
La capa convolucional en las redes neuronales en Machine Learning aplica sistemáticamente filtros a una entrada y crea mapas de características de salida.
Aunque la capa convolucional es muy simple, es capaz de lograr resultados sofisticados e impresionantes. Sin embargo, puede resultar complicado desarrollar una intuición sobre cómo la forma de los filtros afecta la forma del mapa de características de salida y cómo se deben configurar los hiperparámetros de configuración relacionados, como el relleno (Padding) y la zancada (Stride).
En este tutorial, descubrirá una intuición sobre el tamaño del filtro, la necesidad de Padding y Stride en las Redes neuronales en Machine Learning.
Después de completar este tutorial, sabrá:
- Cómo el tamaño del filtro o el tamaño del kernel afectan la forma del mapa de características de salida.
- Cómo el tamaño del filtro crea un efecto de borde en el mapa de características y cómo se puede superar con Padding.
- Cómo se puede utilizar el paso del filtro en la imagen de entrada para reducir la resolución del tamaño del mapa de características de salida.
Comencemos.
Descripción general del tutorial
Este tutorial se tiene cinco partes:
- Redes neuronales convolucionales en Machine Learning: Capa convolucional.
- Problema de los efectos de borde (Border Effects).
- Efecto del tamaño del filtro (tamaño del kernel).
- Solucione el problema del efecto de borde con Padding.
- Reducir la muestra de entrada con Stride.
Redes neuronales en Machine Learning: Capa convolucional
En las Redes neuronales en Machine Learning, una capa convolucional es responsable de la aplicación sistemática de uno o más filtros a una entrada.
La multiplicación del filtro por la imagen de entrada da como resultado una única salida. La entrada suele ser imágenes tridimensionales (por ejemplo, filas, columnas y canales) y, a su vez, los filtros también son tridimensionales con el mismo número de canales y menos filas y columnas que la imagen de entrada.
Como tal, el filtro se aplica repetidamente a cada parte de la imagen de entrada.Da como resultado un mapa de activaciones de salida bidimensional, llamado mapa de características.
Keras proporciona una implementación de la capa convolucional llamada Conv2D.
Requiere que especifique la forma esperada de las imágenes de entrada en términos de filas (alto), columnas (ancho) y canales (profundidad) o [filas, columnas, canales] .
El filtro contiene los pesos que se deben aprender durante el entrenamiento de la capa. Los pesos del filtro representan la estructura o característica que el filtro detectará y la fuerza de la activación indica el grado en que se detectó la característica.
La capa requiere que se especifique tanto el número de filtros como la forma de los filtros. Podemos demostrarlo con un pequeño ejemplo.
En este ejemplo, definimos una única imagen de entrada o muestra que tiene un canal y es un cuadrado de ocho por ocho píxeles con todos los valores 0 y una línea vertical de dos píxeles de ancho en el centro.
# define input data data = [[0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0]] data = asarray(data) data = data.reshape(1, 8, 8, 1)
A continuación, podemos definir un modelo que espera que las muestras de entrada tengan la forma (8, 8, 1) y tenga una única capa convolucional oculta con un único filtro con la forma de tres píxeles por tres píxeles:
# create model model = Sequential() model.add(Conv2D(1, (3,3), input_shape=(8, 8, 1))) # summarize model model.summary()
El filtro se inicializa con ponderaciones aleatorias como parte de la inicialización del modelo. Sobrescribiremos los pesos aleatorios y codificaremos nuestro propio filtro 3 × 3 que detectará líneas verticales.
Ese es el filtro que se activará fuertemente cuando detecte una línea vertical y se activará débilmente cuando no lo haga. Esperamos que al aplicar este filtro en la imagen de entrada, el mapa de características de salida muestre que se detectó la línea vertical.
# define a vertical line detector detector = [[[[0]],[[1]],[[0]]], [[[0]],[[1]],[[0]]], [[[0]],[[1]],[[0]]]] weights = [asarray(detector), asarray([0.0])] # store the weights in the model model.set_weights(weights)
A continuación, podemos aplicar el filtro a nuestra imagen de entrada llamando a la función predict () en el modelo:
# apply filter to input data yhat = model.predict(data)
El resultado es una salida de cuatro dimensiones con un lote, un número determinado de filas y columnas y un filtro, o [lote, filas, columnas, filtros] .
Podemos imprimir las activaciones en el mapa de características únicas para confirmar que se detectó la línea:
# enumerate rows for r in range(yhat.shape[1]): # print each column in the row print([yhat[0,r,c,0] for c in range(yhat.shape[2])])
Al vincular todo esto, el ejemplo completo se enumera a continuación:
# example of using a single convolutional layer from numpy import asarray from keras.models import Sequential from keras.layers import Conv2D # define input data data = [[0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0]] data = asarray(data) data = data.reshape(1, 8, 8, 1) # create model model = Sequential() model.add(Conv2D(1, (3,3), input_shape=(8, 8, 1))) # summarize model model.summary() # define a vertical line detector detector = [[[[0]],[[1]],[[0]]], [[[0]],[[1]],[[0]]], [[[0]],[[1]],[[0]]]] weights = [asarray(detector), asarray([0.0])] # store the weights in the model model.set_weights(weights) # apply filter to input data yhat = model.predict(data) # enumerate rows for r in range(yhat.shape[1]): # print each column in the row print([yhat[0,r,c,0] for c in range(yhat.shape[2])])
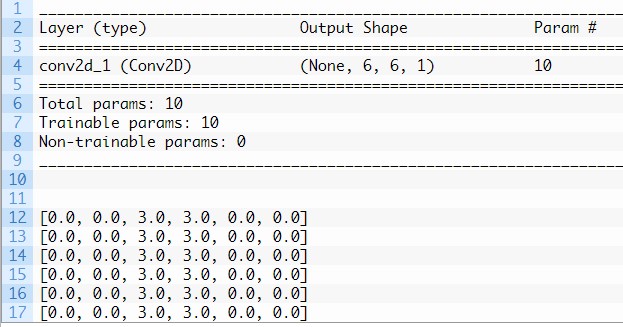
Ejecutar el ejemplo primero resume la estructura del modelo.
Es de destacar que la única capa convolucional oculta tomará el 8 × La imagen de entrada de 8 píxeles y producirá un mapa de características con las dimensiones de 6 × 6. Veremos por qué este es el caso en la siguiente sección.
También podemos ver que la capa tiene 10 parámetros, es decir, nueve pesos para el filtro (3 × 3) y un peso para el sesgo.
Finalmente, se imprime el mapa de características. Al revisar los números en la matriz de 6 × 6 podemos ver que, de hecho, el filtro especificado manualmente detectó la línea vertical en el centro de nuestra imagen de entrada:
Problema de los efectos de borde (Border Effects) en Redes neuronales en Machine Learning
En la sección anterior, definimos un solo filtro con el tamaño de tres píxeles de alto y tres píxeles de ancho (filas, columnas).
Vimos que La aplicación del filtro 3 × 3, referido como el tamaño del núcleo en Keras, a la imagen de entrada 8 × 8 dio como resultado un mapa de características con el tamaño de 6 × 6.
Es decir, la imagen de entrada con 64 píxeles fue Reducido a un mapa de características con 36 píxeles. ¿A dónde se fueron los otros 28 píxeles?
El filtro se aplica sistemáticamente a la imagen de entrada. Comienza en la esquina superior izquierda de la imagen y se mueve de izquierda a derecha columna de un píxel a la vez hasta que el borde del filtro alcanza el borde de la imagen.
Para un filtro de 3 × 3 píxeles aplicado a un 8 × 8 imagen de entrada, podemos ver que solo se puede aplicar seis veces, lo que da como resultado el ancho de seis en el mapa de características de salida.
Por ejemplo, analicemos cada uno de los seis parches de la imagen de entrada (izquierda) producto puntual (operador “.”) el filtro (derecha):
0, 0, 0 0, 1, 0 0, 0, 0 . 0, 1, 0 = 0 0, 0, 0 0, 1, 0
Movemos un píxel hacia la derecha:
0, 0, 1 0, 1, 0 0, 0, 1 . 0, 1, 0 = 0 0, 0, 1 0, 1, 0
Vamos un píxel hacia la derecha:
0, 1, 1 0, 1, 0 0, 1, 1 . 0, 1, 0 = 3 0, 1, 1 0, 1, 0
Un píxel hacia la derecha:
1, 1, 0 0, 1, 0 1, 1, 0 . 0, 1, 0 = 3 1, 1, 0 0, 1, 0
Movemos un píxel hacia la derecha:
1, 0, 0 0, 1, 0 1, 0, 0 . 0, 1, 0 = 0 1, 0, 0 0, 1, 0
Píxel hacia la derecha:
0, 0, 0 0, 1, 0 0, 0, 0 . 0, 1, 0 = 0 0, 0, 0 0, 1, 0
Eso nos da la primera fila y cada columna del mapa de características de salida:
0.0, 0.0, 3.0, 3.0, 0.0, 0.0
La reducción en el tamaño de la entrada al mapa de características se conoce como efectos de borde. Es causado por la interacción del filtro con el borde de la imagen.
Esto no suele ser un problema para imágenes grandes y filtros pequeños, pero puede serlo con imágenes pequeñas. También puede convertirse en un problema una vez que se apilan varias capas convolucionales.
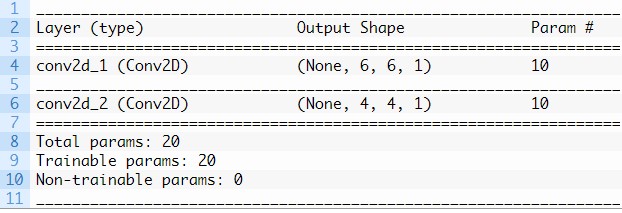
Por ejemplo, a continuación se muestra el mismo modelo actualizado para tener dos capas convolucionales apiladas.
Esto significa que se aplica un filtro de 3×3 a la imagen de entrada de 8×8 para dar como resultado un mapa de características de 6×6 como en la sección anterior.
Luego se aplica un filtro de 3×3 al mapa de características de 6×6:
# example of stacked convolutional layers from keras.models import Sequential from keras.layers import Conv2D # create model model = Sequential() model.add(Conv2D(1, (3,3), input_shape=(8, 8, 1))) model.add(Conv2D(1, (3,3))) # summarize model model.summary()
Al ejecutar el ejemplo se resume la forma de la salida de cada capa.
Podemos ver que la aplicación de filtros a la salida del mapa de características de la primera capa, a su vez, da como resultado un mapa de características más pequeño de 4×4.
Esto puede convertirse en un problema a medida que desarrollamos modelos de redes neuronales en Machine Learning muy profundos con decenas o cientos de capas. Simplemente nos quedaremos sin datos en nuestros mapas de características para operar.
Efecto del tamaño del filtro (tamaño del kernel) en Redes neuronales
Los filtros de diferentes tamaños detectarán características de diferentes tamaños en la imagen de entrada y, a su vez, darán como resultado mapas de características de diferentes tamaños.
Es común utilizar filtros de tamaño 3×3, y quizás filtros de tamaño 5×5 o incluso 7×7, para imágenes de entrada más grandes.
Por ejemplo, a continuación se muestra un ejemplo del modelo con un único filtro actualizado para utilizar un tamaño de filtro de 5×5 píxeles:
# example of a convolutional layer from keras.models import Sequential from keras.layers import Conv2D # create model model = Sequential() model.add(Conv2D(1, (5,5), input_shape=(8, 8, 1))) # summarize model model.summary()
La ejecución del ejemplo demuestra que el filtro de 5 × 5 solo se puede aplicar a la imagen de entrada de 8 × 8 4 veces, lo que da como resultado una salida de mapa de características de 4 × 4.

Puede ayudar a desarrollar aún más la intuición de la relación entre el tamaño del filtro y el mapa de características de salida observar dos casos extremos.
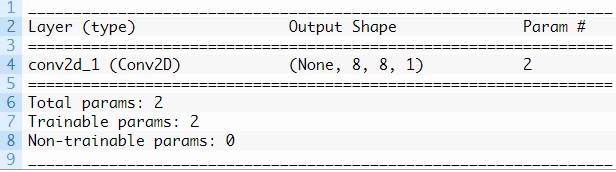
El primero es un filtro con un tamaño de 1×1 píxeles.
# example of a convolutional layer from keras.models import Sequential from keras.layers import Conv2D # create model model = Sequential() model.add(Conv2D(1, (1,1), input_shape=(8, 8, 1))) # summarize model model.summary()
La ejecución del ejemplo demuestra que el mapa de características de salida tiene el mismo tamaño que la entrada, específicamente 8 × 8. Esto se debe a que el filtro solo tiene un peso (y un sesgo).
El otro extremo es un filtro del mismo tamaño que la entrada, en este caso 8×8 píxeles:
# example of a convolutional layer from keras.models import Sequential from keras.layers import Conv2D # create model model = Sequential() model.add(Conv2D(1, (8,8), input_shape=(8, 8, 1))) # summarize model model.summary()
Al ejecutar el ejemplo, podemos ver que como era de esperar, hay un peso para cada píxel en la imagen de entrada (64 + 1 para el sesgo) y que la salida es un mapa de características con un solo píxel.

Ahora que estamos familiarizados con el efecto de los tamaños de filtro en el tamaño del mapa de características resultante, veamos cómo podemos dejar de perder píxeles.
Redes neuronales en Machine Learning: Solucione el problema del efecto de borde con Padding
De forma predeterminada, un filtro comienza a la izquierda de la imagen con el lado izquierdo del filtro ubicado en los píxeles del extremo izquierdo de la imagen. Luego, el filtro recorre la imagen una columna a la vez hasta que el lado derecho del filtro se asienta en los píxeles del extremo derecho de la imagen.
Un enfoque alternativo para aplicar un filtro a una imagen es garantizar que cada píxel de la imagen tenga la oportunidad de estar en el centro del filtro.
De forma predeterminada, este no es el caso, ya que los píxeles en el borde de la entrada solo están expuestos al borde del filtro. Al iniciar el filtro fuera del marco de la imagen les da a los píxeles en el borde de la imagen más oportunidades de interactuar con el filtro. Más oportunidades para que el filtro detecte características y, a su vez, una salida de mapa de características que tiene la misma forma que la imagen de entrada.
Por ejemplo, en el caso de aplicar un filtro de 3×3 a la imagen de entrada de 8×8. Podemos agregar un borde de un píxel alrededor del exterior de la imagen.
Esto tiene el efecto de crear artificialmente una imagen de entrada de 10×10. Cuando se aplica el filtro 3×3, se obtiene un mapa de características de 8×8.
Los valores de píxeles agregados podrían tener el valor cero que no tiene ningún efecto con la operación del producto escalar cuando se aplica el filtro.
x, x, x 0, 1, 0 x, 0, 0 . 0, 1, 0 = 0 x, 0, 0 0, 1, 0
La adición de píxeles al borde de la imagen se llama relleno o Stride.
En Keras, esto se especifica mediante el argumento “padding” en la capa Conv2D, que tiene el valor predeterminado de ‘ válido ‘ (sin relleno). Esto significa que el filtro se aplica sólo a las vías válidas de entrada.
El valor de ‘padding’ de ‘same‘ calcula y agrega el relleno requerido a la imagen de entrada (o mapa de características) para garantizar que la salida tenga la misma forma que la entrada.
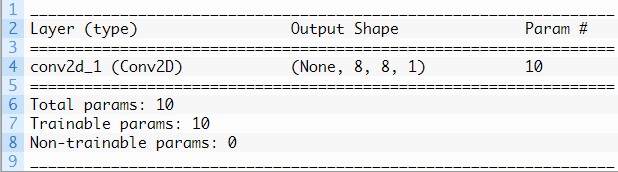
El siguiente ejemplo agrega Stride a la capa convolucional en nuestro ejemplo trabajado:
# example a convolutional layer with padding from keras.models import Sequential from keras.layers import Conv2D # create model model = Sequential() model.add(Conv2D(1, (3,3), padding='same', input_shape=(8, 8, 1))) # summarize model model.summary()
La ejecución del ejemplo demuestra que la forma del mapa de características de salida es la misma que la imagen de entrada:
Stride tuvo el efecto deseado:
La adición de Stride permite el desarrollo de modelos muy profundos de tal manera que los mapas de características no se reducen a nada.
El siguiente ejemplo demuestra esto con tres capas convolucionales apiladas:
# example a deep cnn with padding from keras.models import Sequential from keras.layers import Conv2D # create model model = Sequential() model.add(Conv2D(1, (3,3), padding='same', input_shape=(8, 8, 1))) model.add(Conv2D(1, (3,3), padding='same')) model.add(Conv2D(1, (3,3), padding='same')) # summarize model model.summary()
Al ejecutar el ejemplo, podemos ver que con la adición de relleno (Stride), la forma de los mapas de características de salida permanece fija en 8×8 incluso con tres capas de profundidad.

Reducir la muestra de entrada con Stride
El filtro se mueve a lo largo de la imagen de izquierda a derecha, de arriba a abajo, con un cambio de columna de un píxel en los movimientos horizontales y luego un cambio de fila de un píxel en los movimientos verticales.
La cantidad de movimiento entre aplicaciones del filtro a la imagen de entrada se conoce como zancada y casi siempre es simétrica en dimensiones de alto y ancho.
La zancada o zancadas predeterminadas en dos dimensiones es (1,1) para el movimiento de altura y ancho, que se realiza cuando es necesario. Y este valor predeterminado funciona bien en la mayoría de los casos.
La zancada se puede cambiar, lo que tiene un efecto tanto en cómo se aplica el filtro a la imagen como, a su vez, en el tamaño del mapa de características resultante.
Por ejemplo, la zancada se puede cambiar a (2,2). Esto tiene el efecto de mover el filtro dos píxeles hacia la derecha por cada movimiento horizontal del filtro y dos píxeles hacia abajo por cada movimiento vertical del filtro al crear el mapa de características.
Podemos demostrar esto con un ejemplo usando la imagen de 8×8 con un producto escalar de línea vertical (izquierda) (“.” operador) con el filtro de línea vertical (derecha) con un paso de dos píxeles:
0, 0, 0 0, 1, 0 0, 0, 0 . 0, 1, 0 = 0 0, 0, 0 0, 1, 0
Movido dos píxeles a la derecha:
0, 1, 1 0, 1, 0 0, 1, 1 . 0, 1, 0 = 3 0, 1, 1 0, 1, 0
Moviendo dos píxeles a la derecha:
1, 0, 0 0, 1, 0 1, 0, 0 . 0, 1, 0 = 0 1, 0, 0 0, 1, 0
Podemos ver que sólo hay tres aplicaciones válidas de los filtros 3×3 a la imagen de entrada 8×8 con un paso de dos. Esto será lo mismo en la dimensión vertical.
Esto tiene el efecto de aplicar el filtro de tal manera que la salida del mapa de características normal (6×6) se muestrea hacia abajo para que el tamaño de cada dimensión se reduzca a la mitad (3×3). Lo que da como resultado 1/4 del número de píxeles (36 píxeles hasta 9).
El paso se puede especificar en Keras en la capa Conv2D mediante el argumento ‘ paso ‘ y especificarse como una tupla con alto y ancho.
El ejemplo demuestra la aplicación de nuestro filtro de línea vertical manual en la imagen de entrada de 8 × 8 con una capa convolucional que tiene un paso de dos:
# example of vertical line filter with a stride of 2 from numpy import asarray from keras.models import Sequential from keras.layers import Conv2D # define input data data = [[0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 0, 0, 0]] data = asarray(data) data = data.reshape(1, 8, 8, 1) # create model model = Sequential() model.add(Conv2D(1, (3,3), strides=(2, 2), input_shape=(8, 8, 1))) # summarize model model.summary() # define a vertical line detector detector = [[[[0]],[[1]],[[0]]], [[[0]],[[1]],[[0]]], [[[0]],[[1]],[[0]]]] weights = [asarray(detector), asarray([0.0])] # store the weights in the model model.set_weights(weights) # apply filter to input data yhat = model.predict(data) # enumerate rows for r in range(yhat.shape[1]): # print each column in the row print([yhat[0,r,c,0] for c in range(yhat.shape[2])])
Al ejecutar el ejemplo, podemos ver en el resumen del modelo que la forma del mapa de características de salida será 3 × 3.
Al aplicar el filtro hecho a mano a la imagen de entrada e imprimir el mapa de características de activación resultante. Podemos ver que, de hecho, el filtro aún detectó la línea vertical y puede representar este hallazgo con menos información.
La reducción de resolución puede ser deseable en algunos casos en los que un conocimiento más profundo de los filtros utilizados en el modelo o de la arquitectura del modelo permite cierta compresión en los mapas de características resultantes.

Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar más.
Libros
- Capítulo 9: Redes neuronales en Machine Learning, Aprendizaje profundo 2016.
- Capítulo 5: Aprendizaje profundo para la visión por computadora, Aprendizaje profundo con Python 2017.
API
Resumen
En este tutorial, descubrió una intuición sobre el tamaño del filtro, la necesidad de Stride y el avance en las Redes neuronales en Machine Learning.
Específicamente, aprendiste:
- Cómo el tamaño del filtro o el tamaño del kernel afectan la forma del mapa de características de salida.
- Cómo el tamaño del filtro crea un efecto de borde en el mapa de características y cómo se puede superar con Stride.
- Cómo se puede utilizar el paso del filtro en la imagen de entrada para reducir la resolución del tamaño del mapa de características de salida.
¿Tiene usted alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.