
Lecciones Aprendidas al Cometer Varios Errores en Proyectos de Data Science
Introducción
La mayoría de los artículos sobre cómo completar una tarea de ciencia de datos suelen centrarse en escribir un algoritmo para resolver un problema específico, como clasificar un documento de texto o pronosticar datos financieros.
Si bien aprender a hacer estas cosas es vital para cualquier profesional de data science, es solo una pequeña parte del proceso que implica completar un proyecto de data science en el mundo real.
Aunque puedas codificar la solución perfecta para un problema de clasificación, ¿realmente es valiosa para la empresa? Es esencial considerar la solución actual al problema y qué punto de referencia debe superar tu modelo para que los usuarios confíen en los resultados.
Una vez que el algoritmo esté en funcionamiento, ¿recibes información suficiente para asegurar que sigue produciendo resultados útiles?
En este post, quiero establecer algunas pautas para desarrollar y llevar a cabo proyectos de data science efectivos y sostenibles. Esta guía es una recopilación de lecciones aprendidas tras cometer varios errores en mis propios proyectos de data science, así como al observar a otros.
No todo lo que comparto será aplicable a todos los profesionales de data science, ya que cada caso es único. Sin embargo, he trabajado en equipos donde no contábamos con un analista de negocios, un gerente de producto o incluso un gerente de ciencia de datos dedicados, lo que me llevó a asumir algunas de esas responsabilidades. Esta experiencia resultó ser valiosa, y aquí comparto lo que aprendí.
Mención Especial: Independientemente de tu opinión sobre mis reflexiones, te recomiendo ver el video en este artículo sobre cómo realizar ciencia de datos impulsada por las partes interesadas, presentado por Max Shron, jefe de ciencia de datos en Warby Parker. Es una excelente referencia para realizar proyectos de data science en el mundo real.
¿Qué Preguntas Deben Abordarse para Considerar un Proyecto Exitoso?
Cuando se plantea una solución a un problema, es útil visualizar qué significa el éxito. Aquí hay una lista de preguntas clave que te ayudarán a determinar si un proyecto de data science es exitoso:
- ¿Por qué estás haciendo el proyecto? ¿Qué valor aporta y cómo contribuye a los objetivos del equipo?
- ¿Quiénes son los principales interesados?
- ¿Cuál es la solución actual al problema?
- ¿Hay una solución simple y efectiva que se pueda implementar rápidamente?
- ¿Has involucrado a las personas adecuadas con suficiente antelación?
- ¿Has verificado tu solución con otra persona?
- ¿El código es robusto?
- ¿El proyecto es fácilmente comprensible y transferible a otros?
- ¿Cómo estás validando tu modelo en producción?
- ¿Cómo recopilas los comentarios sobre la solución?
Si puedes responder adecuadamente a estas preguntas, es probable que tu proyecto de data science sea exitoso. Aunque esta lista puede no ser exhaustiva, es un buen punto de partida.
Kate Strachnyi también sugiere un conjunto de 20 preguntas que deberías considerar antes de iniciar el análisis de datos. Si prefieres no perderte en mis reflexiones, te recomiendo consultar su artículo.
Guía de 5 Pasos para Proyectos de Data Science
Paso 1: Obtén una Evaluación Inicial del Valor Potencial del Proyecto

¿Por qué hacerlo? Esto te ayudará a priorizar proyectos y explicar por qué uno debe completarse antes que otro. También clarificará cómo el proyecto se alinea con los objetivos del equipo y la empresa.
¿Qué implica esto? Haz una cuantificación aproximada de los beneficios, como dinero ahorrado o ingresos incrementados. No tiene que ser perfecto, solo una estimación. Esto también implica identificar a los principales interesados.
¿Qué sucede si no se hace? Puedes pasar años en un proyecto de data science del que nadie se beneficia. Un ejemplo es cuando un equipo construyó un modelo para identificar a los clientes más propensos a ser contactados por marketing, pero no alineó las expectativas con las partes interesadas, lo que resultó en un esfuerzo infructuoso.
¿Cuál es el resultado? Una estimación cuantitativa del valor del proyecto acompañada de un resumen ejecutivo que brinde contexto.
Paso 2: Determina el Enfoque Actual y Crea un Modelo de Línea Base
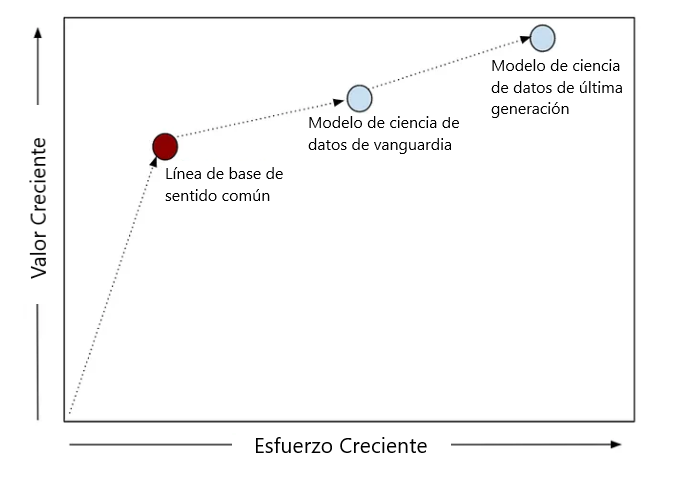
¿Por qué hacerlo? Esto te da un punto de referencia. Todos los modelos útiles deberían superar este enfoque.
¿Qué implica? Conversa con las partes interesadas para entender qué están haciendo actualmente y qué tan exitosos son.
¿Qué sucede si no se hace? Podrías perder tiempo construyendo un modelo complejo que no aporta valor. Este fue el caso en un proyecto de recomendación que no superó la solución básica.
Paso 3: Tener una Discusión de Equipo

¿Por qué hacerlo? Asegúrate de que todos los involucrados en el proyecto estén al tanto y alineados.
¿Qué implica? Habla con al menos otro profesional de data science y con los ingenieros que participarán en la producción de tu trabajo.
¿Qué sucede si no se hace? Podrías pasar por alto riesgos importantes y generar un código difícil de manejar en producción.
Paso 4: Desarrollo del Modelo
¿Por qué hacerlo? Este es el modelo que resolverá el problema.
¿Qué implica? No se trata solo de crear un modelo; también debes realizar revisiones de código, documentar adecuadamente y probar el código.
¿Qué sucede si no se hace? Sin pruebas adecuadas, tu modelo podría tener errores que solo se descubrirán en producción.
Paso 5: Seguimiento y Retroalimentación del Modelo

¿Por qué hacerlo? Asegúrate de que el producto funcione como se espera en producción.
¿Qué implica? Implementa un monitoreo proactivo y métodos para recibir retroalimentación de las partes interesadas.
¿Qué sucede si no se hace? Podrías perder la confianza de las partes interesadas y desperdiciar tiempo corrigiendo errores que podrían haberse evitado con un seguimiento adecuado.
Omisiones Notables
Una omisión importante que debo mencionar es la evaluación del modelo. Esta es crucial para evitar la degradación inesperada del modelo en producción. También he dejado de lado la experimentación, que es clave para medir el impacto real de tus soluciones.
En resumen, estos son cinco pasos de alto nivel necesarios para desarrollar proyectos de data science exitosos. Ten en cuenta que no todos los pasos deben ser realizados por un solo profesional, ya que algunos equipos pueden contar con miembros dedicados para ciertas tareas. Estos pasos son guías y deberías adaptarlos según el contexto de tu proyecto.
Si tienes comentarios, preguntas o sugerencias, no dudes en compartirlos en los comentarios. ¡Gracias por leer!