Blog sobre las tecnologías más utilizadas del momento como: Big Data, Machine Learning e IA, además de las herramientas de programación y bibliotecas de Python, Tensorflow, Scykit-learn entre muchos otros!.
Una curva de aprendizaje es una gráfica del rendimiento los modelos de aprendizaje automático a lo largo de la experiencia o el tiempo.
Las curvas de aprendizaje son una herramienta de diagnóstico ampliamente utilizada en el aprendizaje automático para algoritmos que aprenden de un conjunto de datos de entrenamiento de forma incremental.
El modelo se puede evaluar en el conjunto de datos de entrenamiento y en un conjunto de datos de validación después de cada actualización durante el entrenamiento y se pueden crear gráficos del rendimiento medido para mostrar las curvas de aprendizaje.
La revisión de las curvas de aprendizaje de los modelos durante el entrenamiento se puede utilizar para diagnosticar problemas con el aprendizaje, como un modelo insuficiente o excesivo. Así como si los conjuntos de datos de entrenamiento y validación son adecuadamente representativos.
En esta publicación, descubrirá las curvas de aprendizaje y cómo se pueden utilizar para diagnosticar el comportamiento de aprendizaje y generalización de los modelos de aprendizaje automático. Con gráficos de ejemplo que muestran problemas de aprendizaje comunes.
Después de leer este post, sabrás:
Las curvas de aprendizaje son gráficos que muestran cambios en el desempeño del aprendizaje a lo largo del tiempo en términos de experiencia.
Las curvas de aprendizaje del rendimiento del modelo en el tren y los conjuntos de datos de validación se pueden utilizar para diagnosticar un modelo insuficiente, excesivo o bien ajustado.
Las curvas de aprendizaje del rendimiento del modelo se pueden utilizar para diagnosticar si los conjuntos de datos del tren o de validación no son relativamente representativos del dominio del problema.
Descripción general
Este tutorial está dividido en tres partes, las mismas son:
Curvas de aprendizaje.
Diagnóstico del comportamiento del modelo.
Diagnóstico de conjuntos de datos no representativos.
Generalmente, una curva de aprendizaje es un gráfico que muestra el tiempo o la experiencia en el eje x y el aprendizaje o la mejora en el eje y.
Las curvas de aprendizaje (LC) se consideran herramientas efectivas para monitorear el desempeño de los trabajadores expuestos a una nueva tarea. Las LC proporcionan una representación matemática del proceso de aprendizaje que tiene lugar a medida que se repite la tarea.
Por ejemplo, si estuviera aprendiendo un instrumento musical, su habilidad en el instrumento podría evaluarse y asignarle un puntaje numérico cada semana durante un año.
Una gráfica de los puntajes en las 52 semanas es una curva de aprendizaje y mostraría cómo su aprendizaje del instrumento ha cambiado con el tiempo.
Curva de aprendizaje : gráfico lineal del aprendizaje (eje y) sobre la experiencia (eje x).
Las curvas de aprendizaje se utilizan ampliamente en los modelos aprendizaje automático para algoritmos que aprenden (optimizan sus parámetros internos) de forma incremental con el tiemp. Como las redes neuronales de aprendizaje profundo.
La métrica utilizada para evaluar el aprendizaje podría ser maximizadora. Lo que significa que mejores puntuaciones (números más grandes) indican más aprendizaje. Un ejemplo sería la precisión de la clasificación.
Es más común utilizar una puntuación minimizadora, como pérdida o error, donde mejores puntuaciones (números más pequeños) indican más aprendizaje y un valor de 0,0 indica que el conjunto de datos de entrenamiento se aprendió perfectamente y no se cometieron errores.
Durante el entrenamiento de los modelos de aprendizaje automático, se puede evaluar el estado actual del modelo en cada paso del algoritmo de entrenamiento. Se puede evaluar en el conjunto de datos de entrenamiento para dar una idea de qué tan bien está ” aprendiendo ” el modelo.
También se puede evaluar en un conjunto de datos de validación reservados que no forma parte del conjunto de datos de entrenamiento.
La evaluación del conjunto de datos de validación da una idea de qué tan bien se ” generaliza ” el modelo.
Curva de aprendizaje del tren : curva de aprendizaje calculada a partir del conjunto de datos de entrenamiento que da una idea de qué tan bien está aprendiendo el modelo.
Curva de aprendizaje de validación : curva de aprendizaje calculada a partir de un conjunto de datos de validación reservados que da una idea de qué tan bien se está generalizando el modelo.
Es común crear curvas de aprendizaje duales para los modelos de aprendizaje automático durante el entrenamiento tanto en el conjunto de datos de entrenamiento como en el de validación.
En algunos casos, también es común crear curvas de aprendizaje para múltiples métricas, como en el caso de problemas de modelado predictivo de clasificación. Donde el modelo puede optimizarse según la pérdida de entropía cruzada y el rendimiento del modelo se evalúa utilizando la precisión de la clasificación.
En este caso, se crean dos gráficos, uno para las curvas de aprendizaje de cada métrica, y cada gráfico puede mostrar dos curvas de aprendizaje, una para cada uno de los conjuntos de datos de entrenamiento y validación.
Curvas de aprendizaje de optimización : curvas de aprendizaje calculadas según la métrica mediante la cual se optimizan los parámetros del modelo, por ejemplo, la pérdida.
Curvas de aprendizaje de rendimiento : curvas de aprendizaje calculadas sobre la métrica mediante la cual se evaluará y seleccionará el modelo, por ejemplo, precisión.
Ahora que estamos familiarizados con el uso de curvas de aprendizaje en los modelos de aprendizaje automático. Veamos algunas formas comunes observadas en los gráficos de curvas de aprendizaje.
La forma y la dinámica de una curva de aprendizaje se pueden utilizar para diagnosticar el comportamiento de los modelos de aprendizaje automático y, a su vez, quizás sugerir el tipo de cambios de configuración que se pueden realizar para mejorar el aprendizaje y/o el rendimiento.
Hay tres dinámicas comunes que probablemente observe en las curvas de aprendizaje; ellos son:
Desajustado (Underfit).
Sobreadaptado (Overfit).
Buen ajuste (Good Fit)
Echaremos un vistazo más de cerca a cada uno con ejemplos. Los ejemplos asumirán que estamos ante una métrica minimizadora. Lo que significa que puntuaciones relativas más pequeñas en el eje y indican más o mejor aprendizaje.
Curvas de aprendizaje insuficientes (Underfit Learning Curves)
El desajuste (Underfitting ) se refiere a un modelo que no puede aprender el conjunto de datos de entrenamiento.
El desajuste ocurre cuando el modelo no es capaz de obtener un valor de error suficientemente bajo en el conjunto de entrenamiento.
Un modelo insuficiente puede identificarse únicamente a partir de la curva de aprendizaje de la pérdida de entrenamiento.
Puede mostrar una línea plana o valores ruidosos de pérdida relativamente alta. Lo que indica que el modelo no pudo aprender el conjunto de datos de entrenamiento en absoluto.
A continuación se proporciona un ejemplo de esto y es común cuando el modelo no tiene una capacidad adecuada para la complejidad del conjunto de datos.
Ejemplo de curva de aprendizaje de formación que muestra un modelo insuficientemente adaptado que no tiene capacidad suficiente.
Un modelo insuficiente también puede identificarse por una pérdida de entrenamiento que está disminuyendo y continúa disminuyendo al final del gráfico.
Esto indica que el modelo es capaz de seguir aprendiendo y de posibles mejoras adicionales y que el proceso de formación se detuvo prematuramente.
Ejemplo de curva de aprendizaje de capacitación que muestra un modelo insuficiente que requiere capacitación adicional.
Un gráfico de curvas de aprendizaje muestra un desajuste si:
La pérdida de entrenamiento se mantiene estable independientemente del entrenamiento.
La pérdida de entrenamiento continúa disminuyendo hasta el final del entrenamiento.
Curvas de aprendizaje sobreadaptadas (Overfit Learning Curves)
El sobreajuste se refiere a un modelo que ha aprendido demasiado bien el conjunto de datos de entrenamiento. Incluido el ruido estadístico o las fluctuaciones aleatorias en el conjunto de datos de entrenamiento.
… ajustar un modelo más flexible requiere estimar un mayor número de parámetros. Estos modelos más complejos pueden conducir a un fenómeno conocido como sobreajuste de datos, que esencialmente significa que siguen los errores o el ruido demasiado de cerca.
El problema con el sobreajuste es que cuanto más especializado se vuelve el modelo en los datos de entrenamiento menos capaz es de generalizarse a nuevos datos, lo que resulta en un aumento en el error de generalización.
Este aumento en el error de generalización se puede medir por el desempeño del modelo en el conjunto de datos de validación.
Este es un ejemplo de sobreajuste de datos, […]. Es una situación indeseable porque el ajuste obtenido no producirá estimaciones precisas de la respuesta en nuevas observaciones que no formaban parte del conjunto de datos de entrenamiento original.
Esto ocurre a menudo si el modelo tiene más capacidad de la necesaria para el problema y, a su vez, demasiada flexibilidad. También puede ocurrir si el modelo se entrena durante demasiado tiempo.
Un gráfico de curvas de aprendizaje muestra sobreajuste si:
La gráfica de pérdida de entrenamiento continúa disminuyendo con la experiencia.
El gráfico de pérdida de validación disminuye hasta cierto punto y comienza a aumentar nuevamente.
El punto de inflexión en la pérdida de validación puede ser el punto en el que el entrenamiento podría detenerse. Ya que la experiencia posterior a ese punto muestra la dinámica del sobreajuste.
El siguiente gráfico de ejemplo demuestra un caso de sobreajuste:
Ejemplo de curvas de aprendizaje de validación y entrenamiento que muestran un modelo sobreajustado.
Curvas de aprendizaje de buen ajuste (Diagnosing Unrepresentative Datasets)
Un buen ajuste es el objetivo del algoritmo de aprendizaje y existe entre un modelo sobreadaptado y uno insuficiente.
Un buen ajuste se identifica por una pérdida de entrenamiento y validación que disminuye hasta un punto de estabilidad con una brecha mínima entre los dos valores de pérdida finales.
La pérdida del modelo casi siempre será menor en el conjunto de datos de entrenamiento que en el conjunto de datos de validación. Esto significa que deberíamos esperar cierta brecha entre las curvas de aprendizaje del tren y de la pérdida de validación. Esta brecha se conoce como “brecha de generalización”.
Un gráfico de curvas de aprendizaje muestra un buen ajuste si:
La gráfica de pérdida de entrenamiento disminuye hasta un punto de estabilidad.
La gráfica de pérdida de validación disminuye hasta un punto de estabilidad y tiene una pequeña brecha con la pérdida de entrenamiento.
El entrenamiento continuo de un buen ajuste probablemente conducirá a un sobreajuste.
El siguiente gráfico de ejemplo demuestra un caso de buen ajuste:
Ejemplo de curvas de aprendizaje de capacitación y validación que muestran un buen ajuste.
Diagnóstico de conjuntos de datos no representativos (Diagnosing Unrepresentative Datasets)
Las curvas de aprendizaje también se pueden utilizar para diagnosticar las propiedades de un conjunto de datos y si es relativamente representativo.
Un conjunto de datos no representativo significa un conjunto de datos que puede no capturar las características estadísticas relativas a otro conjunto de datos extraído del mismo dominio, como entre un tren y un conjunto de datos de validación. Esto puede ocurrir comúnmente si la cantidad de muestras en un conjunto de datos es demasiado pequeña en relación con otro conjunto de datos.
Hay dos casos comunes que se podrían observar; ellos son:
El conjunto de datos de entrenamiento es relativamente poco representativo.
El conjunto de datos de validación es relativamente poco representativo.
Conjunto de datos de trenes no representativos (Unrepresentative Train Dataset)
Un conjunto de datos de entrenamiento no representativo significa que el conjunto de datos de entrenamiento no proporciona suficiente información para aprender el problema. En relación con el conjunto de datos de validación utilizado para evaluarlo.
Esto puede ocurrir si el conjunto de datos de entrenamiento tiene muy pocos ejemplos en comparación con el conjunto de datos de validación.
Esta situación se puede identificar mediante una curva de aprendizaje para la pérdida de entrenamiento que muestra una mejora y de manera similar una curva de aprendizaje para la pérdida de validación que muestra una mejora. Pero permanece una gran brecha entre ambas curvas.
Ejemplo de curvas de aprendizaje de capacitación y validación que muestran un conjunto de datos de capacitación que puede ser demasiado pequeño en relación con el conjunto de datos de validación.
Ejemplo de entrenamiento y Curvas de aprendizaje de validación que muestran un conjunto de datos de entrenamiento que puede ser demasiado pequeño en relación con el conjunto de datos de validación
Conjunto de datos de validación no representativos (Unrepresentative Validation Dataset)
Un conjunto de datos de validación no representativo significa que el conjunto de datos de validación no proporciona información suficiente para evaluar la capacidad del modelo para generalizar.
Esto puede ocurrir si el conjunto de datos de validación tiene muy pocos ejemplos en comparación con el conjunto de datos de entrenamiento.
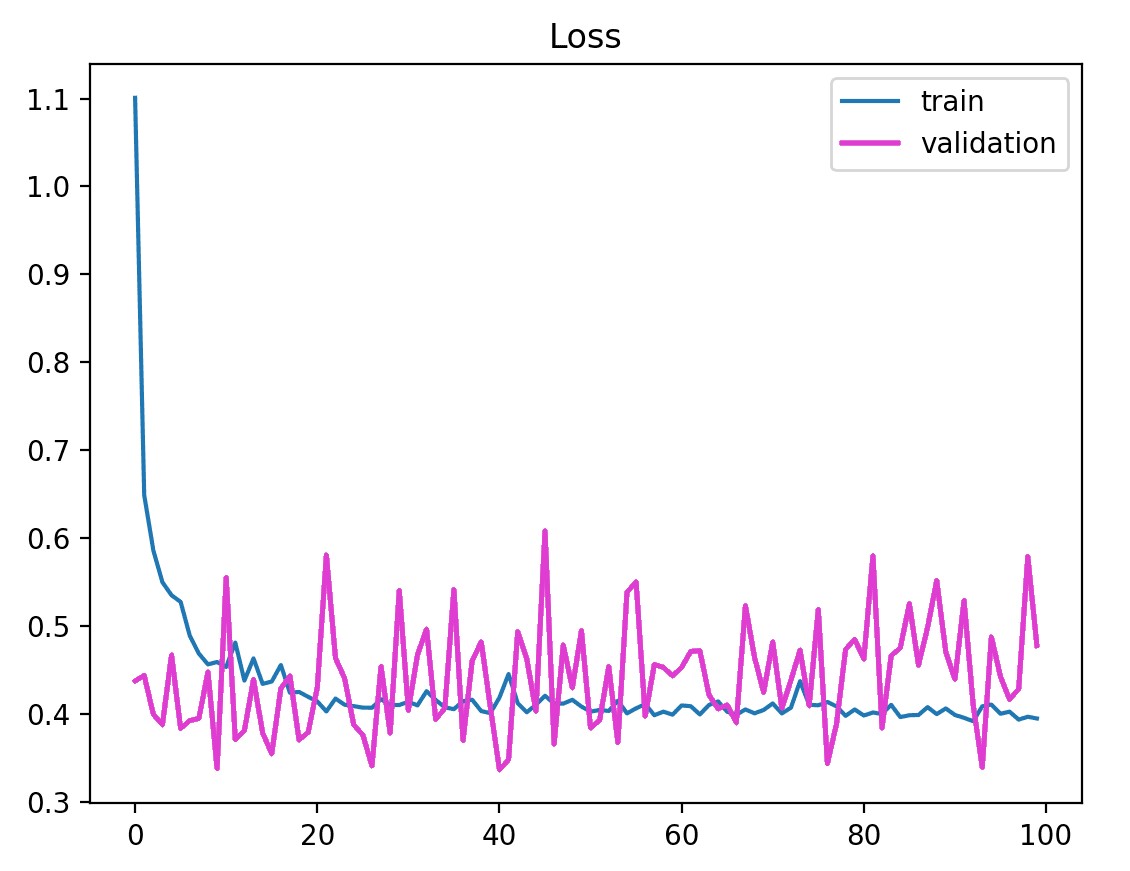
Este caso se puede identificar mediante una curva de aprendizaje para la pérdida de entrenamiento que parece un buen ajuste (u otros ajustes) y una curva de aprendizaje para la pérdida de validación que muestra movimientos ruidosos alrededor de la pérdida de entrenamiento.
Ejemplo de curvas de aprendizaje de capacitación y validación que muestran un conjunto de datos de validación que puede ser demasiado pequeño en relación con el conjunto de datos de capacitación.
También puede identificarse por una pérdida de validación que es menor que la pérdida de entrenamiento. En este caso, indica que el conjunto de datos de validación puede ser más fácil de predecir para el modelo que el conjunto de datos de entrenamiento.
Ejemplo de curvas de aprendizaje de validación y entrenamiento que muestran un conjunto de datos de validación que es más fácil de predecir que el conjunto de datos de entrenamiento.
En esta publicación, descubrió las curvas de aprendizaje y cómo se pueden utilizar para diagnosticar el comportamiento de aprendizaje y generalización de los modelos de aprendizaje automático.
Específicamente, aprendiste:
Las curvas de aprendizaje son gráficos que muestran cambios en el desempeño del aprendizaje a lo largo del tiempo en términos de experiencia.
Las curvas de aprendizaje del rendimiento del modelo en el tren y los conjuntos de datos de validación se pueden utilizar para diagnosticar un modelo insuficiente, excesivo o bien ajustado.
Las curvas de aprendizaje del rendimiento del modelo se pueden utilizar para diagnosticar si los conjuntos de datos del tren o de validación no son relativamente representativos del dominio del problema.