustar el siguiente, y también la suma cuando haga predicciones después.
Cuando se establece en 1, el valor predeterminado, no hace nada. Si se configura en un número más pequeño, el modelo tardará más en converger, pero generalmente se ajustará mejor a los datos (posiblemente un ajuste excesivo). Se comporta de manera similar a la velocidad de aprendizaje de una red neuronal.
colsample_bytree se refiere a cuántas de las columnas estarán disponibles para cada árbol al generar las ramas.
Su valor predeterminado es 1, que significa “todas de ellos”. Potencialmente, podemos querer establecerlo en un valor más bajo, de modo que todos los árboles no puedan usar la mejor característica una y otra vez. De esta manera, el modelo se vuelve más robusto a los cambios en la distribución de datos y también se adapta menos.
Por último, num_rounds se refiere al número de rondas de capacitación: casos en los que verificamos si agregar un nuevo árbol . La capacitación también se detendrá si la función de destino no ha mejorado en muchas iteraciones.
Evaluando nuestros resultados
¡Ahora veamos si el modelo aprendió!
import math
def msesqrt(std, test_label, preds):
squared_errors = [diff*diff for diff in (test_label - preds)]
return math.sqrt(sum(squared_errors) / len(preds))
msesqrt(std, test_label, first_preds) #4.02
La esperanza de vida tenía una desviación estándar ligeramente superior a 7 en 2017 (verifiqué con la descripción de Pandas), por lo que una raíz cuadrada de MSE de 4 no es nada de qué reírse. El entrenamiento también fue súper rápido, aunque este pequeño conjunto de datos no aprovecha las capacidades de multinúcleo de XGBoost.
Sin embargo, siento que el modelo aún es inadecuado: eso significa que aún no ha alcanzado su máximo potencial. [19659009]
Ajuste del hiperparámetro: Iteremos
Como creemos que estamos mal equipados, intentemos permitir árboles más complejos (max_depth=6), reduciendo la tasa de aprendizaje ( eta = 0.1) y aumentando el número de rondas de entrenamiento a 40.
param = {'max_depth': 5,
'eta':. 1,
'colsample_bytree':. 75 }
num_round = 40
new_tree = xgb.train(param, dtrain, num_round)
# make prediction
new_preds = new_tree.predict(dtest)
Esta vez, utilizando la misma métrica, estoy muy contento con los resultados. ¡Hemos reducido la tasa de error en nuestro conjunto de pruebas a 3.15! Eso es menos de la mitad de la desviación estándar de nuestra etiqueta, y debe considerarse estadísticamente precisa.
Imagínese predecir la esperanza de vida de una persona con un margen de error de 3 años, según algunas estadísticas sobre su país.
(Por supuesto, esa interpretación sería errónea, ya que la desviación en la esperanza de vida dentro de un solo país definitivamente no es cero.)
Entendiendo las decisiones de XGBoost: Importancia de la característica
El modelo parece ser bastante preciso. Sin embargo, ¿en qué se basan sus decisiones?
Para ayudarnos, XGBoost nos da el método plot_importance . Hará una tabla con todas nuestras características (o la N principal más importante, si le pasamos un valor) clasificada por su importancia.
Pero, ¿Cómo se mide la importancia ?
El algoritmo medirá qué % de las decisiones de nuestros árboles usan cada función (cantidad de nodos que usan una determinada función sobre el total), pero hay otras opciones, y todas funcionan de manera diferente.
Esta es la gráfica de importancia de nuestro modelo inicial:
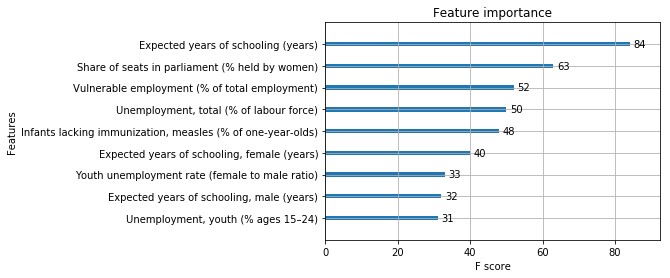
Lo que significa que nuestra hipótesis era cierta: las características con las correlaciones más altas o más bajas también son las más importantes.
Esta es la gráfica de importancia de la característica para el segundo modelo, que se desempeñó mejor:
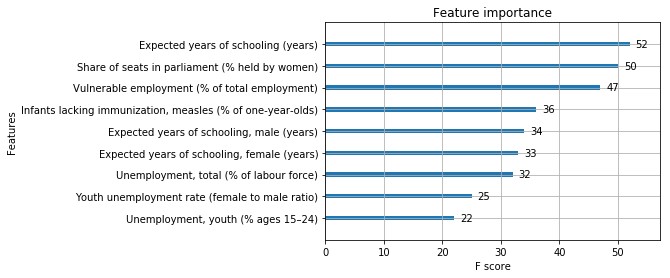
Así que ambos modelos usaban las tres primeras características Es lo más importante, aunque el primero parece haberse basado demasiado en años de escolaridad previstos . Este tipo de análisis hubiera sido un poco difícil con otros modelos.
Conclusiones
XGBoost nos proporcionó una buena regresión, e incluso nos ayudó a comprender en qué estaba basando sus predicciones.
El análisis de correlación de características nos ayudó a teorizar sobre qué características serían las más importantes, y la realidad cumplió con nuestras expectativas.
Finalmente, creo que es importante señalar qué tan rápido puede ser este tipo de modelo, aunque este ejemplo en particular no fue muy bueno para demostrarlo.
En el futuro, me gustaría para probar XGBoost Boosted Trees en un conjunto de datos mucho más grande. Si puedes pensar en alguno, házmelo saber!
Además, este conjunto de datos parece que sería divertido para algunos análisis de series de tiempo. Pero no tengo mucha experiencia con esos temas. ¿Hay algún libro, artículo o alguna otra fuente que pueda recomendarme al respecto? ¡Avísenme en los comentarios!