
TensorFlow y TensorRT: Optimización del modelo y reducción de la precisión de FP32 a FP 16 para acelerar y reducir el tamaño del gráfico.
¿De qué trata este artículo? ¿Para quién es esto?
Es básicamente el ¿cómo? sobre la optimización de un modelo de Tensorflow. Utilizando herramientas de transformación TF Graph y NVIDIA TensorRT. Esto es un poco pesado y está destinado a los ingenieros de Data Science que a Data Scientist. Además, más que un manual, también ilustra los errores y los resultados inesperados que he encontrado al hacer esto.
Además, estos resultados pueden ser inesperados para mí en el rol de un ingeniero de DS, pero pueden tener una explicación racional si Entiendo o profundizo en las abstracciones del modelo o el marco TF que implementa este modelo.
He planteado estos dos errores, uno con TF Graph Transform y otro con NVIDIA TensorRT Transform Tool:
- https://github.com/tensorflow/tensorflow/issues/28276
- https://devtalk.nvidia.com/default/topic/1048485/tensorrt/no-speed-up-with-tensorrt-fp16-or-int8-on-nvidia-v100/post/5320989/#5320989
¿Cuál fue la expectativa? Más núcleos CUDA, TensorCores == (Pensé) Inferencia más rápida.
De la descripción del producto NVIDIA TensorCore, tengo la idea / espero que si puedo convertir el Los modelos de detección de objetos basados en FP 32 que usamos en producción para los modelos y pesas FP 16 o INT8.
Entonces podré correr dos o cuatro veces más rápido que las velocidades de inferencia; como se anuncia.
Teníamos una de las mejores GPU NVIDIA V100 de 32 GB para nuestros experimentos que admitía todos estos modos: Tensor Cores, sin mencionar un conjunto de otras GPU de nivel de servidor y de juego, P40, GTX 1080, 1070, etc.
Antes de comenzar con estas costosas GPU, solíamos ejecutar el modelo en computadoras de escritorio GTX 1080 HP. La primera expectativa era que la mayor cantidad de núcleos CUDA (~5k) en V100 haría que nuestros modelos funcionaran más rápido.
Leí blogs como el siguiente y supe que 1080 es bastante bueno y que NVIDIA valora y comercializa las GPU del lado del servidor más altas. (En 1080 aceleran el FP16, que supongo que se eliminará en 2080).
Aquí hay un extracto de lo anterior.
2080 Ti vs V100: ¿la 2080 Ti es realmente tan rápida?
Si es absolutamente necesario 32 GB de memoria porque el tamaño de su modelo no cabe en 11 GB de memoria con un tamaño de lote de 1. Si está creando su propia arquitectura de modelo y simplemente no cabe incluso cuando trae el tamaño de lote más bajo, el V100 podría tener sentido. Sin embargo, este es un caso extremo bastante raro. Menos del 5% de nuestros clientes utilizan modelos personalizados. La mayoría usa algo como ResNet, VGG, Inception, SSD o Yolo.
Entonces. Todavía te lo estás preguntando. ¿Por qué alguien compraría el V100? Todo se reduce al marketing”.
Además, no esperaba una aceleración drástica de todos modos con más núcleos CUDA, ya que incluso con cuadros de imagen HD, descubrimos que la utilización de la GPU no podía alcanzar el 100 por ciento. Lo que significa que el procesamiento por sí solo no era el cuello de botella. Una vez más, aquí las cosas están grises. Aquí hay mucho más alcance para las optimizaciones de ingeniería.
El motivo por el que elegimos el V100 no fue por cuestión de “marketing”. Era la única GPU con tanta memoria de 32 GB, lo que nos permitiría agrupar más fotogramas de imágenes en paralelo y, básicamente, realizar análisis en tiempo real de más cámaras de vídeo HD en un solo borde.
Realidad con respecto a más CUDA Cores
La verdad es que, aparte de la ventaja de procesar más cuadros en paralelo debido a la mayor memoria, no hubo aceleración de la GPU 1080 (~2.5k núcleo CUDA). También probamos esto en Jetson TX2, que tiene muchos menos núcleos CUDA (~256) y una GPU para juegos más antigua, donde era muy lenta.
Por lo tanto, los núcleos CUDA más altos ayudan a funcionar más rápido, pero más allá de cierto umbral, no hay mucha diferencia. Quizás este hecho ya se conozca y es por eso que los modelos más nuevos de NVIDIA como el T4 tienen alrededor de 2.5k núcleos CUDA, y estos están disponibles en GCP y otros proveedores de nube para realizar inferencias a precios mucho más económicos.
El V100 parece usarse sólo para modelos de entrenamiento. Al menos ahora no es práctico entrenar modelos con menor precisión. Las matemáticas son más fáciles: descenso de gradiente, propagación hacia atrás con mayor precisión.
Puede obtener más información en la publicación de Tom Dettmers sobre las GPU https://timdettmers.com/2019/04/03/ Which- gpu-for-deep-learning/, pero tenga cuidado con cosas como la cantidad de cuadros que tiene. necesita procesar en paralelo, etc. que solo velocidades de inferencia brutas.
Realidad con respecto a TensorCores, media precisión / menor precisión FP16, INT8
El campo de la ingeniería en ciencia de datos aún es incipiente en el sentido de que no existe una distinción clara entre dónde termina la ciencia de datos y toma el relevo la ingeniería.
Los marcos como Tensorflow Serving y las herramientas ayudan al equipo de desarrollo o operaciones de DS a trabajar en el modelo, desarrollar clientes genéricos y crear aplicaciones útiles en el modelo.
Pero tratan el modelo sin conocer demasiado en profundidad. Entonces, cuando toman un modelo y hacen una optimización y obtienen un error como el que se muestra a continuación, no saben qué hacer, pero sienten un verdadero complejo de inferioridad y toman una nota mental para comprender mejor las cosas.
details = "input_max_range debe ser más grande que input_min_range.
[[{{node Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ClipToWindow_87/Area/mul_eightbit/Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ClipToWindow_87/Area/sub_1/quantize}}]]
[[{{node Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/zeros_like_83}}]] "
Con ese preludio, y en base a las optimizaciones que funcionaron (parcialmente) en la conversión de un modelo de detección de objetos: Detector de disparo único del zoológico modelo TF, aquí están los resultados que obtuve al ejecutar en V100.
Básicamente, no aceleré mucho, ya que muchas de las capas no se convirtieron**. Inicialmente hice el experimento en un modelo convertido de Keras y obtuve resultados similares, pero luego pensé que si usaba un modelo escrito TF, podría ser mejor, y de ahí los experimentos en el modelo SSD.
**tensorflow/contrib/tensorrt/segment/segment.cc:443] There are 3962 ops of 51 different types in the graph that are not converted to TensorRT: TopKV2, NonMaxSuppressionV2, TensorArrayWriteV3, Const, Squeeze, ResizeBilinear, Maximum, Where, Add, Placeholder, Switch, TensorArrayGatherV3, NextIteration, Greater, TensorArraySizeV3, NoOp, TensorArrayV3, LoopCond, Less, StridedSlice, TensorArrayScatterV3, ExpandDims, Exit, Cast, Identity, Shape, RealDiv, TensorArrayReadV3, Reshape, Merge, Enter, Range, Conv2D, Mul, Equal, Sub, Minimum, Tile, Pack, Split, ZerosLike, ConcatV2, Size, Unpack, Assert, DataFormatVecPermute, Transpose, Gather, Exp, Slice, Fill, (For more information see https://docs.nvidia.com/deeplearning/dgx/integrate- tf-trt/index.html#support-ops).
El resto del artículo son más detalles sobre cómo hice esto y que también puedes seguir paso a paso:
La publicación que realmente me ayudó fue la del equipo de Google:
- https://medium.com/google-cloud/optimizing-tensorflow-models-for -serving-959080e9ddbf
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms#optimizing-for-deployment
Estoy escribiendo esta publicación como una explicación más detallada de [1], ya que algunas partes no estaban claras cuando comencé a seguir los pasos.
Mi cuaderno Colab/Jupyter para optimización se proporciona aquí; Puedes saltarte el artículo y seguir el Cuaderno también como lo he documentado en el cuaderno. Sin embargo, las partes TF Serving y Client se encuentran en este artículo.
https://colab.research.google.com/drive/1wQpWoc40kf__WSjfTqDaReMx6fjUn48
Si tiene un gráfico TF congelado , puede utilizar los siguientes métodos para optimizarlo antes de usarlo para inferencias.
Hay dos tipos de optimización. Uno para hacerlo más rápido o más pequeño para ejecutar inferencias. Y el otro para cambiar los pesos de mayor precisión a menor precisión. Generalmente de FP32 a FP16 o INT8.
Para esto último, la GPU debería tener la capacidad de ejecutar operaciones de precisión mixta (Tensor Cores). Por lo general, las computadoras de escritorio o portátiles de NVIDIA GTX 1080 o similares no pueden ejecutar operaciones de menor precisión.
Las GPU de clase servidor de NVIDIA lo admiten. Especialmente las GPU más nuevas V100, T4, etc. No todas las GPU de servidor lo admiten.
La GPU que utilizo es la GPU NVIDIA V100 de 32 GB que admite operaciones de precisión mixta. Además, debe ejecutar la optimización en la GPU que está optimizando. Especialmente si estás usando TensorRT.
Paso 0. El modelo y los contenedores Docker
Lo primero que hay que hacer es convertir el gráfico de TensorFlow en un gráfico congelado. Si el gráfico está basado en Kearns, es el formato HD5 y debe convertirse al modelo TF y luego al gráfico congelado.
Un gráfico congelado tiene el valor de las variables incrustadas en el propio gráfico. Es un formato GrpahDef/protocol buffer (pb) como un modelo guardado, solo que no se puede volver a entrenar.
¿Qué es la diferencia frozen_inference_graph.pb y saved_model.pb?
El modelo que estamos usando es el modelo SSD ssd_resnet_50_fpn_coco del modelo TF zoo: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
El contenedor Docker utilizado para la optimización es tensorflow/tensorflow:1.13.0rc1-gpu-jupyter
docker run --entrypoint=/bin/bash --runtime=nvidia -it --rm -p 8900:8500 -p 8901:8501 -v /usr/alex/:/coding --net=host tensorflow/tensorflow:1.13.0rc1-gpu-jupyter once inside cd /coding jupyter notebook --allow-root &
Nota: creo que cambié el punto de entrada a algo más conveniente para mí que el tf-notebook predeterminado.
Después de la optimización, para ejecutar inferencias, estoy usando la misma imagen de la ventana acoplable después de instalarla en esa API de servicio TF, así como la versión opencv-python sin cabeza.
Esto se debe a que convertiremos el modelo optimizado en un modelo compatible con TF para inferencia.
docker run --entrypoint=/bin/bash --env http_proxy=<my proxy> --env https_proxy=<my proxy> --runtime=nvidia -it --rm -p 8900:8500 -p 8901:8501 -v /usr/alex/:/coding --net=host tensorflow/tensorflow:1.13.0rc1-gpu-jupyterpip install tensorflow-serving-api
pip install opencv-python==3.3.0.9
cd coding
python ssd_client_1.py -num_tests=1 -server=127.0.0.1:8500 -batch_size=1 -img_path='../examples/google1.jpg/'
Paso 1. Obtenga los nombres de los nodos de salida en el gráfico de Tensorflow
¿Por qué es esto importante? Necesitamos encontrar los nombres de los nodos de salida del gráfico congelado como se necesita para optimizar el gráfico. Note la versión de Tensorflow que se usa en TF 1.13
# To Freeze the Saved Model # We need to freeze the model to do further optimisation on itfrom tensorflow.python.saved_model import tag_constants from tensorflow.python.tools import freeze_graph from tensorflow.python import ops from tensorflow.tools.graph_transforms import TransformGraphdef freeze_model(saved_model_dir, output_node_names, output_filename): output_graph_filename = os.path.join(saved_model_dir, output_filename) initializer_nodes = '' freeze_graph.freeze_graph( input_saved_model_dir=saved_model_dir, output_graph=output_graph_filename, saved_model_tags = tag_constants.SERVING, output_node_names=output_node_names, initializer_nodes=initializer_nodes, input_graph=None, input_saver=False, input_binary=False, input_checkpoint=None, restore_op_name=None, filename_tensor_name=None, clear_devices=True, input_meta_graph=False, )
Para esto, podemos trazar el modelo en TF Board y ver los nodos de salida, o imprimir los nodos y hacer grep con algunas palabras clave.
# Fuente https://medium.com/google-cloud/optimizing-tensorflow-models-for-serving-959080e9ddbf def get_graph_def_from_file(graph_filepath): tf.reset_default_graph() con ops.Graph().as_default(): con tf.gfile.GFile(graph_filepath, 'rb') como f: graph_def = tf.GraphDef() graph_def.ParseFromString(f .read()) devuelve graph_def
Usemos el ayudante anterior para imprimir los nodos de entrada y salida, los nodos de entrada a través del bucle for:
graph_def =get_graph_def_from_file('/coding/ssd_inception_v2_coco_2018_01_28/frozen_inference_graph.pb')
for node in graph_def.node:
if node.op=='Placeholder':
print node # this will be the input node
Y nodos de salida trazándolos en un formato legible por Tensor Board:
with tf.Session(graph=tf.Graph()) as session: mygraph = tf.import_graph_def(graph_def, name='') writer = tf.summary.FileWriter(logdir='/coding/log_tb/1', graph=session.graph) writer.flush()
De esto, pude distinguir los nodos de salida. Tenga en cuenta que si usted mismo está construyendo la gráfica, no necesita hacer este circo. Ya que estoy usando un modelo que está abierto y con menos documentación, estoy usando esto.
A veces, para los gráficos convertidos automáticamente / TF importados, los nombres serán bastante largos. A continuación, puede imprimir los nodos en un bucle for como lo hice para Placeholder y, a partir de la salida, conformar forma (para la clase de detecciones, puntuación, coordenadas del rectángulo)
# These are the output names. Add a index usually 0 for graph nodes. # You can print the node details by nodenames output_node_names = ['detection_boxes','detection_scores','detection_classes','num_detections'] outputs = ['detection_boxes:0','detection_scores:0','detection_classes:0','num_detections:0']
Paso 3 Optimizar utilizando las herramientas de transformación de la gráfica TensorFlow
El fragmento de código a continuación ilustra cómo puede optimizar un gráfico después de leerlo disk.
# Source https://medium.com/google-cloud/optimizing-tensorflow-models-for-serving-959080e9ddbf #https://gist.github.com/lukmanr # Optimizing the graph via TensorFlow library from tensorflow.tools.graph_transforms import TransformGraph def optimize_graph(model_dir, graph_filename, transforms, output_names, outname='optimized_model.pb'): input_names = ['input_image',] # change this as per how you have saved the model graph_def = get_graph_def_from_file(os.path.join(model_dir, graph_filename)) optimized_graph_def = TransformGraph( graph_def, input_names, output_names, transforms) tf.train.write_graph(optimized_graph_def, logdir=model_dir, as_text=False, name=outname) print('Graph optimized!')
Usemos el asistente anterior para optimizar la gráfica primero quantize_weights
# Optimization without Qunatization - Reduce the size of the model # speed may actually be slower # see https://medium.com/google-cloud/optimizing-tensorflow-models-for-serving-959080e9ddbftransforms = ['remove_nodes(op=Identity)', \ 'merge_duplicate_nodes', \ 'strip_unused_nodes', 'fold_constants(ignore_errors=true)', 'fold_batch_norms', 'quantize_weights'] #this reduces the size, but there is no speed up , actaully slows down, see belowoptimize_graph('/coding/ssd_inception_v2_coco_2018_01_28', 'frozen_inference_graph.pb' , transforms, output_node_names,outname='optimized_model_small.pb')
A continuación, vamos a convertir el modelo optimizado a un formato compatible con TF.
#lets convert this to a s TF Serving compatible mode;
convert_graph_def_to_saved_model(‘/coding/ssd_inception_v2_coco_2018_01_28/2’,
‘/coding/ssd_inception_v2_coco_2018_01_28/optimized_model_small.pb’,outputs)
esto se proporciona a continuación
# Source https://medium.com/google-cloud/optimizing-tensorflow-models-for-serving-959080e9ddbf#https://gist.github.com/lukmanrdef convert_graph_def_to_saved_model(export_dir, graph_filepath,outputs):graph_def = get_graph_def_from_file(graph_filepath) with tf.Session(graph=tf.Graph()) as session: tf.import_graph_def(graph_def, name='') tf.saved_model.simple_save( session, export_dir,# change input_image to node.name if you know the name inputs={'input_image': session.graph.get_tensor_by_name('{}:0'.format(node.name)) for node in graph_def.node if node.op=='Placeholder'}, outputs={t:session.graph.get_tensor_by_name(t) for t in outputs} ) print('Optimized graph converted to SavedModel!')
Y luego ‘quantize_weights’ and ‘quantize_nodes’.
Esto realmente debería encubrir el cálculo para una menor precisión, pero no lo hace trabajo a partir de ahora.
“Este proceso convierte todas las operaciones en el gráfico que tienen equivalentes cuantizados de ocho bits y deja el resto en punto flotante. Solo se admite un subconjunto de operaciones y en muchas plataformas, el código cuantificado puede ser más lento que los equivalentes flotantes, pero esta es una forma de aumentar el rendimiento sustancialmente cuando todas las circunstancias son correctas “.
https: // github. com / tensorflow / tensorflow / tree / master / tensorflow / tools / graph_transforms # optimizing-for-deploy
transforms = ['add_default_attributes', \ 'strip_unused_nodes', \ 'remove_nodes(op=Identity, op=CheckNumerics)',\ 'fold_constants(ignore_errors=true)', 'fold_batch_norms', 'fold_old_batch_norms', 'quantize_weights', 'quantize_nodes', 'strip_unused_nodes', 'sort_by_execution_order']optimize_graph('/coding/ssd_inception_v2_coco_2018_01_28', 'frozen_inference_graph.pb' , transforms, output_node_names,outname='optimized_model_weight_quant.pb')
optimise_graph (& # 039; tes / recuento de las condiciones de las circunstancias o de las circunstancias) transforms, output_node_names, outname = & # 039; optimized_model_weight_quant.pb & # 039;)
Sin embargo, esto no funciona en el sentido, la inferencia que utiliza este modelo optimizado da el error. Intenté con un modelo Keras anteriormente y recibí otro mensaje de error. Esto parece ser un error ya que ahora este modelo es un modelo de Tensorflow puro y no he cambiado nada aquí
(‘Got an error’, <_Rendezvous of RPC that terminated with:
status = StatusCode.INVALID_ARGUMENT
details = “input_max_range must be larger than input_min_range.
[[{{node Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ClipToWindow_87/Area/mul_eightbit/Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ClipToWindow_87/Area/sub_1/quantize}}]]
[[{{node Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/zeros_like_83}}]]”
debug_error_string = “{“created”:”@1555723203.356344655",”description”:”Error received from peer”,”file”:”src/core/lib/surface/call.cc”,”file_line”:1036,”grpc_message”:”input_max_range must be larger than input_min_range.\n\t [[{{node Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ClipToWindow_87/Area/mul_eightbit/Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ClipToWindow_87/Area/sub_1/quantize}}]]\n\t [[{{node Postprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/zeros_like_83}}]]”,”grpc_status”:3}”
>)
Response Received Exiting
Paso 4 Optimizar usando NVIDIA TensorRT
La referencia base para esto es estos dos mensajes
https://docs.nvidia.com/deeplearning/dgx/integrate-tf -trt / index.html
https://developers.googleblog.com/2018/03/tensorrt-integration-with-tensorflow.html
Inference con TF-TRT ` Flujo de trabajo de SavedModel`: estamos utilizando el modelo TF Serving.
import tensorflow.contrib.tensorrt as trt
tf.reset_default_graph()
graph = tf.Graph()
sess = tf.Session()
# Create a TensorRT inference graph from a SavedModel:
with graph.as_default():
with tf.Session() as sess:
trt_graph = trt.create_inference_graph(
input_graph_def=None,
outputs=outputs,
input_saved_model_dir='/coding/ssd_inception_v2_coco_2018_01_28/01',
input_saved_model_tags=['serve'],
max_batch_size=1,
max_workspace_size_bytes=7000000000,
precision_mode='FP16')
#precision_mode='FP32')
#precision_mode='INT8')
output_node=tf.import_graph_def(trt_graph, return_elements=outputs)
#sess.run(output_node)
tf.saved_model.simple_save(sess,
"/coding/ssd_inception_v2_coco_2018_01_28/4",
inputs={'input_image': graph.get_tensor_by_name('{}:0'.format(node.name))
for node in graph.as_graph_def().node if node.op=='Placeholder'},
outputs={t:graph.get_tensor_by_name('import/'+t) for t in outputs}
)
Inferencia con TF-TRT Flujo de trabajo del gráfico `Frozen`:
#Lets load a frozen model and reset the graph and use
gdef =get_graph_def_from_file(‘/coding/ssd_inception_v2_coco_2018_01_28/frozen_inference_graph.pb’)
tf.reset_default_graph()
graph = tf.Graph()
sess = tf.Session()
# Create a TensorRT inference graph from a SavedModel:
with graph.as_default():
with tf.Session() as sess:
trt_graph = trt.create_inference_graph(
input_graph_def=gdef,
outputs=outputs,
max_batch_size=8,
max_workspace_size_bytes=7000000000,
is_dynamic_op=True,
#precision_mode=’FP16')
#precision_mode=’FP32')
precision_mode=’INT8')
output_node=tf.import_graph_def(trt_graph, return_elements=outputs)
#sess.run(output_node)
tf.saved_model.simple_save(sess,
“/coding/ssd_inception_v2_coco_2018_01_28/5”,
inputs={‘input_image’: graph.get_tensor_by_name(‘{}:0’.format(node.name))
for node in graph.as_graph_def().node if node.op==’Placeholder’},
outputs={t:graph.get_tensor_by_name(‘import/’+t) for t in outputs}
)
Paso 5: Haga una pausa y verifique los modelos
A continuación se muestran las salidas de los distintos modelos. Puede ver que el tamaño del modelo se reduce después de las optimizaciones.
Original model ('/coding/ssd_inception_v2_coco_2018_01_28/frozen_inference_graph.pb', '')
Model size: 99591.409 KB
Variables size: 0.0 KB
Total Size: 99591.409 KB
---------Tensorflow Transform Optimised model Weights Quantised ('/coding/ssd_inception_v2_coco_2018_01_28/2/saved_model.pb', '') Model size: 26193.27 KB
Variables size: 0.0 KB
Total Size: 26193.27 KB
---------Tensorflow Transform Optimised model Weights and Nodes Quantised ('/coding/ssd_inception_v2_coco_2018_01_28/3/saved_model.pb', '') Model size: 29265.284 KB
Variables size: 0.0 KB
Total Size: 29265.284 KB
---------NVIDIA RT Optimised model FP16 ('/coding/ssd_inception_v2_coco_2018_01_28/4/saved_model.pb', '') Model size: 178564.229 KB
Variables size: 0.0 KB
Total Size: 178564.229 KB
---------NVIDIA RT Optimised model INT8 ('/coding/ssd_inception_v2_coco_2018_01_28/5/saved_model.pb', '') Model size: 178152.834 KB
Variables size: 0.0 KB
Total Size: 178152.834 KB
Observe el contenedor que usamos aquí – Cliente
docker run --entrypoint=/bin/bash --env http_proxy=<my proxy> --env https_proxy=<my proxy> --runtime=nvidia -it --rm -p 8900:8500 -p 8901:8501 -v /usr/alex/:/coding --net=host tensorflow/tensorflow:1.13.0rc1-gpu-jupyter pip install tensorflow-serving-api pip install opencv-python==3.3.0.9 cd coding python ssd_client_1.py -num_tests=1 -server=127.0.0.1:8500 -batch_size=1 -img_path='../examples/google1.jpg/'
Servidor: esto se pega desde el Paso 0. Esto se ejecuta en la V100 32 GB Linux / machine.
docker run --net=host --runtime=nvidia -it --rm -p 8900:8500 -p 8901:8501 -v /usr/alex/:/models tensorflow/serving:1.13.0-gpu --rest_api_port=0 --enable_batching=true --model_config_file=/models/ssd_inception_v3_coco.json
Donde config json es como abajo. Desde que coloqué los diferentes modelos en las carpetas bajo “/ models / ssd_inception_v2_coco_2018_01_28 /” como 01 – modelo original, Transformación de peso de 2 TF TF Cuantificado, Transformación de gráfico de 3 TF y Nodo Cuantificado, 4-TensorRT FP16,5-TensorRT INT8 ; Acabo de cambiar las versiones en el archivo para cargar diferentes servibles para cada prueba.
model_config_list {
config {
name: "ssd_inception_v2_coco",
base_path: "/models/ssd_inception_v2_coco_2018_01_28/",
model_version_policy: {
specific: {
versions:[01]
}
},
model_platform:"tensorflow",
}
}
Paso 7: Escriba un cliente de servicio de TensorFlow para las pruebas
El modelo guardado del SSD es como a continuación. Puede usar el modelo guardado de la CLI para verlo:
saved_model_cli show --dir '/coding/ssd_inception_v2_coco_2018_01_28/3' --allMetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:signature_def['serving_default']: The given SavedModel SignatureDef contains the following input(s): inputs['input_image'] tensor_info: dtype: DT_UINT8 shape: (-1, -1, -1, 3) name: image_tensor:0 The given SavedModel SignatureDef contains the following output(s): outputs['detection_boxes:0'] tensor_info: dtype: DT_FLOAT shape: unknown_rank name: detection_boxes:0 outputs['detection_classes:0'] tensor_info: dtype: DT_FLOAT shape: unknown_rank name: detection_classes:0 outputs['detection_scores:0'] tensor_info: dtype: DT_FLOAT shape: unknown_rank name: detection_scores:0 outputs['num_detections:0'] tensor_info: dtype: DT_FLOAT shape: unknown_rank name: num_detections:0 Method name is: tensorflow/serving/predict
Tenga en cuenta que, en este caso, los nombres de los nodos de entrada y salida son ligeramente diferentes del modelo original, cuya entrada es ‘entradas’ y la salida es ‘detectores’, ‘detecciones_clases’, ‘detecciones_escuchas’ (sin el : 0 parte, que es una deficiencia en los scripts de conversión que he usado, pero que pueden rectificarse fácilmente)
Modelo original:
root@ndn-oe:/coding/tfclient# saved_model_cli show - dir /coding/ssd_inception_v2_coco_2018_01_28/01/ - all MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs: signature_def['serving_default']: The given SavedModel SignatureDef contains the following input(s): inputs['inputs'] tensor_info: dtype: DT_UINT8 shape: (-1, -1, -1, 3) name: image_tensor:0 The given SavedModel SignatureDef contains the following output(s): outputs['detection_boxes'] tensor_info: dtype: DT_FLOAT shape: (-1, 100, 4) name: detection_boxes:0 outputs['detection_classes'] tensor_info: dtype: DT_FLOAT shape: (-1, 100) name: detection_classes:0 outputs['detection_scores'] tensor_info: dtype: DT_FLOAT shape: (-1, 100) name: detection_scores:0 outputs['num_detections'] tensor_info: dtype: DT_FLOAT shape: (-1) name: num_detections:0 Method name is: tensorflow/serving/predict
El cliente TF Serving se proporciona aquí: https://gist.github.com/alexcpn/d7c28230af437dafb0d2cc7f50140eed
El resto de las importaciones están aquí, el cliente es ligeramente diferente, los nombres de entradas y salidas, por eso está en esencia https://github.com/alexcpn/tf_serving_clients
El archivo de imagen utilizado para la prueba es https://github.com/fizyr/keras-retinanet/blob/master/examples/000000008021.jpg
Paso 8: El resultado de varios modelos
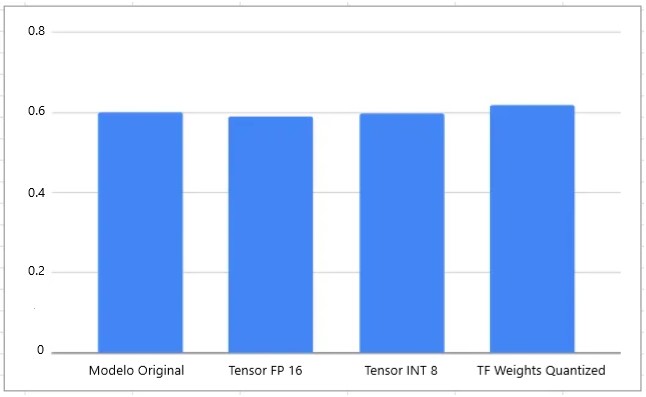
Básicamente, apenas hay diferencia entre el modelo optimizado y el no optimizado. El tamaño del lote es uno aquí:
Más detalles a continuación:
Modelo Original:
Invocaiton :coding/tfclient# python ssd_client_1.py -num_tests=1 -server=127.0.0.1:8500 -batch_size=1 -img_path=’../examples/000000008021.jpg’(‘Image path’, ‘../examples/000000008021.jpg’)
(‘original image shape=’, (480, 640, 3))
(‘Input-s shape’, (1, 800, 1066, 3)) → This is the size of input tensorOuput
(‘Label’, u’person’, ‘ at ‘, array([412, 171, 740, 624]), ‘ Score ‘, 0.9980476)
(‘Label’, u’person’, ‘ at ‘, array([ 6, 423, 518, 788]), ‘ Score ‘, 0.94931936)
(‘Label’, u’person’, ‘ at ‘, array([ 732, 473, 1065, 793]), ‘ Score ‘, 0.88419175)
(‘Label’, u’tie’, ‘ at ‘, array([529, 337, 565, 494]), ‘ Score ‘, 0.40442815)
(‘Time for ‘, 1, ‘ is ‘, 0.5993821620941162)
Transformación de Tensorflow Modelo optimizado Pesos cuantificados
(‘Label’, u’person’, ‘ at ‘, array([409, 174, 741, 626]), ‘ Score ‘, 0.99797523)
(‘Label’, u’person’, ‘ at ‘, array([ 4, 424, 524, 790]), ‘ Score ‘, 0.9549346)
(‘Label’, u’person’, ‘ at ‘, array([ 725, 472, 1064, 793]), ‘ Score ‘, 0.8900732)
(‘Label’, u’tie’, ‘ at ‘, array([527, 338, 566, 494]), ‘ Score ‘, 0.3943166)
(‘Time for ‘, 1, ‘ is ‘, 0.6182711124420 → Cuanto mayor es el tamaño del modelo, más se reduce y durante la inferencia se debe realizar una conversión de mayor precisión.
Deberías ver que el tamaño del gráfico de salida es aproximadamente una cuarta parte del original. La desventaja de este enfoque en comparación con round_weights es que se insertan operaciones de descompresión adicionales para convertir los valores de ocho bits nuevamente en punto flotante.
Pero las optimizaciones en el tiempo de ejecución de TensorFlow deberían garantizar que estos resultados se almacenen en caché, por lo que ya no debería ver el gráfico ejecutarse. lentamente.- https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/graph_transforms/README.md
Modelo convertido: TensorRT FP 16
(‘Label’, u’person’, ‘ at ‘, array([412, 171, 740, 624]), ‘ Score ‘, 0.9980476)
(‘Label’, u’person’, ‘ at ‘, array([ 6, 423, 518, 788]), ‘ Score ‘, 0.9493193)
(‘Label’, u’person’, ‘ at ‘, array([ 732, 473, 1065, 793]), ‘ Score ‘, 0.8841917)
(‘Label’, u’tie’, ‘ at ‘, array([529, 337, 565, 494]), ‘ Score ‘, 0.40442812)
(‘Time for ‘, 1, ‘ is ‘, 0.5885560512542725) →
Esperaba que esto fuera la mitad del valor original, el doble de rápido. Pero durante la optimización, TensorRT decía que podía convertir solo algunas de las operaciones admitidas*, aunque la operación de convolución se muestra como compatible aquí → https://docs.nvidia.com/deeplearning/sdk/tensorrt-support-matrix/index.html . Error planteado para esto por mí aquí. Hay 3962 operaciones de 51 tipos diferentes en el gráfico que no se convierten a TensorRT -Conv2D”
2019-04-14 08:32:31.357592: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-04-14 08:32:31.357620: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 2019-04-14 08:32:31.357645: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N 2019-04-14 08:32:31.358154: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 30480 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-32GB, pci bus id: 0000:b3:00.0, compute capability: 7.0) 2019-04-14 08:32:34.582872: I tensorflow/core/grappler/devices.cc:51] Number of eligible GPUs (core count >= 8): 1 2019-04-14 08:32:34.583019: I tensorflow/core/grappler/clusters/single_machine.cc:359] Starting new session 2019-04-14 08:32:34.583578: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0 2019-04-14 08:32:34.583610: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-04-14 08:32:34.583636: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 2019-04-14 08:32:34.583657: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N 2019-04-14 08:32:34.583986: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 30480 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-32GB, pci bus id: 0000:b3:00.0, compute capability: 7.0) 2019-04-14 08:32:36.713848: I tensorflow/contrib/tensorrt/segment/segment.cc:443] There are 3962 ops of 51 different types in the graph that are not converted to TensorRT: TopKV2, NonMaxSuppressionV2, TensorArrayWriteV3, Const, Squeeze, ResizeBilinear, Maximum, Where, Add, Placeholder, Switch, TensorArrayGatherV3, NextIteration, Greater, TensorArraySizeV3, NoOp, TensorArrayV3, LoopCond, Less, StridedSlice, TensorArrayScatterV3, ExpandDims, Exit, Cast, Identity, Shape, RealDiv, TensorArrayReadV3, Reshape, Merge, Enter, Range, Conv2D, Mul, Equal, Sub, Minimum, Tile, Pack, Split, ZerosLike, ConcatV2, Size, Unpack, Assert, DataFormatVecPermute, Transpose, Gather, Exp, Slice, Fill, (For more information see https://docs.nvidia.com/deeplearning/dgx/integrate-tf-trt/index.html#support-ops). 2019-04-14 08:32:36.848171: I tensorflow/contrib/tensorrt/convert/convert_graph.cc:913] Number of TensorRT candidate segments: 4 2019-04-14 08:32:37.129266: W tensorflow/contrib/tensorrt/convert/convert_nodes.cc:3710] Validation failed for TensorRTInputPH_0 and input slot 0: Input tensor with shape [?,?,?,3] has an unknown non-batch dimension at dim 1 2019-04-14 08:32:37.129330: W tensorflow/contrib/tensorrt/convert/convert_graph.cc:1021] TensorRT node TRTEngineOp_0 added for segment 0 consisting of 707 nodes failed: Invalid argument: Validation failed for TensorRTInputPH_0 and input slot 0: Input tensor with shape [?,?,?,3] has an unknown non-batch dimension at dim 1. Fallback to TF... 2019-04-14 08:32:37.129838: W tensorflow/contrib/tensorrt/convert/convert_nodes.cc:3710] Validation failed for TensorRTInputPH_0 and input slot 0: Input tensor with shape [?,546,?,?] has an unknown non-batch dimension at dim 2 2019-04-14 08:32:37.129859: W tensorflow/contrib/tensorrt/convert/convert_graph.cc:1021] TensorRT node TRTEngineOp_1 added for segment 1 consisting of 3 nodes failed: Invalid argument: Validation failed for TensorRTInputPH_0 and input slot 0: Input tensor with shape [?,546,?,?] has an unknown non-batch dimension at dim 2. Fallback to TF... 2019-04-14 08:32:38.309554: I tensorflow/contrib/tensorrt/convert/convert_graph.cc:1015] TensorRT node TRTEngineOp_2 added for segment 2 consisting of 3 nodes succeeded. 2019-04-14 08:32:38.420585: I tensorflow/contrib/tensorrt/convert/convert_graph.cc:1015] TensorRT node TRTEngineOp_3 added for segment 3 consisting of 4 nodes succeeded. 2019-04-14 08:32:38.644767: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:581] Optimization results for grappler item: tf_graph 2019-04-14 08:32:38.644837: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:583] constant folding: Graph size after: 6411 nodes (-1212), 10503 edges (-1352), time = 848.996ms. 2019-04-14 08:32:38.644858: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:583] layout: Graph size after: 6442 nodes (31), 10535 edges (32), time = 225.361ms. 2019-04-14 08:32:38.644874: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:583] constant folding: Graph size after: 6432 nodes (-10), 10535 edges (0), time = 559.352ms. 2019-04-14 08:32:38.644920: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:583] TensorRTOptimizer: Graph size after: 6427 nodes (-5), 10530 edges (-5), time = 2087.5769ms.
Modelo convertido: TensorRT INT 8
Se puede ver en los registros del servidor V100 que se está produciendo algo de magia de Tensor Core:
2019–04–20 01:30:39.563827: I external/org_tensorflow/tensorflow/contrib/tensorrt/kernels/trt_engine_op.cc:574] Starting calibration thread on device 0, Calibration Resource @ 0x7f4c341ac570 2019–04–20 01:30:39.563982: I external/org_tensorflow/tensorflow/contrib/tensorrt/kernels/trt_engine_op.cc:574] Starting calibration thread on device 0, Calibration Resource @ 0x7f4ce8008e60
(‘Label’, u’person’, ‘ at ‘, array([412, 171, 740, 624]), ‘ Score ‘, 0.9980476)
(‘Label’, u’person’, ‘ at ‘, array([ 6, 423, 518, 788]), ‘ Score ‘, 0.9493195)
(‘Label’, u’person’, ‘ at ‘, array([ 732, 473, 1065, 793]), ‘ Score ‘, 0.8841919)
(‘Label’, u’tie’, ‘ at ‘, array([529, 337, 565, 494]), ‘ Score ‘, 0.40442798)
(‘Time for ‘, 1, ‘ is ‘, 0.5967140197753906)
Con el tamaño de lote 2 hay un error/falta de memoria para TensorCores:
python ssd_client_1.py -num_tests=1 -server=127.0.0.1:8500 -batch_size=2 -img_path=’../examples/000000008021.jpg’ 2019–04–20 01:34:25.042337: F external/org_tensorflow/tensorflow/contrib/tensorrt/kernels/trt_engine_op.cc:227] Check failed: t.TotalBytes() == device_tensor->TotalBytes() (788424 vs. 394212) 2019–04–20 01:34:25.042373: F external/org_tensorflow/tensorflow/contrib/tensorrt/kernels/trt_engine_op.cc:227] Check failed: t.TotalBytes() == device_tensor->TotalBytes() (34656 vs. 17328) /usr/bin/tf_serving_entrypoint.sh: line 3: 6 Aborted (core dumped)
Resultados de otros modelos (y comparación con diferentes GPU)
Aquí hay algunos resultados de otras pruebas y modelos.
Los detalles aquí: https://docs.google.com/spreadsheets/d/1Sl7K6sa96wub1OXcneMk1txthQfh63b0H5mwygyVQlE/edit?usp=sharing
Modelo — Resnet_50 FP 32 y FP16
- FP32: http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz
- FP16: http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp16_savedmodel_NCHW.tar.gz
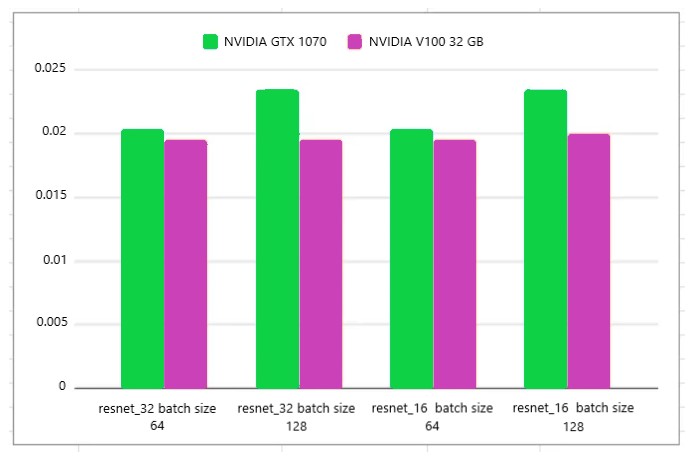
Puede ver que hay una ligera diferencia, el V100 de 32 GB toma un poco menos de tiempo que el GTX 1070 de 8 GB de nivel de consumo, cuando el tamaño del lote aumenta, se destaca el mayor recurso de memoria del V100; pero no la cantidad de núcleos CUDA.
Parece que, como se señala en otros blogs, el simple hecho de tener más núcleos CUDA no significa automáticamente que una inferencia se ejecutará más rápido. Puede depender de la memoria y también de las características del modelo.
Modelo Retinanet
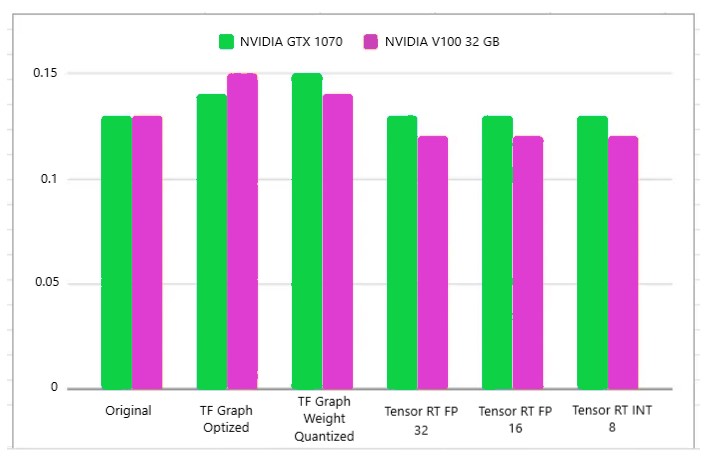
Se puede ver aquí que no hay mucha diferencia. En realidad, este fue mi primer experimento, pero se trataba de un modelo de Keras que se convirtió en un modelo congelado de TF y se optimizó.
Así que pensé que tal vez obtendría mejores resultados con un modelo escrito en TF puro como SSD. Pero no hizo mucha diferencia.
Resumen
Se puede ver que no hay mejoras drásticas en el tiempo de inferencia entre los modelos. Además, TF GraphTransform para cuantización de modelos no me ha funcionado en este ni en ningún otro modelo que probé. Generará un error por eso.
TensorRT es mejor, pero solo puede convertir algunas capas a una precisión más baja; hemos generado un error/aclaración para esto y, si funciona, con suerte, podremos ver que los modelos se ejecutan dos veces más rápido de lo anunciado. en Núcleos Tensoriales.
Referencias principales
- https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/graph_transforms/README.md
- https://colab.research.google.com/drive/1wQpWoc40kf__WSjfTqDaReMx6fFjUn48