Random Forest es siempre el modelo que tengo ‘a mano’ justo después del modelo de regresión. Permítanme decirles por qué.
Ningún algoritmo único domina la hora de elegir un modelo de aprendizaje automático. Algunos funcionan mejor con grandes conjuntos de datos y otros funcionan mejor con datos de alta dimensión.
“Un modelo es como un par de gafas. Enfoca ciertas cosas “. – Mi instructor de Data Science.
Por lo tanto, es importante evaluar la efectividad de un modelo para su conjunto de datos en particular. En este artículo, daré una descripción general de alto nivel de cómo funciona el bosque aleatorio y discutiré las ventajas e inconvenientes de este modelo en el mundo real.
Esencialmente, Random Forest es un buen modelo si desea un alto rendimiento con menos necesidad de interpretación.
¿Qué es Random Forest?
Los Random Forest son modelos de árbol de decisión empaquetados que se dividen en un subconjunto de características en cada división. Analicemos primero un árbol de decisión único.
Luego analicemos los árboles de decisión empaquetados y finalmente introduzcamos la división en un subconjunto de características.
Decision Tree o Árbol de decisión
Esencialmente, un árbol de decisión divide los datos en grupos de datos más pequeños en función de las características de los datos hasta que tengamos un conjunto suficientemente pequeño de datos que solo tengan puntos de datos en una etiqueta.
Veamos un ejemplo. A continuación se muestra un árbol de decisiones sobre si se debe jugar al tenis.
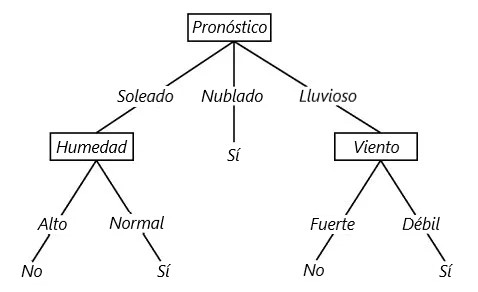
En el ejemplo anterior, el árbol de decisiones se divide en varias funciones hasta que lleguemos a la conclusión de “Sí”, deberíamos jugar al tenis, o “No” no deberíamos jugar al tenis.
Siga las líneas a lo largo del árbol para determinar la decisión. Por ejemplo, si el panorama está nublado, entonces “Sí” deberíamos jugar al tenis. Si la perspectiva es soleada y la humedad es alta, entonces “No” no debemos jugar al tenis.
En un modelo de árbol de decisión, estas divisiones se eligen de acuerdo con una medida de pureza. Es decir, en cada nodo, queremos que se maximice la ganancia de información.
Para un problema de regresión, consideramos la suma residual de cuadrados (RSS) y para un problema de clasificación, consideramos el índice de Gini o la entropía.
No voy a entrar en demasiados detalles sobre esto, pero si está interesado en aprender más, consulte esta conferencia.
Bagged Trees
Ahora tomemos el concepto de árbol de decisión y apliquemos los principios del bootstrapping para crear árboles en bolsas.
Bootstrapping
Es una técnica de muestreo en la que tomamos muestras aleatoriamente con reemplazo del conjunto de datos.
Nota al margen: Cuando realizamos el arranque, utilizamos solo aproximadamente 2/3 de los datos. Los aproximadamente 1/3 de los datos (datos “fuera de bolsa”) no se usan en el modelo y se pueden usar convenientemente como un conjunto de prueba.
Bagging o agregación de arranque
Es donde creamos árboles en bolsas creando un número X de árboles de decisión que se entrenan en X conjuntos de entrenamiento con arranque.
El valor predicho final es el valor promedio de todos nuestros árboles de decisión X. Un único árbol de decisión tiene una gran varianza (tiende a sobreajustarse), por lo que al agrupar o combinar muchos alumnos débiles con alumnos fuertes, estamos promediando la varianza. ¡Es un voto mayoritario!
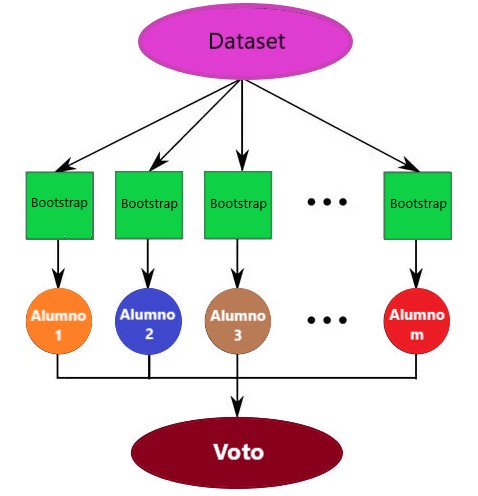
Random Forest o Bosque aleatorio
El bosque aleatorio mejora el empaquetamiento porque decora los árboles con la introducción de la división en un subconjunto de características.
Esto significa que en cada división del árbol, el modelo considera solo un pequeño subconjunto de características en lugar de todas las características del modelo.
Esto es importante para que la varianza pueda ser promediada. Considere lo que sucedería si el conjunto de datos contiene algunos predictores fuertes.
Estos predictores se elegirán constantemente en el nivel superior de los árboles, por lo que tendremos árboles estructurados muy similares. En otras palabras, los árboles estarían altamente correlacionados.
Entonces, en resumen de lo que se dijo inicialmente, los bosques aleatorios o Random Forest son modelos de árboles de decisión empaquetados que se dividen en un subconjunto de características en cada división.
¿Por qué Random Forest es genial?
Impresionante en versatilidad
Ya sea que tenga una tarea de regresión o clasificación, el bosque aleatorio es un modelo aplicable para sus necesidades. Puede manejar características binarias, características categóricas y características numéricas. Hay muy poco preprocesamiento que se necesita hacer. Los datos no necesitan ser reescalados o transformados.
Paralelizable
Son paralelizables, lo que significa que podemos dividir el proceso en varias máquinas para ejecutar. Esto resulta en un tiempo de cálculo más rápido. Los modelos reforzados son secuenciales en contraste, y demorarían más en computarse.
Nota al margen: Específicamente, en Python, para ejecutar esto en múltiples máquinas, proporcione el parámetro “n_jobs = -1” El -1 es una indicación para usar todos Máquinas disponibles. Consulte la documentación de scikit-learn para obtener más detalles.
Excelente con alta dimensionalidad
Los bosques aleatorios o Random Forest son excelentes con datos de alta dimensión ya que estamos trabajando con subconjuntos de datos.
Velocidad de entrenamiento / predicción rápida
Es más rápido de entrenar que los árboles de decisión porque trabajamos solo en un subconjunto de características en este modelo, por lo que podemos trabajar fácilmente con cientos de características.
La velocidad de predicción es significativamente más rápida que la velocidad de entrenamiento porque podemos guardar los bosques generados para usos futuros.
Robusto ante valores atípicos (Outliers) y datos no lineales
El bosque aleatorio maneja los valores atípicos esencialmente agrupándolos. También es indiferente a las características no lineales.
Maneja datos no balanceados
Tiene métodos para equilibrar el error en conjuntos de datos desequilibrados de población de clases. El bosque aleatorio intenta minimizar la tasa de error general, por lo que cuando tenemos un conjunto de datos desequilibrado, la clase más grande obtendrá una tasa de error baja mientras que la clase más pequeña tendrá una tasa de error mayor.
Bajo sesgo, varianza moderada
Cada árbol de decisión tiene una gran varianza, pero un sesgo bajo. Pero como promediamos todos los árboles en un bosque aleatorio, también promediamos la varianza para tener un modelo de sesgo bajo y varianza moderada.
Desventajas
- Interpretabilidad del modelo: los modelos de bosque aleatorios no son tan interpretables; son como cajas negras.
- Para conjuntos de datos muy grandes, el tamaño de los árboles puede consumir mucha memoria.
- Puede tender a sobreajustarse, por lo que debes ajustar los hiperparámetros.