
En esta publicación, comparto algunas de mis exploraciones con TPOT una herramienta de machine learning de máquinas (autoML) en Python.
El objetivo es ver lo que TPOT puede hacer y si merece convertirse en parte de su flujo de trabajo de machine learning.
Machine learning no reemplaza al científico de datos, (al menos no todavía) pero podría ayudarlo a encontrar buenos modelos más rápido. TPOT se considera a sí mismo como su Asistente de Ciencia de Datos.
TPOT está destinado a ser un asistente que le brinda ideas sobre cómo resolver un problema particular de aprendizaje de máquinas al explorar configuraciones de pipelines que quizás nunca haya considerado, luego deja el ajuste fino para técnicas de optimización de parámetros más restringidas, como la búsqueda de grillas.
Así que TPOT lo ayuda a encontrar buenos algoritmos. Tenga en cuenta que no está diseñado para automatizar el deep learning, algo así como AutoKeras podría ser útil allí.
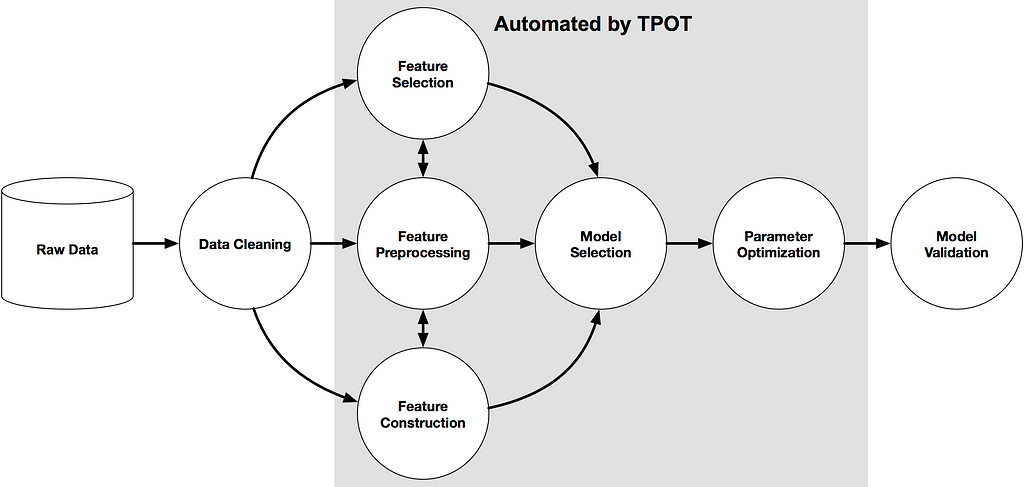
TPOT se basa en la biblioteca scikit learn y sigue el scikit aprende de cerca. Se puede usar para tareas de regresión y clasificación y tiene implementaciones especiales para investigación médica.
TPOT es de código abierto, está bien documentado y en desarrollo activo. Su desarrollo fue encabezado por investigadores de la Universidad de Pensilvania. TPOT parece ser una de las bibliotecas autoML más populares, con casi 4.500 estrellas GitHub a partir de agosto de 2018.
¿Cómo funciona TPOT?
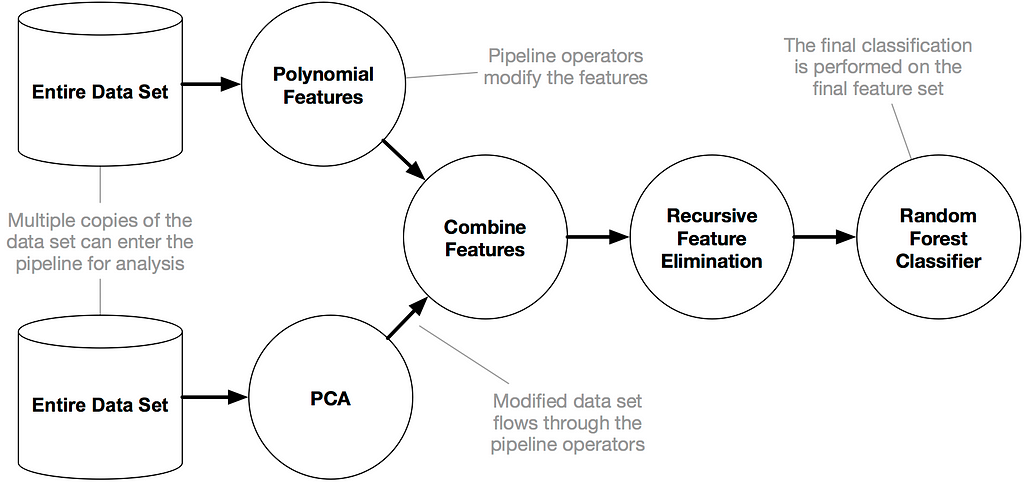
TPOT tiene lo que sus desarrolladores llaman un algoritmo de búsqueda genética para encontrar los mejores parámetros y conjuntos de modelos.
También podría considerarse como una selección natural o algoritmo evolutivo. TPOT prueba una pipeline, evalúa su rendimiento y cambia aleatoriamente partes de la pipeline en busca de algoritmos de mejor rendimiento.
Los algoritmos de machine learning no son tan simples como ajustar un modelo en el conjunto de datos. Están considerando múltiples algoritmos de machine learning (bosques aleatorios, modelos lineales, SVM, etc.).
En una pipeline con múltiples pasos de preprocesamiento (imputación de valor faltante, escalado, PCA, selección de características, etc.).
Los hiperparámetros para todos los modelos y pasos de preprocesamiento. Así como múltiples formas de agrupar o apilar los algoritmos dentro de la canalización. (fuente: documentos de TPOT )
Este poder de TPOT proviene de la evaluación de todo tipo de pipelines posibles de forma automática y eficiente. Hacer esto manualmente es engorroso y más lento.
Ejecutando TPOT
La creación de instancias, ajuste y score del clasificador TPOT es similar a cualquier otro clasificador sklearn. Aquí está el formato:
tpot = TPOTClassifier() tpot.fit(X_train, y_train) tpot.score(X_test, y_test)
TPOT viene con su propia variación de una codificación en caliente. Tenga en cuenta que podría agregarlo a una canalización automáticamente porque trata las características con menos de 10 valores únicos como categóricos . Si desea usar su propia estrategia de codificación, puede codificar sus datos y luego alimentarlo a TPOT.
Puede elegir el criterio de score para tpot.score (aunque un error con Jupyter y múltiples núcleos de procesador) le impide tener un criterio de score personalizado con múltiples núcleos de procesador en un portátil Jupyter).
Parece que no puede alterar los criterios de score que TPOT utiliza internamente, ya que busca la mejor interconexión. Solo los criterios de score para su uso en el conjunto de pruebas después de que TPOT haya elegido los mejores algoritmos.
Esta es un área donde algunos usuarios pueden querer más control. Tal vez esta opción se agregará en una versión futura.
TPOT escribe información sobre el algoritmo de mejor rendimiento y su puntaje de precisión en un archivo con tpot.export ().
Puede elegir el nivel de verbosidad que desea ver a medida que TPOT se ejecuta y hacer que escriba pipelines en un archivo de salida tal como se ejecuta en caso de que finalice temprano por algún motivo (por ejemplo, sus fallas Kaggle Kernel).
¿Cuánto dura TPOT? tomar para ejecutar?

La respuesta corta es que depende.
TPOT fue diseñado para funcionar por un tiempo, horas o incluso un día. Aunque los problemas menos complejos con conjuntos de datos más pequeños pueden obtener excelentes resultados en minutos.
Puede ajustar varios parámetros para que TPOT finalice sus búsquedas más rápido. Pero a expensas de una búsqueda menos exhaustiva para una canalización óptima.
No fue diseñado para ser una búsqueda exhaustiva de pasos de preprocesamiento, selección de características, algoritmos y parámetros. Pero puede acercarse si establece sus parámetros para que sean más exhaustivos.
Como explican los documentos:
… TPOT tomará un tiempo en ejecutar en conjuntos de datos más grandes. Pero es importante darse cuenta de por qué.
Con las configuraciones predeterminadas de TPOT (100 generaciones con 100 tamaños de población); TPOT evaluará 10.000 configuraciones de pipelines antes de finalizar.
Para poner este número en contexto, piense en una búsqueda en cuadrícula de 10,000 combinaciones de hiperparámetros para un algoritmo de machine learning y cuánto tiempo llevará esa búsqueda en la grilla.
Se trata de 10.000 configuraciones de modelos para evaluar con una validación cruzada de 10 veces. Lo que significa que aproximadamente 100.000 modelos se ajustan y evalúan en los datos de capacitación en una búsqueda de cuadrícula.
Algunos de los conjuntos de datos que veremos a continuación solo necesitan una unos minutos para encontrar algoritmos que tengan un buen score; otros pueden necesitar días.
Estos son los parámetros predeterminados de TPOTClassifier:
generations=100, population_size=100, offspring_size=None # Jeff notes this gets set to population_size mutation_rate=0.9, crossover_rate=0.1, scoring="Accuracy", # for Classification cv=5, subsample=1.0, n_jobs=1, max_time_mins=None, max_eval_time_mins=5, random_state=None, config_dict=None, warm_start=False, memory=None, periodic_checkpoint_folder=None, early_stop=None verbosity=0 disable_update_check=False
Se puede encontrar una descripción de cada parámetro documentos . Aquí hay algunas claves que determinan el número de pipelines por las que TPOT buscará:
generations: int, optional (default: 100) Number of iterations to the run pipeline optimization process. Generally, TPOT will work better when you give it more generations(and therefore time) to optimize the pipeline.
TPOT will evaluate POPULATION_SIZE + GENERATIONS x OFFSPRING_SIZE pipelines in total (emphasis mine).
population_size: int, optional (default: 100) Number of individuals to retain in the GP population every generation. Generally, TPOT will work better when you give it more individuals (and therefore time) to optimize the pipeline.
offspring_size: int, optional (default: None) Number of offspring to produce in each GP generation. By default, offspring_size = population_size.
Al comenzar con TPOT vale la pena establecer verbosity = 3 y periodic_checkpoint_folder = “any_string_you_like” para que pueda ver los modelos evolucionar y los puntajes de entrenamiento mejoran.
Verá algunos errores ya que algunas combinaciones de elementos de canalización son incompatibles, pero no se preocupe.
Si está ejecutando en varios núcleos y no está utilizando una función de score personalizada, configure n_jobs = -1 para usar todos los recursos disponibles. núcleos y acelerar TPOT.
Espacio de búsqueda
Estos son los algoritmos y parámetros de clasificación que TPOT elige de la versión 0.9:
‘sklearn.naive_bayes.BernoulliNB’: { ‘alpha’: [1e-3, 1e-2, 1e-1, 1., 10., 100.], ‘fit_prior’: [True, False] },
‘sklearn.naive_bayes.MultinomialNB’: { ‘alpha’: [1e-3, 1e-2, 1e-1, 1., 10., 100.], ‘fit_prior’: [True, False] },
‘sklearn.tree.DecisionTreeClassifier’: { ‘criterion’: [“gini”, “entropy”], ‘max_depth’: range(1, 11), ‘min_samples_split’: range(2, 21), ‘min_samples_leaf’: range(1, 21) },
‘sklearn.ensemble.ExtraTreesClassifier’: { ‘n_estimators’: [100], ‘criterion’: [“gini”, “entropy”], ‘max_features’: np.arange(0.05, 1.01, 0.05), ‘min_samples_split’: range(2, 21), ‘min_samples_leaf’: range(1, 21), ‘bootstrap’: [True, False] },
‘sklearn.ensemble.RandomForestClassifier’: { ‘n_estimators’: [100], ‘criterion’: [“gini”, “entropy”], ‘max_features’: np.arange(0.05, 1.01, 0.05), ‘min_samples_split’: range(2, 21), ‘min_samples_leaf’: range(1, 21), ‘bootstrap’: [True, False] },
‘sklearn.ensemble.GradientBoostingClassifier’: { ‘n_estimators’: [100], ‘learning_rate’: [1e-3, 1e-2, 1e-1, 0.5, 1.], ‘max_depth’: range(1, 11), ‘min_samples_split’: range(2, 21), ‘min_samples_leaf’: range(1, 21), ‘subsample’: np.arange(0.05, 1.01, 0.05), ‘max_features’: np.arange(0.05, 1.01, 0.05) },
‘sklearn.neighbors.KNeighborsClassifier’: { ‘n_neighbors’: range(1, 101), ‘weights’: [“uniform”, “distance”], ‘p’: [1, 2] },
‘sklearn.svm.LinearSVC’: { ‘penalty’: [“l1”, “l2”], ‘loss’: [“hinge”, “squared_hinge”], ‘dual’: [True, False], ‘tol’: [1e-5, 1e-4, 1e-3, 1e-2, 1e-1], ‘C’: [1e-4, 1e-3, 1e-2, 1e-1, 0.5, 1., 5., 10., 15., 20., 25.] },
‘sklearn.linear_model.LogisticRegression’: { ‘penalty’: [“l1”, “l2”], ‘C’: [1e-4, 1e-3, 1e-2, 1e-1, 0.5, 1., 5., 10., 15., 20., 25.], ‘dual’: [True, False] },
‘xgboost.XGBClassifier’: { ‘n_estimators’: [100], ‘max_depth’: range(1, 11), ‘learning_rate’: [1e-3, 1e-2, 1e-1, 0.5, 1.], ‘subsample’: np.arange(0.05, 1.01, 0.05), ‘min_child_weight’: range(1, 21), ‘nthread’: [1] }
Y TPOT puede apilar clasificadores, incluido el mismo clasificador varias veces.
Uno de los desarrolladores principales de TPOT explica cómo funciona en este problema :
El pipeline:
ExtraTreesClassifier (ExtraTreesClassifier (input_matrix, True, & # 039; entropy & # 039 ;, 0.10000000000000001, 13, 6), True, & # 039; gini & # 039 ;, 0.75, 17, 4)
Hace lo siguiente:
- Ajusta todas las características originales usando un ExtraTreesClassifier
- Toma las predicciones de ese ExtraTreesClassifier y cree una nueva característica que usa esas predicciones
- Pasa las características originales más la nueva “característica pronosticada” al 2 ° ExtraTreesClassifier y use sus predicciones como las predicciones finales de la pipeline
Este proceso se denomina clasificadores de apilamiento, es una táctica bastante común en machine learning.
Y aquí están los 11 preprocesadores que podrían ser aplicados por TPOT a partir de la versión 0.9.
‘sklearn.preprocessing.Binarizer’: { ‘threshold’: np.arange(0.0, 1.01, 0.05) },
‘sklearn.decomposition.FastICA’: { ‘tol’: np.arange(0.0, 1.01, 0.05) },
‘sklearn.cluster.FeatureAgglomeration’: { ‘linkage’: [‘ward’, ‘complete’, ‘average’], ‘affinity’: [‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’, ‘cosine’] },
‘sklearn.preprocessing.MaxAbsScaler’: { },
‘sklearn.preprocessing.MinMaxScaler’: { },
‘sklearn.preprocessing.Normalizer’: { ‘norm’: [‘l1’, ‘l2’, ‘max’] },
‘sklearn.kernel_approximation.Nystroem’: { ‘kernel’: [‘rbf’, ‘cosine’, ‘chi2’, ‘laplacian’, ‘polynomial’, ‘poly’, ‘linear’, ‘additive_chi2’, ‘sigmoid’], ‘gamma’: np.arange(0.0, 1.01, 0.05), ‘n_components’: range(1, 11) },
‘sklearn.decomposition.PCA’: { ‘svd_solver’: [‘randomized’], ‘iterated_power’: range(1, 11) }, ‘sklearn.preprocessing.PolynomialFeatures’: { ‘degree’: [2], ‘include_bias’: [False], ‘interaction_only’: [False] },
‘sklearn.kernel_approximation.RBFSampler’: { ‘gamma’: np.arange(0.0, 1.01, 0.05) }, ‘sklearn.preprocessing.RobustScaler’: { },
‘sklearn.preprocessing.StandardScaler’: { }, ‘tpot.builtins.ZeroCount’: { },
‘tpot.builtins.OneHotEncoder’: { ‘minimum_fraction’: [0.05, 0.1, 0.15, 0.2, 0.25], ‘sparse’: [False] } (emphasis mine)
El número de combinaciones parece ser casi infinito: puede apilar algoritmos, incluidas instancias del mismo algoritmo.
Puede haber un límite interno en el número de pasos en la pipeline, pero basta con decir que hay una plétora de posibles canalizaciones.
Es probable que TPOT no genere la misma selección de algoritmo si lo ejecuta dos veces (tal vez ni siquiera estado_aleatorio está establecido, lo encontré, como se explica a continuación).
Como explica documentos :
Si está trabajando con un conjunto de datos razonablemente complejo o ejecuta TPOT durante un corto período de tiempo. Las diferentes ejecuciones de TPOT pueden dar como resultado diferentes recomendaciones de canalización.
El algoritmo de optimización de TPOT es de naturaleza estocástica, lo que significa que usa aleatoriedad (en parte) para buscar en el posible espacio de interconexión.
Cuando dos ejecuciones de TPOT recomiendan pipelines diferentes, esto significa que las ejecuciones de TPOT no convergieron debido a la falta de tiempo o de que varias pipelines realizan más o menos lo mismo en su conjunto de datos.
Menos conversación, más acción. ¡Probemos TPOT en algunos datos!
Conjunto de datos 1: Clasificación de dígitos MNIST
Primero veremos una tarea de clasificación: la tarea popular de clasificación de dígitos a mano de MNIST incluida en los conjuntos de datos de sklearn . La base de datos MNIST contiene 70,000 imágenes de dígitos árabes escritos a mano en 28×28 píxeles, etiquetados de 0 a 9.
TPOT viene de serie en la imagen Kaggle Docker, por lo que solo tiene que importarlo si está usando Kaggle, no lo hace necesito instalarlo.
Aquí está mi código – disponible en este Kaggle Kernel en una forma ligeramente diferente y posiblemente con algunas modificaciones.
# import the usual stuff import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import os
# import TPOT and sklearn stuff from tpot import TPOTClassifier from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split import sklearn.metrics
# create train and test sets digits = load_digits() X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75, test_size=0.25, random_state=34)
tpot = TPOTClassifier(verbosity=3,
scoring="balanced_accuracy",
random_state=23,
periodic_checkpoint_folder="tpot_mnst1.txt",
n_jobs=-1,
generations=10,
population_size=100)
# run three iterations and time them
for x in range(3):
start_time = timeit.default_timer()
tpot.fit(X_train, y_train)
elapsed = timeit.default_timer() - start_time
times.append(elapsed)
winning_pipes.append(tpot.fitted_pipeline_)
scores.append(tpot.score(X_test, y_test))
tpot.export('tpot_mnist_pipeline.py')
times = [time/60 for time in times]
print('Times:', times)
print('Scores:', scores)
print('Winning pipelines:', winning_pipes)
Como se mencionó anteriormente, el número total de pipelines es igual a POPULATION_SIZE + GENERATIONS x OFFSPRING_SIZE.
Por ejemplo, si establece population_size = 20 y generations = 5, entonces offspring_size = 20 (porque offspring_size es igual a population_size por defecto. Y tendrá un total de 120 canalizaciones porque 20 + (5 * 20) = 120.
Puede ver que no requiere mucho código para ejecutar este conjunto de datos, y eso incluye un bucle a tiempo y pruébalo repetidamente.
Con 10 clases posibles y sin razón para preferir un resultado a otro, la precisión (la clasificación predeterminada de TPOT) es una métrica precisa para esta tarea.
Aquí está la sección del código relevante.
digits = load_digits() X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75, test_size=0.25, random_state=34)
tpot = TPOTClassifier(verbosity=3, scoring=”accuracy”, random_state=32, periodic_checkpoint_folder=”tpot_results.txt”, n_jobs=-1, generations=5, population_size=10, early_stop=5)
Y aquí están los resultados:
Times: [4.740584810283326, 3.497970838083226, 3.4362493358499098] Scores: [0.9733333333333334, 0.9644444444444444, 0.9666666666666667]
Winning pipelines: [
Pipeline(memory=None,
steps=[('gradientboostingclassifier', GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.1, loss='deviance', max_depth=7,
max_features=0.15000000000000002, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
...auto', random_state=None,
subsample=0.9500000000000001, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('gradientboostingclassifier', GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=0.15000000000000002, max_leaf_...auto', random_state=None,
subsample=0.9500000000000001, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('gradientboostingclassifier', GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=0.15000000000000002, max_leaf_...auto', random_state=None,
subsample=0.9500000000000001, verbose=0, warm_start=False))])]
Tenga en cuenta que solo 60 pipelines, mucho menos de lo que TPOT sugiere. Pudimos ver scores bastante buenas, más del 97% de precisión en el conjunto de pruebas en un caso.
Reproducibilidad
¿TPOT encuentra la misma pipeline ganadora cada vez con el mismo conjunto de estado_aleatorio?.
No necesariamente. Los algoritmos individualmente como RandomForrestClassifier () tienen sus propios parámetros de estado_aleatorio que no se establecen.
TPOT no siempre encuentra el mismo resultado si crea una instancia de un clasificador y luego lo ajusta repetidamente como lo hacemos en para repite el ciclo en el código anterior.
Ejecuté tres conjuntos muy pequeños de 60 pipelines con conjunto de estado_aleatorio y la configuración de la GPU de Kaggle. Tenga en cuenta que obtenemos pipelines ligeramente diferentes y, por lo tanto, score de conjuntos de pruebas ligeramente diferentes en los tres conjuntos de pruebas.
Aquí hay otro ejemplo de una pequeña cantidad de pipelines con un estado aleatorio configurado y utilizando la configuración de CPU de Kaggle.
Times: [2.8874817832668973, 0.043678393283335025, 0.04388708711679404] Scores: [0.9622222222222222, 0.9622222222222222, 0.9622222222222222] Winning pipelines: [
Pipeline(memory=None,
steps=[('gradientboostingclassifier', GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=0.15000000000000002, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
....9500000000000001, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('gradientboostingclassifier', GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=0.15000000000000002, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
....9500000000000001, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('gradientboostingclassifier', GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.5, loss='deviance', max_depth=2,
max_features=0.15000000000000002, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
....9500000000000001, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False))])]
La misma canalización fue encontrado cada una de las tres veces.
Tenga en cuenta que el tiempo de ejecución es mucho más rápido después de th e primera iteración. TPOT parece recordar cuándo ha visto un algoritmo y no lo vuelve a ejecutar.
Incluso si es un segundo ajuste y ha configurado memory = False. Esto es lo que verá si establece la verbosidad = 3 cuando encuentra una interconexión previamente evaluada:
Pipeline encountered that has previously been evaluated during the optimization process. Using the score from the previous evaluation.
Carreras más largas para mayor precisión
¿Cómo funciona TPOT si usted hace una gran cantidad de pipelines? Para realmente ver el poder de TPOT para la tarea de dígitos MNIST, necesita más de 500 canalizaciones totales para ejecutarse.
Esto llevará al menos una hora si lo ejecutas en Kaggle. Luego verá scores de mayor precisión y podría ver modelos más complejos.
Los conjuntos encadenados o apilados donde las salidas de un algoritmo de machine learning alimentan a otro son lo que probablemente verá si tiene un mayor número de pipelines y una tarea no trivial.
0.9950861171999883
knn = KNeighborsClassifier(
DecisionTreeClassifier(
OneHotEncoder(input_matrix, OneHotEncoder__minimum_fraction=0.15, OneHotEncoder__sparse=False),
DecisionTreeClassifier__criterion=gini,
DecisionTreeClassifier__max_depth=5,
DecisionTreeClassifier__min_samples_leaf=20,
DecisionTreeClassifier__min_samples_split=17),
KNeighborsClassifier__n_neighbors=1,
KNeighborsClassifier__p=2,
KNeighborsClassifier__weights=distance)
Este es el score promedio de CV de .995. después de correr por ov una hora y generando más de 600 pipelines. El kernel se colgó antes de completarse. Así que no pude ver un puntaje de prueba y no pude obtener un modelo de salida, pero esto parece bastante prometedor para TPOT.
El algoritmo utiliza un DecisionTreeClassifier con la alimentación de codificaciones categóricas OneHotEncoder de TPOT en KNeighborsClassifier.
Aquí hay un puntaje interno similar con una pipelin diferente resultante de un estado_aleatorio diferente después de casi 800 pipelines.
0.9903723557310828
KNeighborsClassifier(Normalizer(OneHotEncoder(RandomForestClassifier(MinMaxScaler(input_matrix), RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=entropy, RandomForestClassifier__max_features=0.55, RandomForestClassifier__min_samples_leaf=6, RandomForestClassifier__min_samples_split=15, RandomForestClassifier__n_estimators=100), OneHotEncoder__minimum_fraction=0.2, OneHotEncoder__sparse=False), Normalizer__norm=max), KNeighborsClassifier__n_neighbors=4, KNeighborsClassifier__p=2, KNeighborsClassifier__weights=distance)
TPOT encontró una pipeline con KNN, una codificación en caliente, normalización y bosque aleatorio. Tardó dos horas y media. El anterior fue más rápido y obtuvo mejores puntajes, pero a veces eso es lo que sucede con la naturaleza estocástica del algoritmo de búsqueda genética de TPOT.
Retiros de la tarea de clasificación de dígitos MNIST
- TPOT puede funcionar muy bien en esta tarea de reconocimiento de imágenes si le da suficiente time.
- TPOT definitivamente funciona mejor con más pipelines.
- Si necesita resultados de reproducibilidad, TPOT podría ser la herramienta.
Conjunto de datos 2: Clasificación de hongos
Para un segundo conjunto de datos elegí el popular tarea de clasificación de hongos. El objetivo es determinar correctamente si un hongo es venenoso según sus etiquetas.
Esta no es una tarea de clasificación de imágenes. Está configurado como una tarea binaria para que todos los hongos potencialmente peligrosos se agrupen en una categoría y sean seguros para comer hongos como otra categoría.

Mi código está disponible en este Kaggle Kernel .
TPOT puede ajustarse de forma rutinaria a un modelo perfecto rápidamente en este conjunto de datos, en menos de dos minutos.
Este es un rendimiento y una velocidad mucho mejores que cuando probé este conjunto de datos sin TPOT con casi todos los algoritmos de clasificación de sklearn disponibles. Una amplia gama de codificaciones de datos nominales y sin ajuste de parámetros, usando la configuración de GPU de Kaggle.
En tres carreras con la misma instancia de TPOTClassifier y el estado aleatorio establecidos aquí es lo que encontró TPOT:
Times: [1.854785452616731, 1.5694829618000463, 1.3383520993001488] Scores: [1.0, 1.0, 1.0]
Curiosamente, encontró un algoritmo diferente cada vez. Encontró un DecisionTreeClassifier, KNeighorsClassifier y un Stacked RandomForestClassifier con BernoulliNB.
Profundicemos en la reproducibilidad un poco más. Vamos a ejecutarlo de nuevo con todo exactamente igual.
Times: [1.8664863013502326, 1.5520636909670429, 1.3386059726501116] Scores: [1.0, 1.0, 1.0]
Vemos el mismo conjunto de tres pipelines , tiempos muy similares y los mismos puntajes en el conjunto de prueba.
Ahora intentemos dividir la celda en varias celdas diferentes y crear una instancia de TPOT en cada una de ellas. Aquí está el código:
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, test_size=0.25, random_state=25)
tpot = TPOTClassifier(verbosity=3, scoring=”accuracy”, random_state=25, periodic_checkpoint_folder=”tpot_mushroom_results.txt”, n_jobs=-1, generations=5, population_size=10, early_stop = 5)
El resultado de la segunda ejecución ahora coincide con el resultado de la primera y tomó casi el mismo tiempo (score = 1.0, Tiempo = 1.9 minutos, pipeline = Clasificador de árbol de decisión).
La clave para una mayor reproducibilidad es que estamos instanciando una nueva instancia del clasificador TPOT en cada celda.
El tiempo resulta de 10 conjuntos de 30 pipelines con estado_aleatorio en tren_prueba_comprimida y TPOT establecido en 10 debajo.
Todas las pipelines clasificaron correctamente todas las setas en el conjunto de prueba. TPOT fue bastante rápido en esta tarea bastante fácil de aprender.
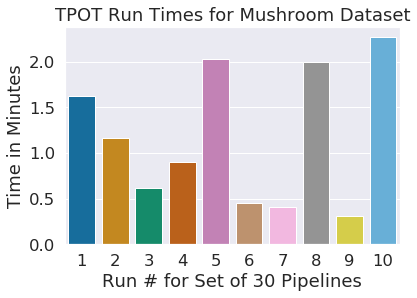
Takeaways from Mushroom Task
TPOT funciona muy bien muy rápido en esta tarea básica de clasificación.
Este kernel de Kaggle en el conjunto de hongos in R es muy agradable y explora una variedad de algoritmos y se acerca mucho a la precisión perfecta.
Pero no llega al 100% y ciertamente tomó bastante más tiempo prepararlo y capacitarlo que nuestra implementación de TPOT.
Considero que TPOT es un ahorro de tiempo para una tarea como esta en el futuro, en al menos como un primer paso.
Conjunto de datos 3: Predicción de vivienda de Ames
A continuación, volvemos a una tarea de regresión para ver cómo funciona TPOT. Predijaremos los valores de venta de propiedades de vivienda con el popular Ames, Iowa Housing Price Prediction dataset .

Mi código está disponible en este Kaggle Kernel .
Para esta tarea, primero hice una imputación básica de los valores perdidos. Rellené los valores de la columna numérica que falta con el valor más frecuente para la columna.
Porque algunas de esas columnas contienen datos ordinales. Con más tiempo clasificaría las columnas y usaría diferentes estrategias de imputación dependiendo de los tipos de datos de intervalo, ordinales o nominales.
Los valores faltantes de la columna de cadena se rellenaron con una etiqueta “faltante” antes de la codificación ordinal porque no todas las columnas tenían una valor más frecuente.
El algoritmo de codificación en caliente de TPOT generaría una dimensión más por función que indicaría que los datos tenían un valor faltante para esa característica.
TPOTRegressor usa la score medio de error al cuadrado por defecto.
Aquí hay una ejecución con solo 60 pipelines en primero con la CPU de Kaggle activada.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .25, random_state = 33)
# instantiate tpot
tpot = TPOTRegressor(verbosity=3,
random_state=25,
n_jobs=-1,
generations=5,
population_size=10,
early_stop = 5,
memory = None)
times = []
scores = []
winning_pipes = []
# run 3 iterations
for x in range(3):
start_time = timeit.default_timer()
tpot.fit(X_train, y_train)
elapsed = timeit.default_timer() - start_time
times.append(elapsed)
winning_pipes.append(tpot.fitted_pipeline_)
scores.append(tpot.score(X_test, y_test))
tpot.export('tpot_ames.py')
# output results
times = [time/60 for time in times]
print('Times:', times)
print('Scores:', scores)
print('Winning pipelines:', winning_pipes)
Los resultados de estas tres pequeñas series.
Times: [3.8920086714831994, 1.4063017464330188, 1.2469199204002508] Scores: [-905092886.3009057, -922269561.2683483, -949881926.6436856] Winning pipelines: [
Pipeline(memory=None,
steps=[('zerocount', ZeroCount()), ('xgbregressor', XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=9, min_child_weight=18, missing=None, n_estimators=100,
n_jobs=1, nthread=1, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=0.5))]),
Pipeline(memory=None,
steps=[('xgbregressor', XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=9, min_child_weight=11, missing=None, n_estimators=100,
n_jobs=1, nthread=1, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=0.5))]),
Pipeline(memory=None,
steps=[('stackingestimator', StackingEstimator(estimator=RidgeCV(alphas=array([ 0.1, 1. , 10. ]), cv=None, fit_intercept=True,
gcv_mode=None, normalize=False, scoring=None, store_cv_values=False))), ('maxabsscaler-1', MaxAbsScaler(copy=True)), ('maxabsscaler-2', MaxAbsScaler(copy=True)), ('xgbr... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=0.5))])]
Las carreras terminaron bastante rápido y encontraron diferentes líneas ganadoras cada vez. Es un poco difícil juzgar la calidad de scores. Tomar la raíz cuadrada de scores nos da el Error cuadrático medio (RMSE).
El RMSE tiene el mismo valor que la salida, por lo que estos resultados significan que las predicciones se redujeron en alrededor de $ 30,000 en promedio. Probar con 60 pipelines y un random_state = 20 para train_test_split y TPOTRegressor.
Times: [9.691357856966594, 1.8972856383004304, 2.5272325469001466] Scores: [-1061075530.3715296, -695536167.1288683, -783733389.9523941]
Winning pipelines: [
Pipeline(memory=None,
steps=[('stackingestimator-1', StackingEstimator(estimator=RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features=0.7000000000000001, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=12, min_sample...0.6000000000000001, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('xgbregressor', XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=7, min_child_weight=3, missing=None, n_estimators=100,
n_jobs=1, nthread=1, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1.0))]),
Pipeline(memory=None,
steps=[('stackingestimator', StackingEstimator(estimator=RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features=0.7000000000000001, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=12, min_samples_...ators=100, n_jobs=None,
oob_score=False, random_state=None, verbose=0, warm_start=False))])]
Condujo a pipelines y scores muy diferentes. Probemos una carrera más larga con 720 pipelines.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .25, random_state = 20)
tpot = TPOTRegressor(verbosity=3, random_state=10, #scoring=rmsle, periodic_checkpoint_folder=”any_string”, n_jobs=-1, generations=8, population_size=80, early_stop=5)
Resultados:
Times: [43.206709423016584]
Scores: [-644910660.5815958]
Winning pipelines: [Pipeline(memory=None,
steps=[('xgbregressor', XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=8, min_child_weight=3, missing=None, n_estimators=100,
n_jobs=1, nthread=1, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=0.8500000000000001))])]
RMSE es el mejor hasta el momento en 64,4910,661. Tardó la mayor parte de una hora en converger, y todavía estamos ejecutando pipelines mucho más pequeñas de lo recomendado.
A continuación, intentemos utilizar el error logarítmico de la media cuadrática. Un parámetro de score personalizado que Kaggle utiliza para esta competencia.
Esto se ejecutó en otra iteración muy pequeña con 30 pipelines en tres ejecuciones con random_state = 20. No pudimos usar más de un núcleo de CPU debido a un error con parámetros de score personalizados en Jupyter en algunos algoritmos incluidos en TPOT.
Times: [1.6125734224997965, 1.2910610851162345, 0.9708147236000514] Scores: [-0.15007242511943228, -0.14164770517342357, -0.15506057088945932] Winning pipelines: [
Pipeline(memory=None,
steps=[('maxabsscaler', MaxAbsScaler(copy=True)), ('stackingestimator', StackingEstimator(estimator=RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features=0.7000000000000001, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
...0.6000000000000001, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('extratreesregressor', ExtraTreesRegressor(bootstrap=False, criterion='mse', max_depth=None,
max_features=0.6500000000000001, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=7, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=None,
oob_score=False, random_state=None, verbose=0, warm_start=False))]),
Pipeline(memory=None,
steps=[('ridgecv', RidgeCV(alphas=array([ 0.1, 1. , 10. ]), cv=None, fit_intercept=True,
gcv_mode=None, normalize=False, scoring=None, store_cv_values=False))])]
Esos puntajes no son terribles. El archivo de salida de tpot.export de esta pequeña ejecución se encuentra a continuación.
import numpy as np import pandas as pd from sklearn.linear_model import ElasticNetCV, LassoLarsCV from sklearn.model_selection import train_test_split from sklearn.pipeline import make_pipeline, make_union from tpot.builtins import StackingEstimator
# NOTE: Make sure that the class is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1).values
training_features, testing_features, training_target, testing_target = train_test_split(features, tpot_data['target'].values, random_state=42)
# Score on the training set was:-0.169929041242275 exported_pipeline = make_pipeline( StackingEstimator(estimator=LassoLarsCV(normalize=False)), ElasticNetCV(l1_ratio=0.75, tol=0.01) exported_pipeline.fit(training_features, training_target) results = exported_pipeline.predict(testing_features)
Este código es lo que podría ejecutar y modificar para crear un archivo para hacer predicciones que podría usar en un concurso de Kaggle. Tenga en cuenta que si ejecuta TPOT en Kaggle, el archivo exportado solo se guarda cuando se confirma.
Me gustaría hacer algunas corridas más largas con TPOT en este conjunto de datos para ver cómo funciona. También me gustaría ver cómo la ingeniería de características manual y varias estrategias de codificación pueden mejorar el rendimiento de nuestro modelo.
Gotchas con TPOT y Kaggle
Me encantan los kernels de Kaggle, pero si quieres ejecutar un algoritmo como TPOT durante unas horas, puede ser muy frustrante.
Los núcleos se bloquean con frecuencia cuando se ejecutan, a veces no se puede saber si su intento de confirmación está bloqueado y no puede controlar su entorno tanto como le gustaría.

Nada como llegar a 700 de 720 iteraciones de pipelines y desconectar a Kaggle. Mi tasa de utilización de la CPU Kaggle a menudo mostraba un 400% y hubo muchos reinicios requeridos durante este ejercicio.
Algunas otras cosas a tener en cuenta:
- Descubrí que necesitaba convertir mi Pandas DataFrame en una Numpy Array para evitar un problema de XGBoost en la tarea de regresión. Este es un problema conocido con Pandas y XGBoost.
- Un núcleo Kaggle ejecuta un cuaderno Jupyter debajo del capó. Los clasificadores de score personalizados en TPOT no funcionan cuando n_jobs es> 1 en un cuaderno Jupyter. Este es un problema conocido.
- Kaggle solo permitirá que el código de tu kernel escriba en un archivo de salida cuando confirmes tu código. Y no puedes ver la salida temporal de TPOT cuando te comprometes. Asegúrese de que solo tiene el nombre del archivo entre comillas, sin barras diagonales. El archivo se mostrará en la pestaña Salida.
- Activar la configuración de GPU en Kaggle no aceleró las cosas para la mayoría de estos análisis. Pero sí lo haría para un aprendizaje profundo.
- Las 6 horas de tiempo de ejecución posibles de Kaggle y la configuración de la GPU hacen posible experimentar con TPOT de forma gratuita sin configuración en conjuntos de datos no enormes. Es difícil dejarlo libre.
Para más tiempo y velocidad puedes usar algo como Paperspace. Instalé TPOT en Paperspace y fue bastante libre de dolor, aunque no de dinero. Si necesita una solución en la nube para ejecutar TPOT, sugiero jugar con Kaggle primero y luego dejar Kaggle si necesita más de unas pocas horas de funcionamiento o más potencia.
Direcciones futuras
Hay muchas instrucciones interesantes para explorar con TPOT y autoML. Me gustaría comparar TPOT con autoSKlearn, MLBox, Auto-Keras y otros.
También me gustaría ver cómo funciona con una mayor variedad de datos, otras estrategias de imputación y otras estrategias de codificación.
Una comparación con LightGBM, CatBoost y los algoritmos de aprendizaje profundo también sería interesante. Lo emocionante de este momento en el aprendizaje automático es que hay muchas áreas para explorar.
Para la mayoría de los conjuntos de datos, todavía queda una gran cantidad de limpieza de datos, ingeniería de características y selección del modelo final. Por no mencionar el paso más importante de hacer las preguntas correctas por adelantado.
Entonces es posible que necesites producir tu modelo. Y TPOT no está haciendo búsquedas exhaustivas todavía.
Por lo tanto, TPOT no reemplazará el rol de científico de datos, pero esta herramienta podría hacer que sus algoritmos finales de aprendizaje automático sean más rápidos.
Si ha utilizado TPOT u otras herramientas de autoML, comparta su experiencia en los comentarios. ¡Gracias por leer!
TPOT Automated Machine Learning in Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.