Hay muchas aplicaciones de clasificación de texto en el mundo comercial. Por ejemplo, las noticias suelen estar organizadas por temas. El contenido o los productos a menudo están etiquetados por categorías. Los usuarios pueden clasificarse en cohortes en función de cómo hablan sobre un producto o marca en línea …
Sin embargo, la gran mayoría de los artículos y tutoriales de clasificación de texto en Internet son de clasificación de texto binario.
Como el filtro de correo no deseado (spam vs. jamón), análisis del sentimiento (positivo vs. negativo). En la mayoría de los casos, nuestro problema del mundo real es mucho más complicado que eso.
Por lo tanto, esto es lo que vamos a hacer hoy: Clasificar las Quejas de Finanzas del Consumidor en 12 clases predefinidas. Los datos se pueden descargar desde data.gov .
Utilizamos Python y Jupyter Notebook para desarrollar nuestro sistema, confiando en Scikit-Learn para los componentes de aprendizaje automático. Si desea ver una implementación en PySpark lea el próximo artículo .
Formulación de problemas
El problema es el inconveniente de la clasificación de texto supervisado, y nuestro objetivo es investigar qué métodos supervisados de aprendizaje automático son los más adecuados para resolverlo.
Dado que surge una nueva queja, queremos asignarlo a una de las 12 categorías. El clasificador asume que cada nueva queja se asigna a una y solo una categoría.
Este es un problema de clasificación de texto de clase múltiple. No puedo esperar para ver lo que podemos lograr!
Exploración de datos
Antes de sumergirnos en los modelos de aprendizaje automático de máquinas, primero debemos analizar algunos ejemplos y el número de quejas en cada clase:
import pandas as pd
df = pd.read_csv('Consumer_Complaints.csv')
df.head()

Para este proyecto, solo necesitamos dos columnas: “Producto” y “Narrativa de queja del consumidor”.
Input: Consumer_complaint_narrative
Ejemplo: “Tengo información desactualizada en mi informe de crédito que he impugnado anteriormente que aún debe eliminarse esta información tiene más de siete años y no cumple con los requisitos de informe de crédito”
Output : Producto
Ejemplo: informes de crédito
Eliminaremos los valores faltantes en la columna “Narrativa de quejas del consumidor” y agregaremos una columna que codificará el producto como un entero porque las variables categóricas a menudo están mejor representadas por números enteros que cadenas.
También creamos par de diccionarios para uso futuro.
Después de la limpieza, estas son las primeras cinco filas de los datos en los que trabajaremos:
from io import StringIO
col = ['Product', 'Consumer complaint narrative']
df = df[col]
df = df[pd.notnull(df['Consumer complaint narrative'])]
df.columns = ['Product', 'Consumer_complaint_narrative']
df['category_id'] = df['Product'].factorize()[0]
category_id_df = df[['Product', 'category_id']].drop_duplicates().sort_values('category_id')
category_to_id = dict(category_id_df.values)
id_to_category = dict(category_id_df[['category_id', 'Product']].values)
df.head()

Clases desequilibradas
Vemos que el número de quejas por producto está desequilibrado. Las quejas de los consumidores son más sesgadas hacia la recopilación de deudas, los informes de crédito y la hipoteca.
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
df.groupby('Product').Consumer_complaint_narrative.count().plot.bar(ylim=0)
plt.show()

Cuando nos encontramos con tales problemas, tenemos dificultades para resolverlos con algoritmos estándar. Los algoritmos convencionales a menudo están sesgados hacia la clase mayoritaria, sin tener en cuenta la distribución de datos.
En el peor de los casos, las clases minoritarias se tratan como valores atípicos y se ignoran. En algunos casos, como detección de fraude o predicción de cáncer, tendríamos que configurar cuidadosamente nuestro modelo o equilibrar artificialmente el conjunto de datos, por ejemplo submuestreo o sobremuestreo cada clase.
Sin embargo, en nuestro caso de aprendiendo datos desequilibrados, las clases de la mayoría pueden ser de nuestro gran interés.
Es deseable tener un clasificador que proporcione una alta precisión de predicción sobre la clase mayoritaria, manteniendo una precisión razonable para las clases minoritarias. Por lo tanto, lo dejaremos como está.
Representación de texto
Los clasificadores y algoritmos de aprendizaje no pueden procesar directamente los documentos de texto en su forma original, ya que la mayoría de ellos espera vectores de características numéricas con un tamaño fijo en lugar de documentos de texto sin procesar con longitud variable.
Por lo tanto, durante el paso de preprocesamiento, los textos se convierten en una representación más manejable.
Un enfoque común para extraer características del texto es usar el modelo de la bolsa de palabras: un modelo donde, para cada documento, una descripción de la queja en nuestro caso , se tiene en cuenta la presencia (y a menudo la frecuencia) de palabras, pero se ignora el orden en que ocurren.
Específicamente, para cada término de nuestro conjunto de datos, calcularemos una medida llamada Frecuencia de términos, Frecuencia de documentos inversa , abreviado a tf-idf.
Utilizaremos de sklearn: sklearn.feature_extraction.text.TfidfVectorizer para calcular un tf-idf vector para cada una de las narrativas de quejas del consumidor:
sublinear_dfse establece enTruepara usar una forma logarítmica para la frecuencia.min_dfes el número mínimo de documentos para los que debe estar presente una palabra.normase establece enl2para asegurar que todos nuestros vectores de características tengan una norma euclidiana de 1.ngram_rangese establece en(1, 2)para indicar que queremos considerar los unigramas y los bigrams.stop_wordsse establece en"english"para eliminar todos los pronombres comunes ("a""the"…) para reducir la cantidad de funciones ruidosas
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, norm='l2', encoding='latin-1', ngram_range=(1, 2), stop_words='english')
features = tfidf.fit_transform(df.Consumer_complaint_narrative).toarray()
labels = df.category_id
features.shape
(4569, 12633)
Ahora, cada una de las 4569 narrativas de quejas del consumidor está representada por 12633 funciones, que representan la puntuación tf-idf para diferentes unigrams y bigrams.
Podemos usar de sklearn: sklearn.feature_selection.chi2 para encontrar los términos que están más correlacionados con cada uno de los productos:
from sklearn.feature_selection import chi2
import numpy as np
N = 2
for Product, category_id in sorted(category_to_id.items()):
features_chi2 = chi2(features, labels == category_id)
indices = np.argsort(features_chi2[0])
feature_names = np.array(tfidf.get_feature_names())[indices]
unigrams = [v for v in feature_names if len(v.split(' ')) == 1]
bigrams = [v for v in feature_names if len(v.split(' ')) == 2]
print("# '{}':".format(Product))
print(" . Most correlated unigrams:\n. {}".format('\n. '.join(unigrams[-N:])))
print(" . Most correlated bigrams:\n. {}".format('\n. '.join(bigrams[-N:])))
# ‘ De la cuenta bancaria o servicio ‘:
- Unigramas más correlacionados:
- bank
- overdraft
- Bigramas más correlacionados:
- overdraft fees
- checking account
‘# créditos de consumo ‘:
- Unigramas más correlacionados:
- car
- vehicle
- Bigramas más correlacionados:
- vehicle xxxx
- toyota financial
# ‘ tarjeta de crédito ‘:
- Unigramas más correlacionados:
- citi
- card
- Bigramas más correlacionados:
- annual fee
- credit card
# ‘ de informes de crédito ‘:
- Unigramas más correlacionados:
- experian
- equifax
- Bigramas más correlacionados:
- trans union
- credit report
# ‘ El cobro de deudas ‘:
- Unigramas más correlacionados:
- collection
- debt
- Bigramas más correlacionados:
- collect debt
- collection agency
# ‘ de Dinero ‘:
- Unigramas más correlacionados:
- wu
- paypal
- Bigramas más correlacionados:
- western union
- money transfer
# ‘ hipoteca ‘:
- Unigramas más correlacionados:
- modification
- mortgage
- Bigramas más correlacionados:
- mortgage company
- loan modification
# ‘ Otros servicios financieros ‘:
- Unigramas más correlacionados:
- dental
- passport
- Bigramas más correlacionados:
- help pay
- stated pay
# ‘ día de pago de préstamo ‘:
- Unigramas más correlacionados:
- borrowed
- payday
- Bigramas más correlacionados:
- big picture
- payday loan
# ‘ tarjeta de prepago ‘:
- Unigramas más correlacionados:
- serve
- prepaid
- Bigramas más correlacionados:
- access money
- prepaid card
# ‘ de préstamos estudiantiles ‘:
- Unigramas más correlacionados:
- student
- navient
- Bigramas más correlacionados:
- student loans
- student loan
# ‘ moneda virtual ‘:
- Unigramas más correlacionados:
- handles
- https
- Bigramas más correlacionados:
- xxxx provider
- money want
Todos tienen sentido, ¿no crees?
Clasificador de clases múltiples: características y diseño
- Para entrenar clasificadores supervisados, primero transformamos la “narrativa de quejas del consumidor” en un vector de números. Exploramos las representaciones de vectores como vectores ponderados TF-IDF.
- Después de tener estas representaciones de vectores del texto, podemos entrenar clasificadores supervisados para entrenar “narrativa de quejas del consumidor” invisible y predecir el “producto” en el que caen.
Después de toda la transformación de datos anterior, ahora que tenemos todas las características y etiquetas, es hora de entrenar a los clasificadores. Hay varios algoritmos que podemos usar para este tipo de problema.
Naive Bayes Classifier : el más adecuado para conteos de palabras es la variante multinomial:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
X_train, X_test, y_train, y_test = train_test_split(df['Consumer_complaint_narrative'], df['Product'], random_state = 0)
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(X_train)
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
clf = MultinomialNB().fit(X_train_tfidf, y_train)
Después de ajustar el conjunto de entrenamiento, hagamos algunas predicciones.
print(clf.predict(count_vect.transform(["This company refuses to provide me verification and validation of debt per my right under the FDCPA. I do not believe this debt is mine."])))
per my right under the FDCPA. I do not believe this debt is mine."])))
[‘Debt collection’]
df[df['Consumer_complaint_narrative'] == "This company refuses to provide me verification and validation of debt per my right under the FDCPA. I do not believe this debt is mine."]

print(clf.predict(count_vect.transform(["I am disputing the inaccurate information the Chex-Systems has on my credit report. I initially submitted a police report on XXXX/XXXX/16 and Chex Systems only deleted the items that I mentioned in the letter and not all the items that were actually listed on the police report. In other words they wanted me to say word for word to them what items were fraudulent. The total disregard of the police report and what accounts that it states that are fraudulent. If they just had paid a little closer attention to the police report I would not been in this position now and they would n't have to research once again. I would like the reported information to be removed : XXXX XXXX XXXX"])))
[‘Credit reporting’]
df[df['Consumer_complaint_narrative'] == "I am disputing the inaccurate information the Chex-Systems has on my credit report. I initially submitted a police report on XXXX/XXXX/16 and Chex Systems only deleted the items that I mentioned in the letter and not all the items that were actually listed on the police report. In other words they wanted me to say word for word to them what items were fraudulent. The total disregard of the police report and what accounts that it states that are fraudulent. If they just had paid a little closer attention to the police report I would not been in this position now and they would n't have to research once again. I would like the reported information to be removed : XXXX XXXX XXXX"]

¡No tan mal!
Selección de modelo
Ahora estamos listos para experimentar con otra máquina aprender modelos, evaluar su precisión y encontrar la fuente de cualquier problema potencial.
Haremos una evaluación comparativa de los siguientes cuatro modelos, para ello utilizamos sklearn:
- Regresión logística
- (Multinomial) Naive Bayes
- Máquina lineal de soporte vectorial
- Bosque aleatorio
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.model_selection import cross_val_score
models = [
RandomForestClassifier(n_estimators=200, max_depth=3, random_state=0),
LinearSVC(),
MultinomialNB(),
LogisticRegression(random_state=0),
]
CV = 5
cv_df = pd.DataFrame(index=range(CV * len(models)))
entries = []
for model in models:
model_name = model.__class__.__name__
accuracies = cross_val_score(model, features, labels, scoring='accuracy', cv=CV)
for fold_idx, accuracy in enumerate(accuracies):
entries.append((model_name, fold_idx, accuracy))
cv_df = pd.DataFrame(entries, columns=['model_name', 'fold_idx', 'accuracy'])
import seaborn as sns
sns.boxplot(x='model_name', y='accuracy', data=cv_df)
sns.stripplot(x='model_name', y='accuracy', data=cv_df,
size=8, jitter=True, edgecolor="gray", linewidth=2)
plt.show()

cv_df.groupby('model_name').accuracy.mean()
model_name
LinearSVC: 0.822890
LogisticRegression: 0.792927
MultinomialNB: 0.688519
RandomForestClassifier: 0.443826
Nombre: accuracy, dtype: float64
LinearSVC y Regresión logística funcionan mejor que los otros dos clasificadores, con LinearSVC teniendo una ligera ventaja con un mediana de precisión de alrededor del 82%.
Evaluación del modelo
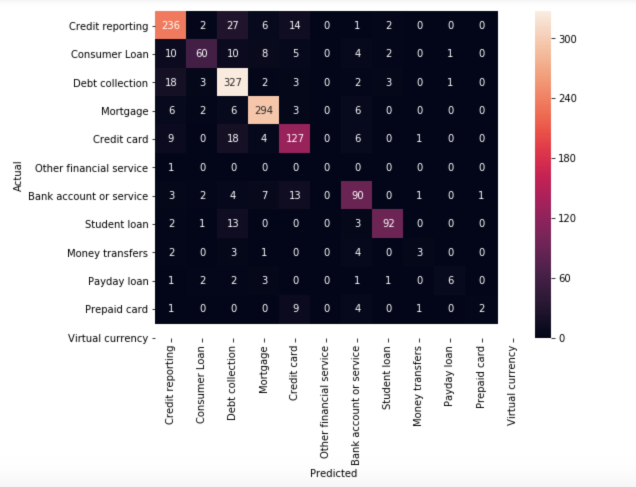
Continuar con nuestro mejor modelo (LinearSVC), vamos a ver la matriz de confusión y mostrar las discrepancias entre las etiquetas predichas y reales (utlizamos sklearn.metrics).
model = LinearSVC()
X_train, X_test, y_train, y_test, indices_train, indices_test = train_test_split(features, labels, df.index, test_size=0.33, random_state=0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import confusion_matrix
conf_mat = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(conf_mat, annot=True, fmt='d',
xticklabels=category_id_df.Product.values, yticklabels=category_id_df.Product.values)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.show()

La gran mayoría de las predicciones terminan en la diagonal (etiqueta pronosticada = etiqueta real), donde queremos que estén.
Sin embargo, hay una serie de clasificaciones erróneas, y podría ser interesante ver cuáles son causadas por:
from IPython.display import display
for predicted in category_id_df.category_id:
for actual in category_id_df.category_id:
if predicted != actual and conf_mat[actual, predicted] >= 10:
print("'{}' predicted as '{}' : {} examples.".format(id_to_category[actual], id_to_category[predicted], conf_mat[actual, predicted]))
display(df.loc[indices_test[(y_test == actual) & (y_pred == predicted)]][['Product', 'Consumer_complaint_narrative']])
print('')


Como puede ver, algunas de las quejas mal clasificadas son quejas que afectan a más de un tema (por ejemplo, quejas que involucran tanto la tarjeta de crédito como el informe crediticio) . Este tipo de errores siempre ocurrirá.
De nuevo, usamos el chi-squared test para encontrar los términos que están más correlacionados con cada una de las categorías:
model.fit(features, labels)
N = 2
for Product, category_id in sorted(category_to_id.items()):
indices = np.argsort(model.coef_[category_id])
feature_names = np.array(tfidf.get_feature_names())[indices]
unigrams = [v for v in reversed(feature_names) if len(v.split(' ')) == 1][:N]
bigrams = [v for v in reversed(feature_names) if len(v.split(' ')) == 2][:N]
print("# '{}':".format(Product))
print(" . Top unigrams:\n . {}".format('\n . '.join(unigrams)))
print(" . Top bigrams:\n . {}".format('\n . '.join(bigrams)))
# ‘ De la cuenta bancaria o servicio ‘:
- Top unigramas:
- bank
- account
- Top bigramas:
- debit card
- overdraft fees
# ‘ créditos de consumo ‘:
- Top unigramas:
- vehicle
- car
- Top bigramas:
- personal loan
- history xxxx
‘# tarjeta de crédito ‘:
- Top unigramas:
- card
- discover
- Top bigramas:
- credit card
- discover card
# ‘ de informes de crédito ‘:
- Top unigramas:
- equifax
- transunion
- Top bigramas:
- xxxx account
- trans union
# ‘ El cobro de deudas ‘:
- Top unigramas:
- debt
- collection
- Top bigramas:
- account credit
- time provided
# ‘Transferencias de Dinero ‘:
- Top unigramas:
- paypal
- transfer
- Top bigramas:
- money transfer
- send money
# ‘ hipoteca ‘:
- Top unigramas:
- mortgage
- escrow
- Top bigramas:
- loan modification
- mortgage company
# ‘ Otros servicios financieros ‘:
- Top unigramas:
- passport
- dental
- Top bigramas:
- stated pay
- help pay
# ‘ día de pago de préstamo ‘:
- Top unigramas:
- payday
- loan
- Top bigramas:
- payday loan
- pay day
# ‘ tarjeta de prepago ‘:
- Top unigramas:
- prepaid
- serve
- Top bigramas:
- prepaid card
- use card
# ‘ de préstamos estudiantiles ‘:
- Top unigramas:
- navient
- loans
- Top bigramas:
- student loan
- sallie mae
# ‘ moneda virtual ‘:
- Top unigramas:
- https
- tx
- Top bigramas:
- money want
- xxxx provider
Son consistentes dentro de nuestras expectativas.
Finalmente , usando sklearn imprimimos el informe de clasificación para cada clase:
from sklearn import metrics
print(metrics.classification_report(y_test, y_pred, target_names=df['Product'].unique()))

El código fuente se puede encontrar en Github . Espero con interés escuchar cualquier comentario o pregunta.
Bio: Susan Li está cambiando el mundo, un artículo a la vez. Ella es una científica sénior de datos, ubicada en Toronto, Canadá.
Original . Repostado con permiso.