Los modelos de Machine Learning se están abriendo paso en las aplicaciones del mundo real.
Todos escuchamos noticias sobre los sistemas de Machine Learning para calificación de crédito, cuidado de la salud y predicción del crimen. Podemos prever fácilmente un sistema de puntuación social impulsado por modelos de Machine Learning.
Gracias al rápido ritmo de investigación de modelos de Machine Learning y los excelentes resultados obtenidos en experimentos controlados. Cada vez más personas parecen estar abiertas a la posibilidad de tener modelos estadísticos que rigen partes importantes de nuestras vidas.
Sin embargo, la mayoría de estos sistemas se ven como cajas negras. Máquinas de numeración oscuras que producen una respuesta simple Sí / No; como máximo, a la respuesta le sigue un “porcentaje de confianza” insatisfactorio. Esto a menudo es un obstáculo para la adopción total de tales sistemas para decisiones críticas.
En el cuidado de la salud o préstamos, un especialista no examina una enorme base de datos para descubrir relaciones complejas. Un especialista aplica educación previa y conocimiento de dominio para tomar la mejor decisión para un problema determinado.
Muy probablemente, una evaluación basada en el análisis de datos, incluso con la ayuda de una herramienta automatizada. Pero, en última instancia, una decisión respaldada por un razonamiento plausible y explicable.
Es por eso que hay motivaciones para los préstamos rechazados y los tratamientos médicos. Además, tales explicaciones a menudo nos ayudan a juzgar a un buen especialista de uno malo.
La mayoría de nosotros tendemos a resistirnos a aceptar decisiones que parecen arbitrarias; es crucial entender cuán importantes se han tomado las decisiones.
Algunos objetivos del mundo real de sistemas de Machine Learning interpretables:
- Confianza: confianza en las predicciones del sistema.
- Causalidad: ayuda a inferir propiedades del mundo natural.
- Generalización: tratar con un entorno no estacionario.
- Informativo: incluir información útil sobre el proceso de decisión.
- Feria y Ética en la adopción de decisiones: prevenir los resultados discriminatorios.
Está claro que a la sociedad le importa el aprendizaje automático interpretable.
Me gustaría ir más allá: aquellos que crean modelos de Machine Learning también deben preocuparse por la interpretabilidad. Los profesionales e ingenieros de Machine Learning deben buscar la interpretabilidad como un medio para construir mejores modelos.
El propósito de este artículo no es presentar los detalles de las herramientas y técnicas de interpretación y cómo aplicarlas. Más bien, me gustaría ofrecer una visión de por qué estas herramientas son importantes para la práctica de modelos de Machine Learning y revisar algunas de mis herramientas favoritas.
Los sistemas de Machine Learning (por ejemplo, para clasificación) están diseñados y optimizados para identificar patrones en grandes volúmenes de datos.
Es increíblemente fácil construir un sistema capaz de encontrar correlaciones muy complejas entre las variables de entrada y la categoría objetivo. ¿Datos estructurados? Lanza un XGBoost a él. Datos no estructurados? ¡Una red profunda para rescatar!
Un flujo de trabajo de Machine Learning típico consiste en explorar datos, preprocesar funciones, entrenar un modelo, luego validar el modelo y decidir si está listo para ser utilizado en producción.
Si no, retroceda, a menudo diseñando mejores características para nuestro clasificador. La mayoría de las veces, la validación del modelo se basa en una medida del poder predictivo: por ejemplo, el área bajo la curva ROC a menudo es bastante confiable.
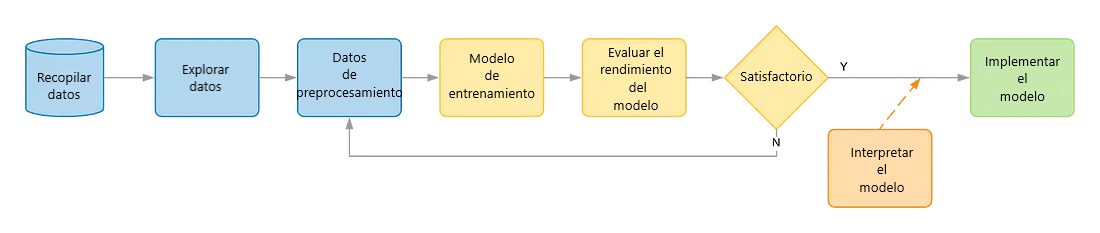
Sin embargo, durante la construcción del modelo, muchas decisiones de diseño pueden cambiar ligeramente el modelo. No solo la elección del clasificador, sino innumerables decisiones en cada paso de preproceso.
Resulta que, dado un problema no trivial, hay innumerables modelos de Machine Learning con alto poder predictivo, cada uno contando una historia completamente diferente sobre los datos. Algunas historias pueden simplemente estar equivocadas, aunque parezcan funcionar para un conjunto de datos específico.
Esto se ha llamado espléndidamente el Efecto Rashomon. ¿Cuál de esos modelos deberíamos implementar en producción para tomar decisiones críticas? ¿Deberíamos tomar siempre el modelo con el AUC más alto absoluto? ¿Cómo deberíamos diferenciar entre buenas y malas decisiones de diseño?
El enfoque y las herramientas de aprendizaje de máquina interpretables nos ayudan a tomar esta decisión y, más ampliamente, hacer una mejor validación del modelo.
Lo cual es más que simplemente mirar el AUC, pero responder preguntas tales como: ¿cómo varía la salida del modelo con respecto al valor de cada característica? ¿Las relaciones coinciden con la intuición humana y / o el conocimiento del dominio? ¿Qué características pesan más para una observación específica?
Podemos dividir aproximadamente la interpretabilidad en análisis globales y locales.
Los métodos de análisis global le darán un sentido general de la relación entre una característica y el resultado del modelo. Por ejemplo: ¿cómo el tamaño de la casa influye en la posibilidad de ser vendida en los próximos tres meses?
Los métodos de análisis locales lo ayudarán a comprender una decisión en particular. Suponga que tiene una alta probabilidad de incumplimiento (no devuelto) para una solicitud de préstamo determinada. Por lo general, desea saber qué características llevaron al modelo a clasificar la aplicación como de alto riesgo.
Métodos globales
Para el análisis global, comience por usar Parcelas de dependencia parcial y Expectativa condicional individual (ICE).
El gráfico de dependencia parcial muestra la probabilidad de una cierta clase dados diferentes valores de la característica. Es un método global: tiene en cuenta todas las instancias y hace una declaración sobre la relación global de una función con el resultado previsto.
Un gráfico de dependencia parcial le da una idea de cómo responde el modelo a una característica en particular. Puede mostrar si la relación entre el objetivo y una característica es lineal, monótona o más compleja.
Por ejemplo, la trama puede mostrar una influencia creciente monótona de los Medidores Cuadrados sobre el precio de la vivienda (eso es bueno). O puede detectar una situación extraña cuando gastar más dinero es mejor para su puntaje crediticio. Créame, sucede.
El diagrama de dependencia parcial es un método global porque no se enfoca en instancias específicas, sino en un promedio general. El equivalente de PDP para observaciones individuales se llama diagrama de Expectativa Condicional Individual (ICE).
Los diagramas de ICE dibujan una línea por instancia, que representa cómo la predicción de la instancia cambia cuando la característica cambia.
Siendo un promedio global, PDP puede no capturar relaciones heterogéneas que provienen de la interacción entre las características. A menudo es bueno equipar su Parcela de Dependencia Parcial con líneas ICE para obtener mucha más información.
Métodos locales
Uno de los enfoques más recientes y prometedores para el análisis local es SHapley Additive ExPlanations. Su objetivo es responder a la pregunta: ¿Por qué el modelo tomó esa decisión específica para una instancia? SHAP asigna a cada característica un valor de importancia para una predicción particular.
Antes de la producción, puede implementar su modelo en un entorno de prueba y enviar datos de, por ejemplo, un conjunto de prueba de retención.
Calcular los valores SHAP para la observación en ese conjunto de prueba puede representar una aproximación interesante de cómo las características influirán en los resultados del modelo en producción.
En este caso, recomiendo extraer el conjunto de prueba “fuera de tiempo”, es decir, las observaciones más recientes son los datos de retención.
Las decisiones interpretables de los modelos de Machine Learning ya son una demanda importante para aplicarlas en el mundo real.
En muchas aplicaciones críticas de modelos de Machine Learning, la solución ha sido considerar solo algoritmos intrínsecamente interpretables, como los modelos lineales. Esos algoritmos, incapaces de capturar patrones precisos específicos del conjunto de datos de capacitación, capturarán solo las tendencias generales. Tendencias que son fácilmente interpretables e igualadas con el conocimiento y la intuición del dominio.
Las herramientas interpretables nos ofrecen una alternativa: utilizar un poderoso algoritmo, dejar que capture cualquier patrón y luego utilizar su experiencia humana para eliminar los indeseables. Entre todos los muchos modelos de Machine Learning posibles, elija el que cuente la historia correcta sobre los datos.
Cuando obtiene resultados interpretables de su modelo capacitado, puede aprovechar esta interpretabilidad. Los resultados de las herramientas descritas anteriormente pueden constituir un breve informe que una persona de negocios entiende.
Después de todo, debes explicarle a tu jefe por qué tu modelo funciona tan bien. Los modelos de Machine Learning interpretables probablemente llevarán a su jefe y a todos los interesados a tomar mejores decisiones comerciales.
Conclusión
A veces las personas dicen que solo los profesionales de Machine Learning en aplicaciones altamente reguladas deberían preocuparse por la interpretabilidad.
Creo que todo lo contrario: todos los profesionales de Machine Learning deben usar la interpretabilidad como una herramienta adicional para construir mejores modelos.
Gracias por leer. Me encantaría su opinión.