La IA ha llegado tan lejos ahora y están evolucionando varios modelos de IA de última generación que se utilizan en chatbots, robots humanoides, automóviles autónomos, etc. Se ha convertido en la tecnología de más rápido crecimiento, y la detección y clasificación de objetos son de moda estos días.
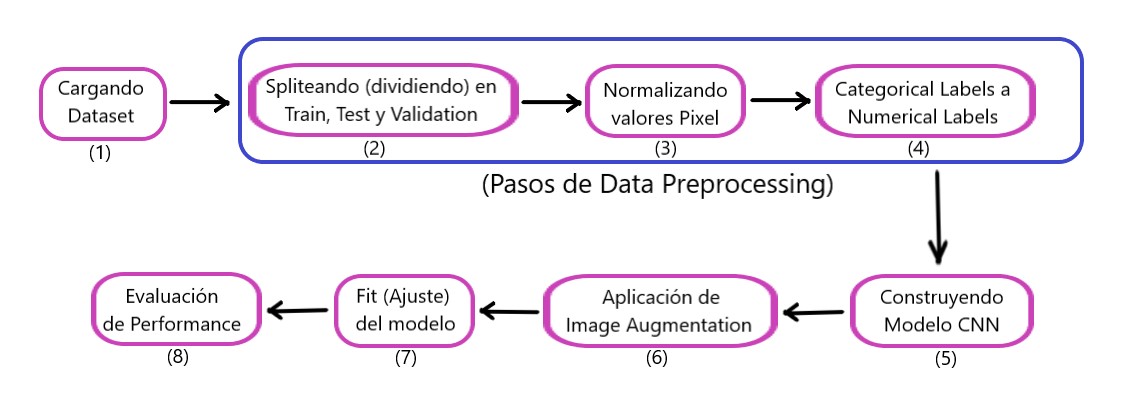
En esta publicación de blog, cubriremos los pasos completos para crear y entrenar un modelo de clasificación de imágenes desde cero utilizando una red neuronal convolucional.
Utilizaremos el conjunto de datos Cifar-10 disponible públicamente para entrenar el modelo. Este conjunto de datos es único porque contiene imágenes de objetos que se ven todos los días, como automóviles, aviones, perros, gatos, etc.
Al entrenar la red neuronal para estos objetos, desarrollaremos sistemas inteligentes para clasificar tales cosas en el mundo real. Contiene más de 60000 imágenes de tamaño 32×32 de 10 tipos diferentes de objetos. Al final de este tutorial, tendrá un modelo que puede determinar el objeto en función de sus características visuales.

Cubriremos todo desde cero, por lo que si aún no ha aprendido sobre la implementación práctica de las redes neuronales, está completamente bien.
El único requisito previo de este tutorial es su tiempo y los conocimientos básicos de Python. Al final de este tutorial, compartiré el archivo colaborativo que contiene el código completo. ¡Empecemos!
Aquí está el flujo de trabajo completo de este tutorial:
- Importación de bibliotecas necesarias
- Carga de los datos
- Preprocesamiento de los datos
- Construyendo el modelo
- Evaluación del rendimiento del modelo
TensorFlow: Importación de bibliotecas necesarias
Tienes que instalar algunos módulos para comenzar con el proyecto. Usaré Google Colab, ya que proporciona capacitación gratuita sobre GPU y, al final, les proporcionaré el archivo colaborativo que contiene el código completo.
Aquí está el comando para instalar las bibliotecas necesarias:
$ pip install tensorflow, numpy, keras, sklearn, matplotlib
Importando las bibliotecas a un archivo Python:
from numpy import * from pandas import * import matplotlib.pyplot as plotter # Split the data into training and testing sets. from sklearn.model_selection import train_test_split # Libraries used to evaluate our trained model. from sklearn.metrics import classification_report, confusion_matrix import keras # Loading our dataset. from keras.datasets import cifar10 # Used for data augmentation. from keras.preprocessing.image import ImageDataGenerator # Below are some layers used to train convolutional nueral network. from keras.models import Sequential from keras.layers import Dense, Dropout, Activation from keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten
- Numpy: se utiliza para cálculos de matrices eficientes de grandes conjuntos de datos que contienen imágenes.
- Tensorflow: es una biblioteca de aprendizaje automático de código abierto desarrollada por Google. Proporciona numerosas funciones para crear modelos grandes y escalables.
- Keras: otra API de red neuronal de alto nivel se ejecuta sobre TensorFlow.
- Matplotlib: esta biblioteca de Python crea diagramas y gráficos, proporcionando una mejor visualización de datos.
- Sklearn: proporciona funciones para realizar tareas de preprocesamiento de datos y extracción de características para el conjunto de datos. Contiene funciones incorporadas para encontrar las métricas de evaluación de un modelo como exactitud, precisión, falsos positivos, falsos negativos, etc.
Ahora, pasemos al paso de carga de datos:
1. TensorFlow: Cargando los datos
Esta sección cargará nuestro conjunto de datos y realizará la división del tren-prueba.
Carga y división de datos:
# number of classes
nc = 10
(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()
(
(training_data),
(validation_data),
(training_label),
(validation_label),
) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)
training_data = training_data.astype("float32")
testing_data = testing_data.astype("float32")
validation_data = validation_data.astype("float32")
El conjunto de datos cifar10 se carga directamente desde la biblioteca de conjuntos de datos de Keras. Y estos datos también se dividen en datos de entrenamiento y datos de prueba.
Los datos de entrenamiento se utilizan para entrenar el modelo para que pueda identificar patrones en él.
Y los datos de prueba permanecen invisibles para el modelo y se utilizan para comprobar su rendimiento, es decir, cuántos puntos de datos se predicen correctamente con respecto al total de puntos de datos.
training_labelcontiene la etiqueta correspondiente a la imagen presente en training_data.
Luego, los datos de entrenamiento se dividen nuevamente en datos de validación utilizando la función sklearn incorporada train_test_split.
Los datos de validación se utilizan para seleccionar y ajustar el modelo final. Finalmente, todos los datos de entrenamiento, prueba y validación se convierten a decimales flotantes de 32 bits.
Ahora, la carga de nuestro conjunto de datos ha terminado. En la siguiente sección, le realizaremos algunos pasos de preprocesamiento.
2. TensorFlow: Preprocesamiento de datos
El preprocesamiento de datos es el primer y más crucial paso en el desarrollo de un modelo de aprendizaje automático. Veamos cómo hacerlo.
# Normalization training_data /= 255 testing_data /= 255 validation_data /= 255 # One Hot Encoding training_label = keras.utils.to_categorical(training_label, nc) testing_label = keras.utils.to_categorical(testing_label, nc) validation_label = keras.utils.to_categorical(validation_label, nc) # Printing the dataset print("Training: ", training_data.shape, len(training_label)) print("Validation: ", validation_data.shape, len(validation_label)) print("Testing: ", testing_data.shape, len(testing_label))
Producción:
Training: (40000, 32, 32, 3) 40000 Validation: (10000, 32, 32, 3) 10000 Testing: (10000, 32, 32, 3) 10000
El conjunto de datos contiene imágenes de 10 clases y el tamaño de cada imagen es de 32×32 píxeles. Cada píxel tiene un valor de 0 a 255 y debemos normalizarlo entre 0 y 1 para facilitar el proceso de cálculo. Y después de eso, convertiremos las etiquetas categóricas en etiquetas codificadas en caliente. Esto se hace para convertir los datos categóricos en datos numéricos para que podamos aplicar algoritmos de aprendizaje automático sin ningún problema.
Ahora, pasemos a la construcción del modelo CNN.
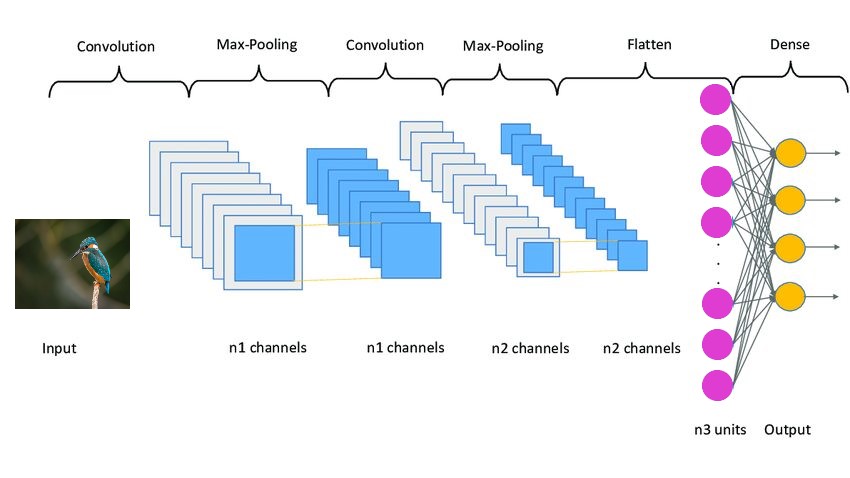
3. Construyendo el modelo CNN en TensorFlow
El modelo CNN funciona en 3 etapas. La primera etapa consta de capas convolucionales que extraen características relevantes de las imágenes. La segunda etapa consiste en agrupar capas utilizadas para reducir la dimensionalidad de las imágenes.
También ayuda a reducir el sobreajuste del modelo. Y la tercera etapa consta de capas densas que convierten la imagen bidimensional en una matriz unidimensional.
Y finalmente, esta matriz se alimenta a las capas completamente conectadas, que realizan la predicción final.
Aquí está el código:
model = Sequential()
model.add(
Conv2D(32, (3, 3), padding="same", activation="relu", input_shape=(32, 32, 3))
)
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(96, (3, 3), padding="same", activation="relu"))
model.add(Conv2D(96, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.4))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.4))
model.add(Dense(nc, activation="softmax"))
Hemos aplicado los tres conjuntos de capas, cada uno de los cuales contiene dos capas convolucionales, una capa de agrupación máxima y una capa de abandono. La capa Conv2D toma input_shapecomo (32, 32, 3), que debe ser igual a las dimensiones de la imagen.
Cada capa de Conv2D también toma una función de activación, es decir, ‘relu’. Las funciones de activación se utilizan para aumentar la no linealidad en el sistema.
En términos más simples, decide si la neurona necesita activarse o no en función de un umbral determinado. Hay muchos tipos de funciones de activación como ‘ReLu’, ‘Tanh’, ‘Sigmoid’, ‘Softmax’, etc., que utilizan diferentes algoritmos para decidir la activación de la neurona.
Después de eso, se agregan la capa de aplanamiento y las capas completamente conectadas, con varias capas de abandono entre ellas. La capa de abandono rechaza aleatoriamente parte de la contribución de las neuronas a la capa neta.
El parámetro que contiene define el grado de rechazo. Se utiliza principalmente para evitar un ajuste excesivo.
A continuación se muestra una imagen de muestra de cómo se ve la arquitectura de un modelo CNN:
4. Compilando el modelo
Ahora compilaremos y prepararemos el modelo para la capacitación:
# initiate Adam optimizer opt = keras.optimizers.Adam(lr=0.0001) model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"]) # obtaining the summary of the model model.summary()
Producción:

Hemos utilizado el optimizador Adam con una tasa de aprendizaje de 0,0001. El optimizador decide cómo cambia el comportamiento del modelo en respuesta a la salida de la función de pérdida. La tasa de aprendizaje es la cantidad de pesos actualizados durante el entrenamiento o el tamaño del paso. Es un hiperparámetro configurable que no debe ser ni demasiado pequeño ni demasiado grande.
5. Ajuste del modelo
Ahora, ajustaremos el modelo a nuestros datos de entrenamiento y comenzaremos el proceso de entrenamiento. Pero antes de eso, usaremos el aumento de imágenes para aumentar la cantidad de imágenes de muestra.
El aumento de imágenes utilizado en redes neuronales convolucionales aumentará las imágenes de entrenamiento sin requerir nuevas imágenes. Replicará las imágenes produciendo cierta cantidad de variación en ellas. Se puede hacer rotando la imagen hasta cierto punto, agregando ruido, volteándola horizontal o verticalmente, etc.
augmentor = ImageDataGenerator(
width_shift_range=0.4,
height_shift_range=0.4,
horizontal_flip=False,
vertical_flip=True,
)
# fitting in augmentor
augmentor.fit(training_data)
# obtaining the history
history = model.fit(
augmentor.flow(training_data, training_label, batch_size=32),
epochs=100,
validation_data=(validation_data, validation_label),
)
Producción:
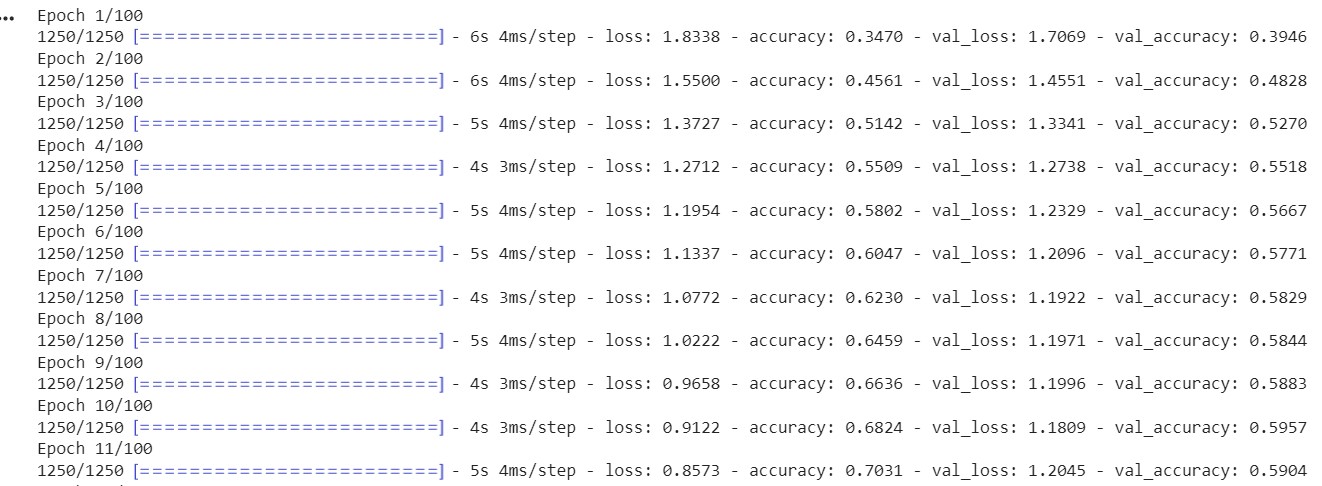
ImageDataGenerator()La función se utiliza para crear imágenes aumentadas. Se fit()utiliza para adaptarse al modelo. Toma como entrada los datos de entrenamiento y validación, el tamaño del lote y el número de épocas.
El tamaño del lote es la cantidad de muestras procesadas antes de que se actualice el modelo. Un hiperparámetro crucial debe ser mayor que uno y menor que igual al número de muestras. Por lo general, 32 o 64 se consideran los mejores tamaños de lote.
El número de épocas representa cuántas veces se procesan todas las muestras una vez individualmente tanto en el avance como en el retroceso de la red. 100 épocas significan que todo el conjunto de datos pasa por el modelo 100 veces y el modelo se ejecuta 100 veces.
Nuestro modelo está entrenado y ahora evaluaremos su desempeño en el conjunto de prueba.
6. Tensorflow: Evaluación del rendimiento del modelo
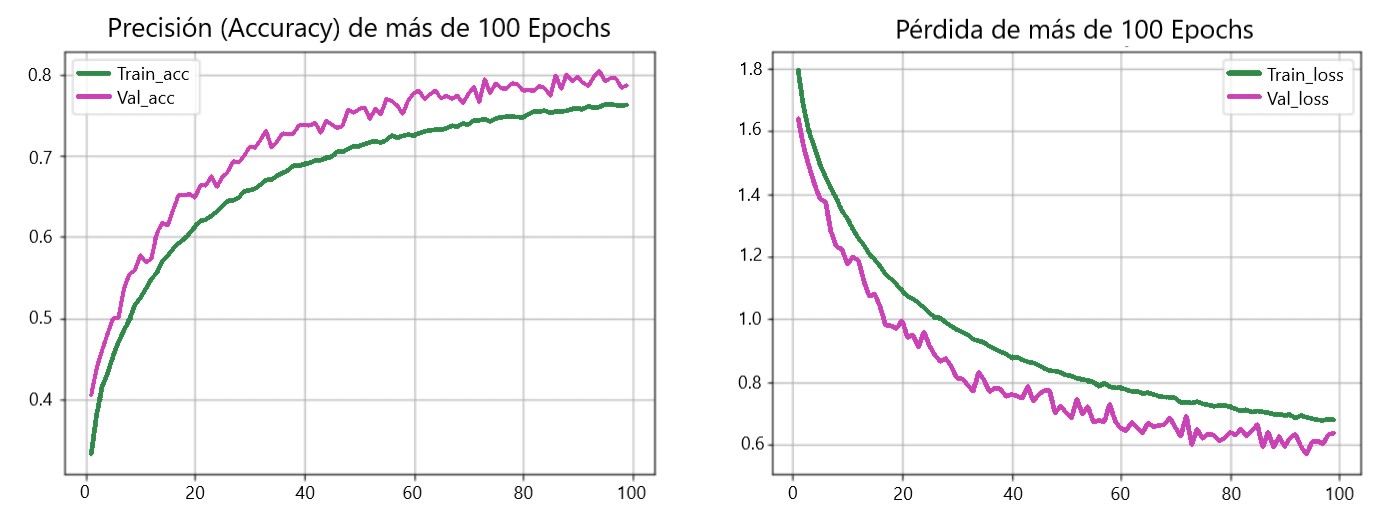
En esta sección, verificaremos la precisión y pérdida del modelo en el conjunto de prueba. Además, trazaremos un gráfico entre Accuracy Vs Epoch y Loss Vs Epoch para los datos de entrenamiento y validación.
model.evaluate(testing_data, testing_label)
Output:
313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545 [0.8554493188858032, 0.7545000195503235]
Nuestro modelo logró una precisión del 75,34% con una pérdida de 0,8554. Esta precisión se puede aumentar ya que no se trata de un modelo de última generación. Utilicé este modelo para explicar el proceso y el flujo de construcción de un modelo.
La precisión del modelo CNN depende de muchos factores como la elección de capas, la selección de hiperparámetros, el tipo de conjunto de datos utilizado, etc.
Ahora trazaremos las curvas para comprobar el sobreajuste en el modelo:
def acc_loss_curves(result, epochs):
acc = result.history["accuracy"]
# obtaining loss and accuracy
loss = result.history["loss"]
# declaring values of loss and accuracy
val_acc = result.history["val_accuracy"]
val_loss = result.history["val_loss"]
# plotting the figure
plotter.figure(figsize=(15, 5))
plotter.subplot(121)
plotter.plot(range(1, epochs), acc[1:], label="Train_acc")
plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")
# giving title to plot
plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)
plotter.legend()
plotter.grid(True)
# passing value 122
plotter.subplot(122)
# using train loss
plotter.plot(range(1, epochs), loss[1:], label="Train_loss")
plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")
# using ephocs
plotter.title("Loss over " + str(epochs) + " Epochs", size=15)
plotter.legend()
# passing true values
plotter.grid(True)
# printing the graph
plotter.show()
acc_loss_curves(history, 100)
Output:
Encuentre el enlace de Google Colab utilizado en este artículo: Enlace
Conclusión
Este artículo muestra todo el proceso de construcción y entrenamiento de una red neuronal convolucional desde cero. Obtuvimos alrededor del 75% de precisión. Puede jugar con los hiperparámetros y utilizar diferentes conjuntos de capas convolucionales y de agrupación para mejorar la precisión.
También puedes probar Transfer Learning, que utiliza modelos previamente entrenados como ResNet o VGGNet y ofrece muy buena precisión en algunos casos. Podemos hablar más sobre ello en otros artículos si quieres.
Hasta entonces, sigue leyendo y sigue aprendiendo. No dudes en ponerte en contacto conmigo en Linkedin en caso de cualquier duda o sugerencia.