Cómo crear un conjunto de datos para su proyecto de aprendizaje de máquina
{kind=link}
¿Está pensando en la inteligencia artificial para su organización? ¿Ha identificado un caso de uso con un ROI comprobado? ¡Perfecto! pero no tan rápido … ¿tienes un conjunto de datos?
Bueno, la mayoría de las compañías están luchando por construir un conjunto de datos listo para la IA o quizás simplemente ignoren este problema, pensé que este artículo podría ayudarlo un poco.
Comencemos con lo básico …
A conjunto de datos es una recopilación de datos . En otras palabras, un conjunto de datos corresponde al contenido de una tabla de base de datos única, o una matriz de datos estadística estadística única, donde cada columna de la tabla representa una variable particular y cada fila corresponde a un miembro dado del conjunto de datos en cuestión.
En los proyectos de Machine Learning, necesitamos un conjunto de datos de capacitación . Es el conjunto de datos real utilizado para entrenar el modelo para realizar varias acciones.
¿Por qué necesito un conjunto de datos?
ML depende en gran medida de los datos , sin datos, es imposible que una “IA” aprenda. Es el aspecto más crucial que hace posible el entrenamiento de algoritmos … No importa cuán grande sea su equipo de AI o el tamaño de su conjunto de datos, si su conjunto de datos no es lo suficientemente bueno, ¡todo su proyecto de AI fracasará! He visto proyectos fantásticos que fracasan porque no teníamos un buen conjunto de datos a pesar de tener el caso de uso perfecto y científicos de datos muy capacitados.
Una IA supervisada está entrenada en un corpus de datos de capacitación.
Durante un desarrollo de AI , siempre confiamos en los datos. Desde la capacitación, el ajuste, la selección de modelos hasta las pruebas, utilizamos tres conjuntos de datos diferentes: el conjunto de capacitación, el conjunto de validación y el conjunto de pruebas. Para su información, los conjuntos de validación se utilizan para seleccionar y ajustar el modelo ML final.
Puede pensar que la recopilación de datos es suficiente, pero es lo contrario. En todos los proyectos de AI, la clasificación y el etiquetado de conjuntos de datos nos lleva la mayor parte del tiempo, especialmente los conjuntos de datos lo suficientemente precisos para reflejar una visión realista del mercado / mundo.
Quiero presentarle los dos primeros conjuntos de datos que necesitamos: el conjunto de datos de entrenamiento y conjunto de datos de prueba porque se usan para diferentes propósitos durante su proyecto de AI y el éxito de un proyecto depende mucho de ellos.
- El conjunto de datos de entrenamiento es el que se utiliza para entrenar a un Algoritmo para entender cómo aplicar conceptos como las redes neuronales, para aprender y producir resultados. Incluye tanto los datos de entrada como los resultados esperados.
Los conjuntos de capacitación constituyen la mayoría de los datos totales, alrededor del 60%. En las pruebas, los modelos se ajustan a los parámetros de un proceso conocido como ajuste de pesos.
- El conjunto de datos de prueba se utiliza para evaluar qué tan bien se entrenó su algoritmo con el conjunto de datos de entrenamiento . En los proyectos de AI, no podemos usar el conjunto de datos de entrenamiento en la etapa de prueba porque el algoritmo ya sabrá por adelantado el resultado esperado, que no es nuestro objetivo.
Los conjuntos de prueba representan el 20% de los datos. Se garantiza que el conjunto de pruebas son los datos de entrada agrupados con salidas correctas verificadas, generalmente por verificación humana.
Según mi experiencia, es una mala idea intentar un ajuste posterior a la fase de prueba. Es probable que conduzca a un ajuste excesivo.
¿Qué es el ajuste excesivo?
Un problema bien conocido para los científicos de datos … El ajuste excesivo es un error de modelo que ocurre cuando una función se ajusta demasiado a un conjunto limitado de puntos de datos.
¿Cuántos datos se necesitan?
Todos los proyectos son de alguna manera únicos, pero diría que necesitas 10 veces más datos como el número de parámetros en el modelo que se está construyendo. Cuanto más complicada es la tarea, más datos se necesitan.
¿Qué tipo de datos necesito?
Siempre comienzo proyectos de AI haciendo preguntas precisas a la decisión de la compañía. fabricante. ¿Qué estás tratando de lograr a través de la IA? Según su respuesta, debe considerar qué datos necesita para abordar la pregunta o el problema en el que está trabajando. Realice algunas suposiciones acerca de los datos que necesita y tenga cuidado de registrarlas para que pueda probarlas más tarde si es necesario.
A continuación hay algunas preguntas para ayudarlo:
- ¿Qué datos puede usar para este proyecto? Debe tener una idea clara de todo lo que puede usar.
- ¿Qué datos no están disponibles que desearía tener? Me gusta esta pregunta ya que siempre podemos simular estos datos de alguna manera.
Tengo un conjunto de datos, ¿y ahora qué?
¡No tan rápido! Debe saber que todos los conjuntos de datos son inexactos. En este momento del proyecto, necesitamos hacer alguna preparación de datos, un paso muy importante en el proceso de aprendizaje automático. Básicamente, la preparación de datos consiste en hacer que su conjunto de datos sea más adecuado para el aprendizaje automático. Es un conjunto de procedimientos que consumen la mayor parte del tiempo empleado en proyectos de aprendizaje automático.
Incluso si tiene los datos, aún puede tener problemas con su calidad, así como sesgos ocultos en sus conjuntos de entrenamiento. En pocas palabras, la calidad de los datos de entrenamiento determina el rendimiento de los sistemas de aprendizaje automático.
¿Has oído hablar de los sesgos de la IA?
Una IA puede ser fácilmente influenciada … A lo largo de los años, los científicos de datos han descubierto que algunos conjuntos de datos populares utilizados para entrenar el reconocimiento de imágenes incluyen sesgos de género.
Como consecuencia, las aplicaciones de AI tardan más en construirse porque somos tratando de asegurarse de que los datos estén correctos e integrados correctamente.
¿Qué pasa si no tengo suficientes datos?
Puede suceder que falten los datos necesarios para integrar una solución de AI. No voy a mentirte, lleva tiempo construir un conjunto de datos listos para la IA si aún dependes de documentos en papel o archivos csv . Le recomendaría que primero dedique un tiempo a desarrollar una estrategia de recopilación de datos moderna.
Si ya determinó el objetivo de su solución de ML, puede pedir a su equipo que dedique tiempo a crear los datos o externalizar el proceso. En mi último proyecto, la compañía quería construir un modelo de reconocimiento de imagen pero no tenía imágenes. Como consecuencia, pasamos semanas tomando fotos para crear el conjunto de datos y descubrir formas para que los futuros clientes lo hagan por nosotros.
¿Tiene una estrategia de datos?
La creación de una cultura basada en datos en una organización es quizás la parte más difícil de ser un especialista en inteligencia artificial. Cuando trato de explicar por qué la empresa necesita una cultura de datos, puedo ver la frustración en los ojos de la mayoría de los empleados. De hecho, la recopilación de datos puede ser una tarea molesta que carga a sus empleados. Sin embargo, podemos automatizar la mayor parte del proceso de recopilación de datos.
Otro problema podría ser la accesibilidad y la propiedad de los datos … En muchos de mis proyectos, noté que mis clientes tenían suficientes datos, pero que los datos estaban bloqueados y eran difíciles de acceder . Debe crear conexiones entre los silos de datos en su organización. Para obtener información especial, debe recopilar datos de múltiples fuentes.
Con respecto a la propiedad, el cumplimiento también es un problema con las fuentes de datos, solo porque una empresa tenga acceso a la información, no significa que tenga el derecho de uso. ¡eso! No dude en preguntar a su equipo legal acerca de esto (GDPR en Europa es un ejemplo).
¡Calidad, alcance y cantidad!
El aprendizaje automático no se trata solo de un gran conjunto de datos. De hecho, no alimenta el sistema con todos los puntos de datos conocidos en ningún campo relacionado. Queremos alimentar el sistema con datos cuidadosamente curados, con la esperanza de que pueda aprender, y tal vez ampliar, al margen, el conocimiento que las personas ya tienen.
La mayoría de las empresas creen que es suficiente reunir todos los datos posibles, combinarlos y dejar que la inteligencia de búsqueda de AI.
Al crear un conjunto de datos, debes apuntar a una diversidad de datos. Siempre recomiendo a las empresas reunir datos internos y externos. El objetivo es crear un conjunto de datos único que será difícil de copiar para sus competidores. Las aplicaciones de aprendizaje automático requieren una gran cantidad de puntos de datos, pero esto no significa que el modelo deba considerar una amplia gama de características.
Queremos datos significativos relacionados con el proyecto. Es posible que posea datos ricos y detallados sobre un tema que simplemente no es muy útil. Un experto en inteligencia artificial le hará preguntas precisas sobre qué campos son realmente importantes, y cómo esos campos probablemente serán importantes para su aplicación de los conocimientos que obtenga.
En mi última misión, tuve que ayudar a una empresa a construir un modelo de reconocimiento de imagen para Con fines de marketing. La idea era construir y confirmar una prueba de concepto. Esta empresa no tenía ningún conjunto de datos, excepto algunos renders 3D de sus productos. Queríamos que la AI reconociera el producto, leyera el empaque, determinara si era el producto correcto para el cliente y les ayudara a entender cómo usarlo.
Nuestro conjunto de datos estaba compuesto por 15 productos y para cada uno, logramos tengo 200 imágenes. Este número se justifica por el hecho de que todavía era un prototipo, de lo contrario, ¡habría necesitado muchas más imágenes! Esto supone que estás utilizando técnicas de aprendizaje por transferencia.
Cuando se trata de imágenes, necesitábamos diferentes fondos, condiciones de iluminación, ángulos, etc.
Todos los días, solía seleccionar 20 imágenes al azar Desde el conjunto formativo y analizarlos. Me daría una buena idea de cuán diverso y preciso era el conjunto de datos.
Cada vez que he hecho esto, he descubierto algo importante con respecto a nuestros datos. Podría ser un número desequilibrado de imágenes con el mismo ángulo, etiquetas incorrectas, etc.
Una buena idea sería comenzar con un modelo que haya sido entrenado previamente en un gran conjunto de datos existentes y utilizar la transferencia de aprendizaje para ajustarlo. con su conjunto más pequeño de datos que ha recopilado.
Preprocesamiento de datos
Bien, volvamos a nuestro conjunto de datos. En este paso, ha reunido sus datos que considera esenciales, diversos y representativos para su proyecto de AI. El preprocesamiento incluye la selección de los datos correctos del conjunto completo de datos y la creación de un conjunto de capacitación. El proceso de reunir los datos en este formato óptimo se conoce como transformación de características .
- Formato: Los datos se pueden distribuir en diferentes archivos. Por ejemplo, los resultados de ventas de diferentes países con diferentes monedas, idiomas, etc., que deben reunirse para formar un conjunto de datos.
- Limpieza de datos: En este paso, nuestro objetivo es lidiar con valores perdidos y eliminar caracteres no deseados de los datos.
- Extracción de características: En este paso, nos centramos en el análisis y la optimización del número de características. Por lo general, un miembro del equipo tiene que averiguar qué características son importantes para la predicción y seleccionarlas para cálculos más rápidos y bajo consumo de memoria.
La estrategia de datos perfecta
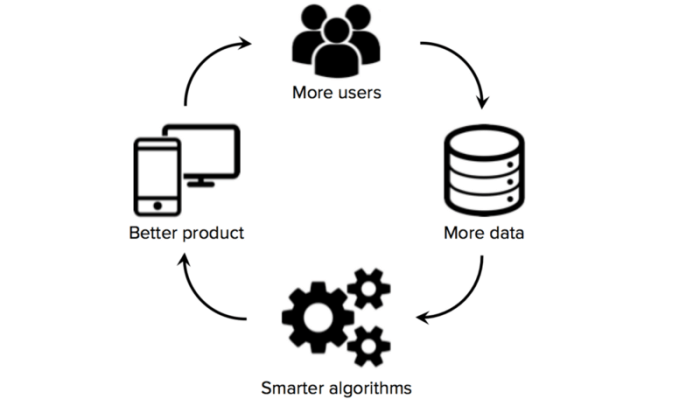
Los proyectos de AI más exitosos son aquellos que Integrar una estrategia de recolección de datos durante el ciclo de vida del producto / servicio. De hecho, la recopilación de datos no puede ser una serie de ejercicios únicos. Debe estar integrado en el producto central en sí. Básicamente, cada vez que un usuario se involucra con su producto / servicio, desea recopilar datos de la interacción. El objetivo es utilizar este flujo de datos nuevo y constante para mejorar su producto / servicio.
Cuando alcanza este nivel de uso de datos, cada nuevo cliente que agrega hace que el conjunto de datos sea más grande y, por lo tanto, el producto sea mejor, lo que atrae a más clientes. lo que hace que el conjunto de datos sea mejor, y así sucesivamente. Es una especie de círculo positivo.
{kind=link}
Los mejores proyectos de ML orientados a largo plazo son aquellos que aprovechan conjuntos de datos dinámicos y constantemente actualizados. La ventaja de crear dicha estrategia de recopilación de datos es que se vuelve muy difícil para sus competidores replicar su conjunto de datos. Con los datos, la IA mejora y, en algunos casos, como el filtrado colaborativo, es muy valioso. El filtrado colaborativo hace sugerencias basadas en la similitud entre los usuarios, mejorará con el acceso a más datos; cuantos más datos de usuario tenga uno, más probable será que el algoritmo pueda encontrar un usuario similar.
Esto significa que necesita una estrategia para la mejora continua de su conjunto de datos siempre que haya algún beneficio para el usuario para un mejor modelo. exactitud. Si puede, encuentre formas creativas de aprovechar incluso señales débiles para acceder a conjuntos de datos más grandes.
Una vez más, permítame usar el ejemplo de un modelo de reconocimiento de imagen. En mi última experiencia, imaginamos y diseñamos una forma para que los usuarios tomen fotos de nuestros productos y nos los envíen. Estas imágenes se utilizarían para alimentar nuestro sistema de inteligencia artificial y hacer que nuestro sistema sea más inteligente con el tiempo.
Otro enfoque es aumentar la eficiencia de su canalización de etiquetado, por ejemplo, solíamos confiar mucho en un sistema que podría sugerir etiquetas. predicho por la versión inicial del modelo para que los etiquetadores puedan tomar decisiones más rápidas.
Finalmente, he visto compañías que solo contratan a más personas para etiquetar los nuevos insumos de capacitación … Toma tiempo y dinero, pero funciona, aunque puede ser difícil en las organizaciones que tradicionalmente no tienen una partida en su presupuesto para este tipo de gasto.
A pesar de lo que dice la mayoría de las empresas de SaaS, Machine Learning requiere tiempo y preparación. Cada vez que escuche el término AI, debe pensar en los datos detrás de él. Espero que este artículo le ayude a comprender la función clave de los datos en los proyectos de LD y lo convenza para que dedique tiempo a reflexionar sobre su estrategia de datos.
Cómo crear un conjunto de datos para su proyecto de aprendizaje automático se publicó originalmente en Hacia la ciencia de datos en Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.