TensorFlow es una popular biblioteca de software de código abierto de Google. Originalmente, fue desarrollado por el equipo de Google Brain para uso interno de Google. A medida que la comunidad de investigación de AI se hacía cada vez más colaborativa, TensorFlow se lanzó bajo la licencia de código abierto Apache 2.0.
El estudio detallado de TensorFlow puede llevar meses. Pero un vistazo de su poder proporciona una buena motivación para sumergirse en él. Con esto en mente, este blog analiza la implementación de un modelo de clasificación.
La clasificación es uno de los problemas frecuentes en los que trabajamos en AI. Normalmente tenemos un conjunto de entradas que deben clasificarse en diferentes categorías. Podemos usar TensorFlow para entrenar un modelo para esta tarea. A continuación, veremos cada paso de una de estas implementaciones.
Importar módulos
¡Lo primero es lo primero! TensorFlow es una biblioteca externa que debe importarse al script antes de que podamos usarlo.
https://gist.github.com/solegaonkar/580daf511532f7439047f245d2f1413e
Junto con TensorFlow, normalmente importamos algunas otras bibliotecas que Haz nuestra vida más sencilla. Keras es parte de TensorFlow.
Nos ayuda a desarrollar modelos de alto orden muy fácilmente. Podemos crear los modelos utilizando TensorFlow solo. Sin embargo, Keras simplifica nuestro trabajo.
NumPy es una importación predeterminada en cualquier tarea de aprendizaje automático. No podemos vivir sin ella. Casi todas las manipulaciones de datos requieren NumPy.
Otro módulo importante es el matplotlib. Es muy importante que visualicemos los datos disponibles para tener una idea de lo que se esconde en ellos. Cualquier cantidad de análisis algorítmico no puede darnos lo que obtenemos con solo mirar los datos en forma gráfica.
TensorFlow ha pasado por algunos cambios en las versiones. Los conceptos no han cambiado, pero sí algunos de los métodos. Es una buena práctica verificar la versión que usamos.
Si tenemos un problema, podemos consultar la ayuda para la versión específica. Muchos desarrolladores han enfrentado el problema debido a un conflicto de versiones, por lo que es mucho más sencillo buscar problemas en las versiones específicas de los foros.
El siguiente código se basa en la versión 1.12.0
MNIST Dataset
Para compartir un breve resumen Introducción a las ideas básicas, podemos ver una implementación de un problema simple. El MINST (Instituto Nacional Modificado de Estándares y Tecnología) proporciona un buen conjunto de datos de dígitos escritos a mano del 0 al 9. Podemos usar esto para entrenar una red neuronal y construir un modelo que pueda leer y descodificar dígitos escritos a mano.
Este problema Es a menudo llamado el “Hola Mundo” de Aprendizaje Profundo. Por supuesto, necesitamos mucho más para desarrollar aplicaciones “reales”. Esto es bueno para darle una introducción al tema. Por supuesto, hay mucho más para TensorFlow. Si está interesado en un estudio detallado, puede tomar un curso en línea.
Cargar datos
El primer paso es cargar los datos disponibles. TensorFlow nos proporciona un buen conjunto de conjuntos de fechas de prueba que podemos utilizar para aprender y probar. El conjunto de datos MINST también está disponible en estos.
Así que el trabajo de obtener los datos de entrenamiento y pruebas es bastante simple en este caso. En los problemas de la vida real, acumular, limpiar y cargar dichos datos es una parte importante del trabajo. Aquí lo hacemos en una sola línea de código.
https://gist.github.com/solegaonkar/21d57ad883403edcd08d67a3beedf27d
Esto nos da cuatro Tensors:
train_images, train_labels, test_images y test_labels.
El método load_data () se encarga de dividir los datos disponibles en los conjuntos de prueba y tren. En un problema de la vida real, tenemos que hacerlo nosotros mismos. Pero, para el código de ejemplo, podemos usar los métodos de utilidad disponibles junto con el conjunto de datos TensorFlow.
Verificar los datos
Como práctica recomendada, siempre se debe echar un vistazo a los datos disponibles.
https://gist.github.com/solegaonkar/794ac2e12a1767850f578918c9d4080c
https://gist.github.com/solegaonkar/c05c16607811b80320345347dc29dc8b
Hay mucho que podemos hacer en esta etapa. Pero tiene muy poco sentido para datos como este que ya se han limpiado.
Sanitización de datos
El siguiente paso es modificar los datos disponibles para que sean más adecuados para el entrenamiento del modelo.
Los datos de la imagen son naturalmente bidimensional. Eso puede ser muy bueno para ver gráficos. Pero, para entrenar una red neuronal, necesitamos registros de una sola dimensión. Esto requiere “aplanar” los datos. Keras nos proporciona formas fáciles de acoplar los datos dentro del modelo. Pero para el preprocesamiento genérico, es mucho mejor aplanarlo de inmediato. TensorFlow también proporciona eso.
https://gist.github.com/solegaonkar/4092d5fde35e5841ab42c0d705c7ca84
Las etiquetas que tenemos están en términos de los números 0–9. Pero, como resultado de una red neuronal, estos valores no tienen una secuencia numérica.
Es decir, 1 es menor que 9. Pero cuando leemos las imágenes, esta relación no es significativa en absoluto. La relación numérica entre estas salidas es incidental. Para la aplicación, son solo 10 etiquetas diferentes. Son resultados categóricos.
Para trabajar con esto, necesitamos mapear las etiquetas en 10 matrices independientes diferentes de 1 y 0. Necesitamos asignar cada etiqueta a una matriz de 10 números binarios: 0 para todos y 1 para el valor específico. Por ejemplo, 1 se asignará a [0,1,0,0,0,0,0,0,0,0]; 8 se asignarán a [0,0,0,0,0,0,0,0,0,1,0] y así sucesivamente. Eso se denomina salida “categórica”.
https://gist.github.com/solegaonkar/3779c4c28d0dd8aef8945ac805a8b4f1
Otra tarea muy importante es normalizar los datos. Las funciones de activación – relu o sigmoid o tanh … todas funcionan de manera óptima cuando los números son menores que 1. Este es un paso importante en cualquier red neuronal. La omisión de este paso tiene un impacto muy negativo en la eficacia del modelo.
https://gist.github.com/solegaonkar/2d8030a819979e4223c2f3b3b1db6e47
Este es un paso muy simple pero importante para entrenar una red neuronal. Nuevamente, si se trata de algunos datos sin procesar, necesitaríamos un esfuerzo mucho mayor en el saneamiento. Pero este ya está saneado por Keras.
Aumento de datos
Los recursos que tenemos son siempre menores de lo que necesitamos. Los datos no son una excepción. Para lograr mejores y mejores resultados, necesitamos mucho más de lo que tenemos.
Y podemos generar más datos de lo que tenemos disponible, utilizando nuestro conocimiento sobre los datos. Por ejemplo, sabemos que el número no cambia si la imagen completa se desplaza un píxel a cada lado.
Por lo tanto, cada imagen en el conjunto de entrada puede generar cuatro imágenes más desplazando un píxel en cada lado. Las imágenes aparecen casi sin cambios para nuestro ojo.
Pero para el modelo de red neuronal, es un nuevo conjunto de entrada. Esta simple información nos puede dar 5 veces más datos. Vamos a hacer eso.
https://gist.github.com/solegaonkar/aaba04f3765102280976a4dae5f5e8d4
No se preocupe si no puede entender el código anterior. Consulte los Blogs de NumPy para obtener detalles sobre cómo trabajar con matrices NumPy.
Básicamente, este código simplemente elimina las celdas de un lado de la imagen e inserta 0 en el lado opuesto. Lo hace desde los cuatro lados de cada imagen en los datos de entrenamiento, y luego lo agrega a la nueva matriz llamada augmented_images. Junto con eso, también construye la matriz augmented_lables.
Ahora, podemos usar augmented_images y augmented_labels en lugar de train_images y train_labels para entrenar nuestro modelo. Pero, espera un minuto.
Si pensamos en esto, los datos ya no son aleatorios. Tenemos una gran cantidad de datos con imágenes en el centro, seguido de una gran parte con imágenes cambiadas en cada dirección. Dichos datos no crean buenos modelos. Necesitamos mejorar esto mezclando bien los datos.
Pero esto no es tan simple. Ahora, tenemos un conjunto de imágenes y un conjunto de etiquetas. Tenemos que barajar cualquiera de ellos. Pero, la correspondencia no debe perderse. Después de la reproducción aleatoria, una imagen de 5 debe apuntar a la etiqueta 5
NumPy nos proporciona una forma elegante de hacerlo.
https://gist.github.com/solegaonkar/b54d1c551fb7220714f7a6ee02512f21
Esencialmente, combinamos los dos en una sola entidad y luego los barajamos de manera que las imágenes y las etiquetas se muevan juntas.
Entrene al modelo
Con todo en su lugar, ahora podemos comenzar con el entrenamiento de un modelo. Comenzamos creando un modelo secuencial de Keras. Podemos consultar los detalles sobre los diferentes tipos de modelos en los siguientes blogs. Añadamos tres capas a este modelo.
Keras nos permite añadir muchas capas. Pero para un problema como este, 3 capas deberían ser lo suficientemente buenas.
https://gist.github.com/solegaonkar/aed41d146a47c932c5f448283ab9a902
La forma de entrada de 784 se define por el tamaño de cada entidad en los datos de entrada . Tenemos imágenes de 784 cada una. Así que ahí es donde empezamos.
Y el tamaño de salida debe ser 10, porque tenemos 10 resultados posibles. Una red típica tiene una activación de softmax en la última capa y se basa en las capas ocultas internas.
El tamaño de cada capa es solo una estimación basada en el juicio. Podemos desarrollar este juicio con práctica, experiencia y comprensión de cómo funcionan las Redes neuronales. Puede intentar jugar con ellos para ver el efecto que cada uno tiene en la eficiencia del modelo.
A continuación, compilamos y entrenamos el modelo con los datos disponibles.
https://gist.github.com/solegaonkar/b0354386a2e8cb52e84b523ddd3931eb
Los parámetros del compilador – loss = “categorical_crossentropy” y optimizer = tf.train.AdamOptimizer () pueden parecer confusos. Puede consultar los blogs de deep learning Aprendizaje profundo para comprenderlos mejor.
El método model.fit () hace el trabajo real de entrenar el modelo con los datos que tenemos.
Esto genera una salida:
https://gist.github.com/solegaonkar/484f9b6aaa00dbc6e052997b1d490ede
Podemos ver la reducción de la pérdida y el aumento de precisión con cada iteración. Tenga en cuenta que es posible que las salidas no siempre coincidan con precisión, debido a la naturaleza aleatoria de la reproducción aleatoria y el entrenamiento. Pero la tendencia debería ser similar.
Evaluar el modelo
Ahora que tenemos un modelo capacitado, necesitamos evaluar qué tan bueno es. El primer paso simple es verificar usando los propios métodos de evaluación de TensorFlow.
https://gist.github.com/solegaonkar/99254d28e9080230aac2ffad6da79d8a
Eso es bastante bueno. Teniendo en cuenta la cantidad de datos que teníamos, esta es una buena precisión. Pero, esta prueba no es suficiente. Una precisión muy alta también podría significar un sobreajuste. Así que debemos verificarlo con los datos de la prueba.
https://gist.github.com/solegaonkar/8bf9743b6617013edc5eb3f9c9b69e10
Uno puede notar que la precisión es ligeramente menor en los datos de la prueba. Esto significa un ligero exceso de equipamiento. Pero eso no es tan malo.
Así que podemos vivir con eso por ahora. En un ejemplo de la vida real, según el requisito, se podría tratar de modificar la forma del modelo y otros hiperparámetros para obtener mejores resultados.
Muestreo
Eso puede no darnos toda la confianza que necesitamos. Podemos verificar manualmente algunas muestras para ver cómo ha funcionado nuestro modelo.
Primero, cree la predicción para todas las imágenes de prueba. Ahora, la predicción es una matriz con salida para todas las imágenes en el conjunto de prueba.
https://gist.github.com/solegaonkar/b6991a1e72b50f29efa87d217d987837
Podemos ver que cada elemento en este conjunto es un conjunto de 10 – que muestra la probabilidad de que la imagen de entrada pertenezca a una etiqueta determinada.
Cuando verificamos el elemento cero en el conjunto de predicción, podemos ver que la probabilidad de todos los elementos es muy baja, excepto el elemento 7, que es casi 1.
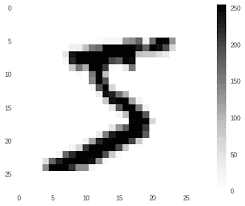
Por lo tanto, para la imagen 0, se podría predecir 7. Veamos ahora como se ve la imagen de prueba. Antes de eso, tenemos que cambiar la forma de la matriz de imágenes (¿recuerdas que habíamos creado una matriz de una sola dimensión para construir el modelo?
Ahora veamos el elemento cero
https://gist.github.com/solegaonkar/e98d189496fe693cc951f119cd3aa8b8

¡De hecho, esto es 7!
Tener una respuesta correcta ciertamente no es suficiente para verificar la precisión del modelo. Pero, un punto que podemos verificar en este punto son los valores en la matriz de predicción [0].
El valor en el elemento 7 es mucho más que los otros valores. Eso significa que el modelo tiene absoluta certeza sobre el resultado. No hay dudas debido a dos resultados similares. Este es un síntoma importante de un buen modelo.