El espacio de características que agrieta nuevos datos introduce nuevas clases potencialmente útiles si se detectan. Los estímulos en la tasa de aumento de nuevos puntos de datos con una clasificación de confianza inferior a la aceptable indican que las nuevas zonas de datos se están forjando en el espacio de características …
La única constante es el cambio. Y los datos no son una excepción. Detectar la evolución de los datos nos permite analizar más a fondo lo que significa tomar decisiones en el futuro. Por ejemplo, podemos estar clasificando a los pacientes como simplemente fallecidos o no según algunos datos iniciales sobre los síntomas. Pero a medida que evoluciona el deceso, también lo hacen los síntomas y el régimen de tratamiento adecuado. Un modelo entrenado en síntomas leves para detectar la presencia de una enfermedad puede detectar esa enfermedad con síntomas agudos. Pero nos gustaría detectar el analógico al mismo tiempo que clasificamos estos nuevos datos, emitir una alerta y marcarlo como potencialmente necesario para una nueva clase. La diferenciación directa entre los casos agudos, intermedios y leves y la clasificación de los pacientes como tales tiene un gran beneficio en muchos niveles.
Es evidente que la cantidad de características no ha cambiado y ninguno de los conceptos subyacentes se ha utilizado para clasificar los datos. Pero la distribución de los datos entrantes ha cambiado. Los nuevos datos están creando zonas en el mismo espacio de características donde antes no había datos. Esta es una subdivisión del espacio de características o, más bien, el fracking del espacio de características.
Un modelo capacitado en datos / clases más antiguos recopilará todos los datos según las clases que conozca, sin sorpresas. Pero marcar e identificar las nuevas zonas como nuevas clases potencialmente emergentes puede ser extremadamente útil. Ese en esencia es el objetivo de este post. El enfoque está en presentar un enfoque. Para hacerlo, consideramos un problema simple con dos características y un puñado de clases. Si bien el problema se ha ideado, los elementos visuales pueden ayudar a aclarar el punto. El código para reproducir los resultados se puede obtener en github .
Qué hacer cuando se detectan nuevas clases en los datos depende del problema. Por ejemplo, si de hecho decidimos que una nueva clase está justificada, podemos etiquetar una parte de estos nuevos datos marcados y volver a entrenar el modelo
1. Característica Segmentación del espacio
Un clasificador entrenado en N clases necesariamente colocará los datos entrantes en cualquiera de esas N clases. Todo el espacio de funciones, incluidos todos los puntos de datos antiguos y nuevos, ya se ha dividido en N zonas. Pero los datos con los que se ha entrenado al clasificador pueden no haber cubierto completamente estas zonas. Cuando los nuevos datos comienzan a ocupar estas zonas previamente vacías, es una indicación de que los datos están evolucionando.
Por ejemplo, un modelo puede haber clasificado previamente dispositivos de comunicación en teléfonos de escritorio o buscapersonas en función de la presencia / ausencia de términos como “hablar”, “móvil”, etc. Pero ese modelo estará bastante confundido acerca de los teléfonos móviles walkie-talkies y que han venido a reclamar la propiedad de Diferentes piezas del mismo espacio rasgo. Dependiendo de la abundancia específica de términos en la descripción, el modelo puede etiquetar algunos de estos productos como buscapersonas y otros como teléfonos de escritorio, exactamente para lo que el clasificador ha sido entrenado. Pero es menos que óptimo. Si hubiéramos tenido la capacidad de detectar la llegada de nuevos datos en estas zonas previamente vacías, podríamos haber inspeccionado esos datos y potencialmente definido nuevas categorías para ellos. Agregar teléfonos móviles y walkie-talkies como nuevas categorías y entrenar al clasificador para predecirlos sería una mejora muy útil para el clasificador.
Si bien podemos visualizar grietas emergentes y nuevas zonas de datos en dimensiones más bajas, no es práctico en niveles superiores. dimensiones. Necesitamos una medida global de clases que podamos rastrear como parte de la clasificación en curso de los nuevos datos. El comportamiento de esta medida global debería prestarnos pistas para buscar nuevas zonas / clases emergentes. Un indicador derivado de la confianza de clasificación es lo que emplearemos aquí para identificar el fracking del espacio de características. Veamos de qué se trata la confianza en la clasificación.
2. Confianza en la clasificación
La mayoría de los clasificadores son de naturaleza probabilística (con notables excepciones, como la SVM, aunque existen enfoques para derivar probabilidades a partir de medidas de distancia). Es decir, cuando se le pide al clasificador que prediga la clase de un nuevo punto de datos, primero aparece una lista de probabilidades para que ese punto de datos pertenezca a cualquiera de las clases disponibles. A continuación, elige la clase con la mayor probabilidad. Ahora considere el siguiente argumento, en su mayoría sentido común.
- Cada nuevo punto de datos se coloca en una clase: la clase con la mayor probabilidad calculada por el clasificador. Cuanto mayor sea la probabilidad, mayor será la confianza en la clasificación de este punto de datos.
- Un nuevo punto de datos que caiga en una zona con muchos datos de entrenamiento se clasificará con un alto grado de confianza.
- Lo contrario de punto 2 arriba. Es decir, a un nuevo punto de datos que cae en una zona con poco o ningún dato de entrenamiento se le asignará una clase con seguridad, pero con una menor confianza .
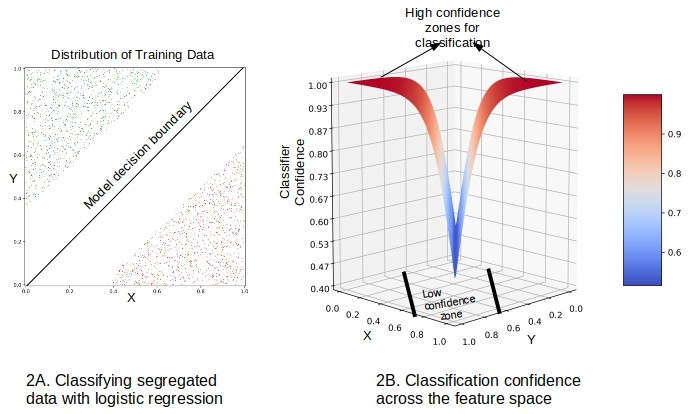
Esto se ilustra en la Figura 2A a continuación con un juguete 2 – característica, problema de 2 clases que emplea regresión logística como el clasificador construido sobre datos bien segregados. La probabilidad de que un punto pertenezca a cualquiera de las dos clases es 0.5 en el límite lineal, es decir, la confianza es la menor. A medida que nos alejamos del límite y nos adentramos en las zonas con datos, la probabilidad estimada de que un punto pertenezca a la clase correcta es mayor, es decir, la confianza es mayor.
En general, la clasificación de confianza de un punto de datos es la máxima de las N probabilidades de que este punto de datos pueda pertenecer a cualquiera de las clases N.
clasificación de confianza
La Figura 2B muestra la confianza de clasificación calculada de este modelo en todo el espacio de características.

Un indicador de fracking
De la discusión anterior se desprende que cuando los datos nuevos caen en zonas previamente despobladas, la clasificación La confianza de esos nuevos puntos de datos sería menor. Por lo tanto, elegimos un nivel de confianza de umbral y contamos los puntos de datos recientemente clasificados cuya confianza de clasificación según lo predicho por el modelo está por debajo de este umbral. Cuando no se están forjando nuevas zonas, este conteo aumentará a su velocidad de fondo normal, ya que siempre habrá una cantidad nominal de datos que ingresará a las zonas despobladas. Pero cuando los datos están evolucionando, una fracción más alta (que el fondo) de los nuevos datos comienza a ir a esas zonas previamente vacías. Esto se mostrará como un aumento sostenido (bueno, suponiendo que los datos continúen evolucionando de esa manera) en la tasa de aumento de este conteo, todo lo demás es igual, por supuesto.
Hablando de manera general, podemos identificar el espacio de características del fracking por buscando estímulos en la tasa de aumento del número de nuevos puntos de datos por debajo de un umbral de confianza de clasificación
indicador de fracking
Las probabilidades que necesitamos para calcular la confianza de clasificación ya las proporciona el clasificador como parte de la tarea de clasificación. Por lo tanto, la cantidad de puntos de datos por debajo de un umbral de confianza y su tasa de aumento son fáciles de calcular y realizar un seguimiento de un ejercicio de clasificación en curso. Cuando detectamos un arrebato sostenido en este indicador de fracking, podemos activar una tarea para muestrear los nuevos datos específicos con baja confianza en la clasificación y decidir si crearemos nuevas clases para ellos. Tomó algunas palabras para llegar aquí, pero ese es el enfoque. Concluiremos la publicación con un ejemplo y fragmentos de código
3. Simulación
Considere un diseño inicialmente bien segregado de cuatro zonas y clases de datos (A, B, C y D) que se muestra en la Figura 3.1 a continuación. Hemos dejado a propósito suficiente espacio en cada zona / clase para que los datos entrantes puedan crear nuevas zonas / clases. Aquí hay un fragmento de código para bombear datos a cualquier región triangular dados los tres vértices.
https://medium.com/media/e217610b11458db04ae99664b3805f13/href
Se clasifica un clasificador de regresión logística multinomial en los datos de la Figura 3.1. Obtiene una puntuación f1 perfecta dado que las clases son lineales y perfectamente separables. Los ejes / líneas verticales y horizontales son de hecho los límites de decisión obtenidos. Los puntos con baja confianza de clasificación (<0.75) se obtienen para el seguimiento.
https://medium.com/media/55d4ec409b07bf0ffa67f5870f115045/href

3.1 Zonas de confianza de clasificación baja
El siguiente fragmento de código simula lotes de datos nuevos (sin etiquetas de curso) con cada lote que agrega aproximadamente el uno por ciento del número inicial de puntos a las zonas de datos activas en ese momento. Las zonas de datos activas comienzan como ABCD y evolucionan a través de ABCD-A ‘=> ABCD-A’-B’ => ABCD-A’-B’-C ‘=> ABCD-A’-B’-C’-D ‘ en ese orden. Esto queda bastante claro en las Figuras 3.2 a 3.5 que muestran las nuevas zonas de datos A ‘a D’ que se están dividiendo en el espacio de características con el tiempo.
https://medium.com/media/1534a44f811773b1e57639c2e009891b/href
Mantenemos Seguimiento de los puntos de datos por debajo del umbral de confianza de clasificación. La Figura 4 muestra la distribución espacial de estos puntos de datos. Como se esperaba, las zonas sin datos de entrenamiento se muestran como las que se iluminan en estas tablas.

3.2 Indicador de fracking
De la Figura 4, debe quedar claro que la tasa de aumento del número de puntos tiene que ver un aumento repentino cuando una nueva zona de datos está comenzando a tallarse. Dado que hacemos un seguimiento de este número en el ejercicio de clasificación, la Figura 5 a continuación es fácil de producir.

4. Conclusión
Nos pusimos en marcha con el objetivo de identificar el fracking del espacio de características por medio de una medida global que se puede usar para activar una evaluación de los nuevos datos afectados por la utilidad potencial de agregar nuevas clases.
- Definimos la confianza de clasificación de un punto de datos para que sea el máximo de todas las probabilidades de que ese punto de datos pueda pertenecer a cualquiera de las clases entrenadas en
- Definimos el indicador de fracking como la tasa de aumento del número de nuevos puntos de datos con un valor inferior a un poco de confianza de clasificación de umbral
- Con la ayuda de un problema idóneo, ideado (nuevas tasas de datos constantes, nuevas zonas de datos en constante evolución, etc.) demostramos que el indicador de fracking detectó el aumento de posibles nuevas clases.
Con datos reales que incluyen ruido, tasas de datos variables, zonas de datos en evolución y muriendo las cosas pueden volverse más turbias. Sin embargo, una gráfica de monitoreo de tablero de instrumentos como la Figura 5 será útil en un ejercicio de clasificación en curso en producción. Si no fuera por señalar con exactitud la hora en que una nueva clase sería útil, pero ciertamente para detectar cuándo se debe dividir un grupo de “ninguno de los anteriores”.
Publicado originalmente en http: / /xplordat.com[19659049Contratadoel6demayode2019

Características de Fracking en Aprendizaje automático se publicó originalmente en Hacia la ciencia de datos en Medio, donde las personas continúan la conversación resaltando y respondiendo a esta historia.