
Los modelos de lenguajes grandes (AWS LLM) han captado la imaginación y la atención de desarrolladores, científicos, tecnólogos, emprendedores y ejecutivos de varias industrias.
Estos modelos se pueden utilizar para responder preguntas, resumir, traducir y más en aplicaciones como agentes conversacionales para atención al cliente, creación de contenido para marketing y asistentes de codificación.
Recientemente, Meta lanzó Llama 2 tanto para investigadores como para entidades comerciales, sumándose a la lista de otros AWS LLM, incluidos MosaicML MPT y Falcon .
En esta publicación, explicamos cómo ajustar Llama 2 en AWS Trainium , un acelerador diseñado específicamente para la capacitación AWS LLM, para reducir los tiempos y costos de capacitación. Revisamos los scripts de ajuste proporcionados por AWS Neuron SDK (usando NeMo Megatron-LM), las diversas configuraciones que utilizamos y los resultados de rendimiento que vimos.
AWS LLM: Sobre el modelo Llama 2
Al igual que el modelo Llama 1 anterior y otros modelos como GPT, Llama 2 utiliza la arquitectura de solo decodificador del Transformer. Viene en tres tamaños: 7 mil millones, 13 mil millones y 70 mil millones de parámetros.
En comparación con Llama 1, Llama 2 duplica la longitud del contexto de 2000 a 4000 y utiliza atención de consultas agrupadas (solo para 70B). Los modelos preentrenados de Llama 2 se entrenan con 2 billones de tokens y sus modelos ajustados se han entrenado con más de 1 millón de anotaciones humanas.
AWS LLM: Entrenamiento distribuido de Llama 2
Para acomodar Llama 2 con una longitud de secuencia de 2000 y 4000, implementamos el script usando NeMo Megatron para Trainium que admite paralelismo de datos (DP), paralelismo tensorial (TP) y paralelismo de canalización (PP).
Para ser específicos, con la nueva implementación de algunas funciones como la incrustación de palabras desatadas, la incrustación rotativa, RMSNorm y la activación de Swiglu, utilizamos el script genérico de GPT Neuron Megatron-LM para respaldar el script de entrenamiento de Llama 2.
Nuestro procedimiento de capacitación de alto nivel es el siguiente: para nuestro entorno de capacitación, utilizamos un clúster de instancias múltiples administrado por el sistema SLURM para la capacitación y programación distribuida bajo el marco NeMo.
Primero, descargue el modelo Llama 2 y los conjuntos de datos de entrenamiento y procéselos usando el tokenizador Llama 2. Por ejemplo, para utilizar el conjunto de datos RedPajama, utilice el siguiente comando:
Para obtener orientación detallada sobre la descarga de modelos y el argumento del script de preprocesamiento. Consulte Descargar el conjunto de datos y el tokenizador de LlamaV2 .
A continuación, compila el modelo:
Después de compilar el modelo, inicie el trabajo de entrenamiento con el siguiente script que ya está optimizado con la mejor configuración e hiperparámetros para Llama 2 (incluido en el código de ejemplo):
Por último, monitoreamos TensorBoard para realizar un seguimiento del progreso del entrenamiento:
Para obtener el código de ejemplo completo y los scripts que mencionamos, consulte el tutorial de Llama 7B y el código NeMo en Neuron SDK para seguir pasos más detallados.
Experimentos de ajuste
Ajustamos el modelo 7B en los conjuntos de datos OSCAR (Open Super-large Crawled ALMAnaCH corpus) y QNLI (NLI de respuesta a preguntas) en un entorno Neuron 2.12 (PyTorch).
Para cada longitud de secuencia de 2000 y 4000, optimizamos algunas configuraciones, como batchsizey gradient_accumulation, para la eficiencia del entrenamiento.
Como estrategia de ajuste, adoptamos un ajuste completo de todos los parámetros (aproximadamente 500 pasos). Que se puede extender al entrenamiento previo con pasos más largos y conjuntos de datos más grandes (por ejemplo, 1T RedPajama).
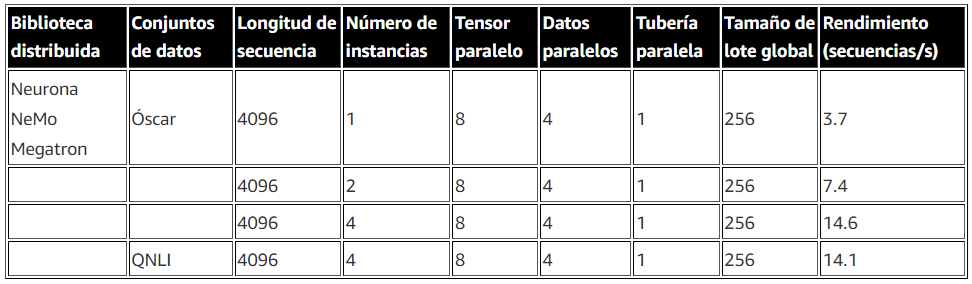
El paralelismo de secuencia también se puede habilitar para permitir a NeMo Megatron ajustar con éxito modelos con una longitud de secuencia mayor de 4000. La siguiente tabla muestra los resultados de configuración y rendimiento del experimento de ajuste fino de Llama 7B. El rendimiento aumenta casi linealmente a medida que el número de instancias aumenta hasta 4.
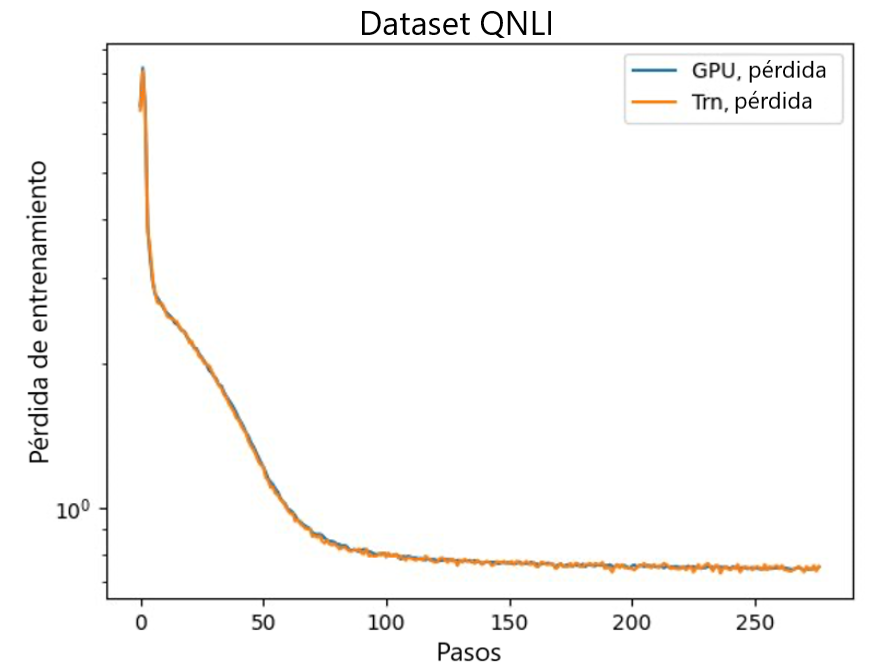
El último paso es verificar la precisión con el modelo base. Implementamos un script de referencia para experimentos de GPU y confirmamos que las curvas de entrenamiento para GPU y Trainium coincidían como se muestra en la siguiente figura.
La figura ilustra las curvas de pérdida sobre la cantidad de pasos de entrenamiento en el conjunto de datos QNLI. Se adoptó precisión mixta para GPU (azul) y bf16 con redondeo estocástico predeterminado para Trainium (naranja):
Conclusión
En esta publicación, mostramos que Trainium ofrece un alto rendimiento y un ajuste fino rentable de Llama 2. Para obtener más recursos sobre el uso de Trainium para el entrenamiento previo distribuido y el ajuste de sus modelos de IA generativa usando NeMo Megatron, consulte AWS Neuron Reference. Para NeMo Megatrón .