
Hoy veremos algunas técnicas esenciales para manejar datos un poco más complejos que los ejemplos que he usado antes del sklearn, utilizando varias características de pandas.
Esta publicación le ayudará a organizar un conjunto de datos complejos que se ocupan de problemas de la vida real y, finalmente, trabajaremos a través de un ejemplo de regresión logística en los datos.
Puede descargar el archivo de datos con el nombre ‘bank.csv’ o de la fuente original donde también se encuentra disponible una descripción detallada del conjunto de datos.
Pandas en Machine Learning: Importando el set de datos
Antes de describir el archivo de datos, importémoslo la forma básica:
import pandas as pd bankdf = pd.read_csv('bank.csv',sep=';') # check the csv file before to know that 'comma' here is ';' print bankdf.head(3) print list(bankdf.columns)# show the features and label print bankdf.shape # instances vs features + label (4521, 17)
La salida es la siguiente:

En la salida, vemos que el conjunto de datos tiene 16 funciones y la etiqueta está designada con ‘y’ . Una descripción detallada de las características se proporciona en el repositorio principal.
El resumen del conjunto de datos que se encuentra en el repositorio principal es:
Los datos están relacionados con las campañas de marketing directo de una institución bancaria portuguesa. Las campañas de marketing se basaron en llamadas telefónicas. A menudo, se requería más de un contacto con el mismo cliente, para poder acceder si el producto (depósito a plazo bancario) estaba (“sí”) o no (“no”) suscrito.
Pandas en Machine Learning: Creando gráfico son seaborn.
Podemos producir un gráficoseabornde recuento para ver cómo una de las clases domina la salida:
import matplotlib.pyplot as plt import seaborn as sns sns.set(font_scale=1.5) countplt=sns.countplot(x='y', data=bankdf, palette ='hls') plt.show()
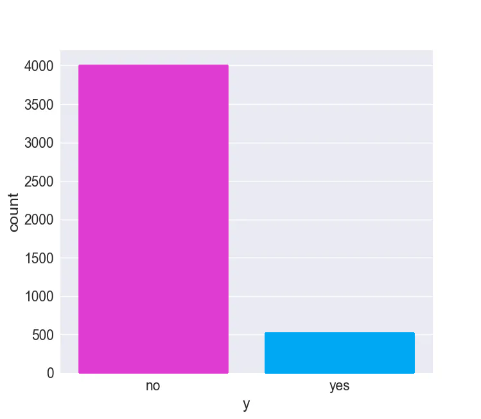
Podemos contar el número con el fragmento de código:
count_no_sub = len(bankdf[bankdf['y']=='no']) print count_no_sub >>> 4000
Dado que la etiqueta del conjunto de datos se da en términos de ‘sí’ y ‘no’, es necesario reemplazarlos con números, posiblemente con 1 y 0 respectivamente, para que puedan usarse en el modelado de los datos.
En el primer paso convertiremos las etiquetas de salida del conjunto de datos de cadenas binarias de sí / no a números enteros 1/0.
bankdf['y'] = (bankdf['y']=='yes').astype(int) # changing yes to 1 and no to 0 print bankdf['y'].value_counts() >>> 0 4000 1 521 Name: y, dtype: int64
Como las etiquetas de salida se convierten ahora en enteros, podemos usar la característica de grupo de pandas para investigar un poco más el conjunto de datos. Dependiendo de la etiqueta de salida (sí / no), podemos ver cómo varían los números en las características.
out_label = bankdf.groupby('y') print out_label.agg(np.mean)# above two lines can be written using a single line of code #print bankdf.groupby('y').mean() >>> age balance day duration campaign pdays previous y 0 40.99 1403.2117 15.948 226.347 2.862 36.006 0.471 1 42.49 1571.9558 15.658 552.742 2.266 68.639 1.090
Primero, aquí vemos solo 7 características, 16 Las características son objetos y no enteros o flotantes. Puede comprobarlo escribiendo bankdf.info().
Vemos que la función “duración”, que nos informa sobre la duración de la última llamada en segundos, es más del doble para los clientes que compraron los productos que para los clientes que no lo hicieron.
“Campaña”, que indica el número de llamadas realizadas durante la campaña actual, es menor para los clientes que compraron los productos. groupby puede darnos información importante sobre la relación entre características y etiquetas.
Los interesados pueden verificar una operación similar ‘groupby’ en ‘education’ para verificar que los clientes con educación terciaria tengan el ‘balance’ más alto (balance anual promedio en euros)!
Algunas de las características de los datos el conjunto tiene muchas categorías que pueden verificarse usando el método unique de un objeto series.
Los ejemplos son los siguientes:
print bankdf["education"].unique() print bankdf["marital"].unique() >>> ['primary' 'secondary' 'tertiary' 'unknown'] ['married' 'single' 'divorced']
Estas variables son conocidas como variables categóricas y en términos de pandas, estas se denominan “objeto”.
Para recuperar información utilizando las variables categóricas, necesitamos convertirlas en variables “ficticias” para que puedan usarse para el modelado. Lo hacemos utilizando la función pandas.get_dummies.
Primero creamos una lista de las variables categóricas:
cat_list = ['job','marital','education','default','housing','loan','contact','month','poutcome']
Luego convertimos estas variables en variables ficticias como abajo:
for ele in cat_list: add = pd.get_dummies(bankdf[ele], prefix=ele) bankdf1 = bankdf.join(add)# join columns with old dataframe bankdf = bankdf1 #print bankdf.head(3) #print bankdf.info()
Creamos variables ficticias para cada variable categórica e imprimimos el encabezado del nuevo marco de datos como se muestra a continuación:
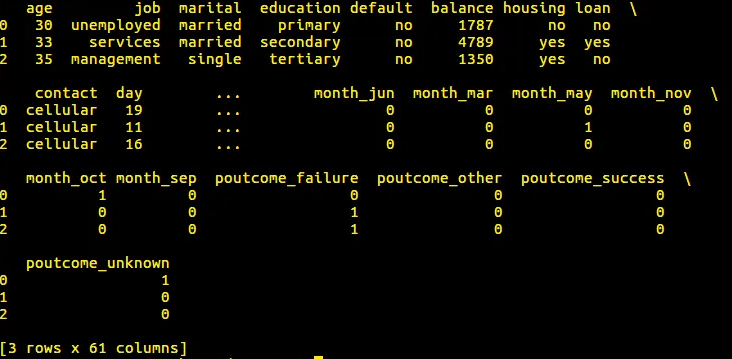
Puede comprender cómo se convierten las variables categóricas Variables ficticias que están listas para ser utilizadas en el modelado de este conjunto de datos. Pero, tenemos un pequeño problema aquí.
Las variables categóricas reales todavía existen y deben eliminarse para que el marco de datos esté listo para Machine Learning ai. Lo hacemos al primero convirtiendo los encabezados de columna del nuevo marco de datos en una lista mediante el atributo tolist().
Luego creamos una nueva lista de encabezados de columna sin variables categóricas y cambiamos el nombre de los encabezados.
Hacemos esto usando el siguiente código:
bank_vars = bankdf.columns.values.tolist() # column headers are converted into a list to_keep = [i for i in bank_vars if i not in cat_list] #create a new list by comparing with the list of categorical variables - 'cat_list' print to_keep # check the list of headers to make sure no categorical variable remains
Creando marco de datos sin variables categóricas
Estamos listos para crear un nuevo marco de datos sin variables categóricas y lo hacemos:
bank_final = bankdf[to_keep]
Tenga en cuenta que para crear el nuevo marco de datos, aquí pasamos una lista (‘to_keep’) al operador de indexación (‘bankdf’). Si no le pasa al operador de indexación una lista de nombres de columna, devolverá un keyerror .
Para seleccionar varias columnas como un marco de datos, debemos pasar una lista al operador de indexación. Sin embargo, puede seleccionar una sola columna como ‘serie’ y puede verla a continuación
bank_final = bankdf[to_keep] # to_keep is a 'list' print type(bank_final) >>> <class 'pandas.core.frame.DataFrame'> bank_final = bankdf['age'] print type(bank_final) >>> <class 'pandas.core.series.Series'> bank_final = bankdf['age','y'] print type(bank_final) >>> KeyError: ('age', 'y')
Podemos verificar los encabezados de las columnas del nuevo nuevo data-frame bank-final:
print bank_final.columns.values >>> ['age' 'balance' 'day' 'duration' 'campaign' 'pdays' 'previous' 'y' 'job_admin.' 'job_blue-collar' 'job_entrepreneur' 'job_housemaid' 'job_management' 'job_retired' 'job_self-employed' 'job_services' 'job_student' 'job_technician' 'job_unemployed' 'job_unknown' 'marital_divorced' 'marital_married' 'marital_single' 'education_primary' 'education_secondary' 'education_tertiary' 'education_unknown' 'default_no' 'default_yes' 'housing_no' 'housing_yes' 'loan_no' 'loan_yes' 'contact_cellular' 'contact_telephone' 'contact_unknown' 'month_apr' 'month_aug' 'month_dec' 'month_feb' 'month_jan' 'month_jul' 'month_jun' 'month_mar' 'month_may' 'month_nov' 'month_oct' 'month_sep' 'poutcome_failure' 'poutcome_other' 'poutcome_success' 'poutcome_unknown']
Estamos en una posición para separar variables de características y etiquetas, de modo que es posible probar algún algoritmo de Machine Learning ai en el conjunto de datos.
La selección de la función y la etiqueta de este nuevo marco de datos se realiza mediante el código siguiente:
bank_final_vars=bank_final.columns.values.tolist()# just like before converting the headers into a list Y = ['y'] X = [i for i in bank_final_vars if i not in Y]
Ya que hay demasiadas funciones, podemos elegir algunas de las funciones más importantes con Eliminación de funciones recursivas (RFE) bajo sklearn, que funciona en dos pasos.
Primero se pasa el clasificador a RFE con el número de funciones que se seleccionarán y luego se llama al método de ajuste. Esto se muestra en el código a continuación
model = LogisticRegression() rfe = RFE(model, 15) # we have selected here 15 features rfe = rfe.fit(bank_final[X], bank_final[Y])
Podemos usar el atributo support_ para encontrar qué características están seleccionadas:
print rfe.support_ >>> [False False False False False False False False False False False False True False False False False False False False True False False False False False True False False False False True False False True False False True False True True True True False False True True True False True True]
rfe.support_ produce una matriz donde las características que están seleccionadas están etiquetadas como Verdadero y puede ver 15 de ellos, ya que hemos seleccionado las 15 mejores características.
Otro atributo de RFE es ranking_ donde el valor 1 en la matriz resaltará las características seleccionadas.
print rfe.ranking_ >>> [33 37 32 35 23 36 31 18 11 29 27 30 1 28 17 7 12 10 5 9 1 21 16 25 22 4 1 26 24 13 20 1 14 15 1 34 6 1 19 1 1 1 1 3 2 1 1 1 8 1 1]
Podemos imprimir explícitamente el nombre de las características seleccionadas usando RFE, con el siguiente código:
rfe_rankinglist = rfe.ranking_.tolist() selected_columns = [] for im in range(len(X)): if rfe_rankinglist[im]==1: selected_columns.append(X[im]) print selected_columns >>> ['job_retired', 'marital_married', 'default_no', 'loan_yes', 'contact_unknown', 'month_dec', 'month_jan', 'month_jul', 'month_jun', 'month_mar', 'month_oct', 'month_sep', 'poutcome_failure', 'poutcome_success', 'poutcome_unknown']
Finalmente podemos proceder con los atributos .fit() y .score() para comprobar qué tan bien funciona el modelo.
En el próximo post discutiré en detalle sobre las matemáticas detrás de la Regresión logística y veremos que la regresión logística no puede seleccionar las características, simplemente reduce los coeficientes de un modelo lineal, similar a Regresión de la cresta.
A continuación se muestra el código que puede usar para verificar el efecto de la selección de características. Aquí hemos utilizado todo el conjunto de datos, pero la mejor práctica es dividir los datos en entrenamiento y conjunto de pruebas.
Como mini ejercicio, puede intentar esto y recuerde que la etiqueta del conjunto de datos está muy sesgada y el uso de stratify puede ser una buena idea. ¡Buena suerte!
X_new = bank_final[selected_columns] Y = bank_final['y'] X_old = bank_final[X] clasf = LogisticRegression() clasf_sel = LogisticRegression() clasf.fit(X_old,Y) clasf_sel.fit(X_new,Y) print "score using all features", clasf.score(X_old,Y) print "score using selected features", clasf_sel.score(X_new,Y)
Para concluir este post, resumamos los puntos más importantes:
- Hemos aprendido a usar pandas para resolver algunos de los problemas que puede tener un conjunto de datos realistas.
- Hemos aprendido a convertir cadenas (‘sí ‘,’ no ‘) a variables binarias (1, 0).
- Cómo el atributo
groupbyde un marco de datos pandas puede ayudarnos a comprender algunas de las conexiones clave entre características y etiquetas. - Cambiar variables categóricas a variables ficticias y usarlos en el modelado del conjunto de datos.
- Cómo seleccionar parte de un marco de datos pasando una lista al operador de indexación.
- Usin g RFE para seleccionar algunas de las características principales de un conjunto de datos complejo.
Esperamos que esta publicación te ayude a tener un poco más de confianza al tratar con un conjunto de datos realistas. Mantente fuerte y feliz. ¡Salud!