Identificar bots con machine learning (Parte 2)

Los trolls y los bots están muy extendidos en las redes sociales y nos influyen de formas que no siempre conocemos. Los trolls pueden ser relativamente inofensivos, solo tratando de entretenerse a expensas de los demás, pero también pueden ser actores políticos que siembran desconfianza o discordia. Si bien algunos bots ofrecen información útil, otros se pueden usar para manipular los recuentos de votos y promover contenido que respalde su agenda. Le mostraremos cómo el aprendizaje automático puede ayudar a proteger a nuestras comunidades del abuso.
En la primera parte de esta serie cubrimos el problema de los trolls y bots en el popular sitio Reddit. Describimos cómo construimos un tablero para moderar a los trolls y bots sospechosos. En esta parte, le mostraremos cómo utilizamos el aprendizaje automático para detectar bots y trolls en discusiones políticas y luego marcar comentarios sospechosos en nuestro panel de moderador.
Antecedentes sobre la detección de trol y bot
La detección de trol y bot es un campo relativamente nuevo. Históricamente, las compañías han empleado moderadores humanos para detectar y eliminar contenido que es inconsistente con sus términos de servicio. Sin embargo, este proceso manual es costoso, además de que puede ser emocionalmente agotador para los humanos revisar el peor contenido. Llegaremos rápidamente a los límites de la eficacia del moderador humano a medida que se desaten nuevas tecnologías como la generación de lenguaje natural OpenAI GPT-2 . A medida que los bots mejoran, es importante emplear tecnologías de contador para proteger la integridad de las comunidades en línea.
Se han realizado varios estudios sobre el tema de la detección de bots. Por ejemplo, un investigador encontró que los bots competidores pro-Trump y anti-Trump en Twitter . Los investigadores de la Universidad de Indiana han proporcionado una herramienta para verificar a los usuarios de Twitter llamada botornot .
También ha habido investigaciones interesantes sobre trolls en línea. La investigación de Stanford ha demostrado que solo el 1% de las cuentas crean el 74% de los conflictos . Los investigadores de Georgia Tech utilizaron un modelo de procesamiento de lenguaje natural para identificar a los usuarios que violan las normas con conductas como ataques personales, insultos misóginos o incluso explicaciones
Detección de comentarios para moderación
Nuestro objetivo es cree un modelo de aprendizaje automático para filtrar comentarios sobre el subreddit político para que los moderadores lo revisen. No es necesario que tenga una precisión perfecta, ya que los comentarios serán revisados por un moderador humano. En cambio, nuestra medida de éxito es cuánto más eficientes podemos hacer moderadores humanos. En lugar de tener que revisar cada comentario, podrán revisar un subconjunto preseleccionado. No estamos tratando de reemplazar el sistema de moderación existente que proporciona Reddit, que permite a los moderadores revisar los comentarios que han informado los usuarios. En cambio, esta es una fuente adicional de información que puede complementar el sistema existente.
Como se describe en nuestro artículo de la primera parte, hemos creado un tablero que permite a los moderadores revisar los comentarios. El modelo de aprendizaje automático calificará cada comentario como un usuario normal, un bot o un troll.
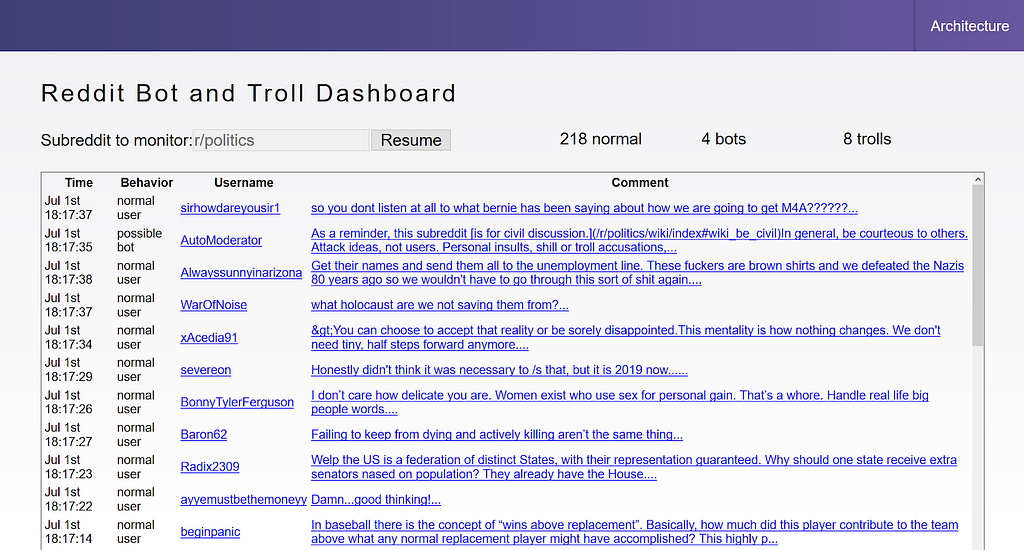
Pruébelo usted mismo en reddit-dashboard.herokuapp.com .
Para configurar su expectativas, nuestro sistema está diseñado como una prueba de concepto. No está destinado a ser un sistema de producción y no es 100% preciso. Lo usaremos para ilustrar los pasos involucrados en la construcción de un sistema, con la esperanza de que los proveedores de la plataforma puedan ofrecer herramientas oficiales como estas en el futuro.
Recopilación de datos de capacitación
Nuestro conjunto de datos de capacitación inicial se obtuvo de Una lista de bots y trolls conocidos. Utilizaremos dos listas de estos 393 bots conocidos más 167 más del subreddit de botwatch. También utilizaremos una lista de 944 cuentas troll del Informe de Transparencia 2017 de Reddit que se sospechaba que trabajaban para la Agencia Rusa de Investigación de Internet.
Estamos utilizando una arquitectura basada en eventos que consiste en un proceso que descarga datos de Reddit y los empuja a una cola Kafka. Luego tenemos un consumidor de Kafka que escribe los datos en un almacén de datos Redshift en lotes. Escribimos una solicitud de productor de Kafka para descargar los comentarios de la lista de bots y trolls. Como resultado, nuestro almacén de datos contiene no solo los datos de los bots y trolls conocidos, sino también comentarios en tiempo real del subreddit político.
Si bien los comentarios de Reddit no son exactamente privados, es posible que tenga datos privados. Por ejemplo, puede tener datos que están regulados por HIPAA o PCI, o que son sensibles a su negocio o clientes. Seguimos una arquitectura de referencia Heroku que fue diseñada para proteger datos privados. Proporciona un script Terraform para configurar automáticamente un almacén de datos Redshift y conectarlo a un espacio privado Heroku. Como resultado, solo las aplicaciones que se ejecutan en el espacio privado pueden acceder a los datos.
Podemos entrenar nuestro modelo en un banco de pruebas directamente o ejecutar un banco de pruebas único para descargar los datos a CSV y entrenar el modelo localmente. Elegiremos este último por simplicidad, pero querrá mantener datos confidenciales en el espacio privado.
heroku run bash -a kafka-stream-viz-jorge export PGPASSWORD = echo “select * de reddit_comments "| psql -h tf-jorge-tf-redshift-cluster.coguuscncu3p.us-east-1.redshift.amazonaws.com -U jorge -d redshift_jorge -p 5439 -A -o reddit.csv gzip reddit.csv curl -F "file=@reddit.csv.gz" https://file.io
Si prefiere utilizar nuestros datos de entrenamiento para probarlo usted mismo, puede descargar nuestro CSV .
Ahora tenemos comentarios de ambos grupos de usuarios y contamos un total de 93,668. Las relaciones entre las clases se fijan en 5% de trolls, 10% de bots y 85% de lo normal. Esto es útil para la capacitación, pero probablemente subestima el porcentaje real de usuarios normales.

Selección de funciones
A continuación, debemos seleccionar las funciones para construir nuestro modelo. Reddit proporciona docenas de campos JSON para cada usuario y comentario. Algunos no tienen valores significativos. Por ejemplo, banned_by fue nulo en todos los casos, probablemente porque carecemos de permisos de moderador. Elegimos los campos a continuación porque pensamos que serían valiosos como predictores o para comprender qué tan bien funciona nuestro modelo. Agregamos la columna Recent_comments con una matriz de los últimos 20 comentarios realizados por ese usuario.
no_follow link_id dorado author author_verified author_comment_karma author_link_karma _ num_ created_utc score over_18 body is_submitter controversial ups is_bot is_troll Recent_comments
Algunos campos son como ” útil para comentarios históricos, pero no para un panel de control en tiempo real porque los usuarios aún no han tenido tiempo de votar ese comentario.
Agregamos campos calculados adicionales que pensamos que se correlacionarían bien con bots y trolls. Por ejemplo, sospechamos que el historial de comentarios recientes de un usuario proporcionaría información valiosa sobre si es un bot o un troll. Por ejemplo, si un usuario publica repetidamente comentarios controvertidos con un sentimiento negativo, tal vez sean un troll. Del mismo modo, si un usuario publica comentarios repetidamente con el mismo texto, tal vez sea un bot. Utilizamos el paquete TextBlob para calcular valores numéricos para cada uno de estos. La fecha de uso.
Recent_avg_ups
Recent_avg_diff_ratio
Recent_max_diff_ratio
Recent_avg_sentiment_polarity
Recent_min_sentiment_polarity
Para obtener más información sobre lo que estos campos son y cómo se calculan en su computadora portátil, su código de pantalla es: /github.com/devspotlight/botidentification[19459007font>[19659004font>Creandounmodelodeaprendizajeautomático
Nuestro siguiente paso es crear un nuevo modelo de aprendizaje automático basado en esta lista. Utilizaremos el excelente marco scikit learn de Python para construir nuestro modelo. Almacenaremos nuestros datos de entrenamiento en dos marcos de datos: uno para el conjunto de características para entrenar y el segundo con las etiquetas de clase deseadas. Luego dividiremos nuestro conjunto de datos en 70% de datos de entrenamiento y 30% de datos de prueba.
X_train, X_test, y_train, y_test = train_test_split ( input_x, input_y, test_size = 0.3, random_state = 16) [19659025] A continuación, crearemos un clasificador de árbol de decisión para predecir si cada comentario es un bot, un troll o un usuario normal. Utilizaremos un árbol de decisión porque la regla creada es muy fácil de entender. La precisión probablemente se mejoraría usando un algoritmo más robusto como un bosque aleatorio, pero nos mantendremos en un árbol de decisión con el fin de mantener nuestro ejemplo simple.
clf = DecisionTreeClassifier (max_depth = 3,
class_weight = {'normal': 1, 'bot': 2.5, 'troll': 5},
min_samples_leaf = 100)
Notará algunos parámetros en el ejemplo de código anterior. Estamos configurando la profundidad máxima del árbol en 3 no solo para evitar el sobreajuste, sino también para que sea más fácil visualizar el árbol resultante. También estamos estableciendo los pesos de la clase para que sea menos probable que se pierdan los bots y trolls, incluso a expensas de etiquetar falsamente a un usuario normal. Por último, estamos requiriendo que los nodos de hoja tengan al menos 100 muestras para mantener nuestro árbol más simple.
Ahora probaremos el modelo contra el 30% de los datos que presentamos como un conjunto de prueba. Esto nos dirá qué tan bien funciona nuestro modelo al adivinar si cada comentario es de un bot, un troll o un usuario normal.
matrix = pd.crosstab (y_true, y_pred, rownames = [‘True’]colnames = [‘Predicted’]márgenes = Verdadero)
Esto creará una matriz de confusión que muestra, para cada etiqueta objetivo verdadera, cuántos de los comentarios se predijeron correcta o incorrectamente. Por ejemplo, podemos ver a continuación que de un total de 1,956 comentarios de troll, predijimos correctamente 1,451 de ellos.
Predicción del bot normal troll Todos Verdadero bot 3677 585 33 4295 normal 197 20593 993 21783 troll 5 500 1451 1956 Todos 3879 21678 2477 28034
En otras palabras, el retiro para trolls es del 74%. La precisión es menor; de todos los comentarios pronosticados como troll, solo el 58% realmente lo son.
Recordemos: [0.85611176 0.94537024 0.74182004] Precisión: [0.94792472 0.94994926 0.58578926] Precisión: 0.917493044160662
Podemos calcular la precisión general en 91.7%. El modelo funcionó mejor para usuarios normales, con aproximadamente un 95% de precisión y recuperación. Se desempeñó bastante bien para los bots, pero tuvo más dificultades para distinguir a los trolls de los usuarios normales. En general, los resultados parecen bastante sólidos incluso con un modelo bastante simple.
¿Qué nos dice el modelo?
Ahora que tenemos este gran modelo de aprendizaje automático que puede predecir bots y trolls, cómo funciona y qué puede hacer. aprendemos de eso? Un buen comienzo es ver qué características fueron más importantes.
feature_imp = pd.Series (
clf.feature_importances _,
index = my_data.columns.drop ('target')). Sort_values (ascending = False)
recent_avg_diff_ratio 0,465169 author_comment_karma 0,329354 author_link_karma 0,099974 recent_avg_responses 0,098622 author_verified recent_min_sentiment_polarity 0,000000 recent_avg_no_follow 0,000000 0.006882 over_18 0,000000 is_submitter 0,000000 recent_num_comments 0,000000 recent_num_last_30_days 0,000000 recent_avg_gilded 0,000000 recent_avg_sentiment_polarity 0,000000 recent_percent_neg_score 0,000000 recent_avg_score 0,000000 recent_min_score 0,000000 recent_avg_controversiality 0,000000 recent_avg_ups 0,000000 recent_max_diff_ratio 0,000000 no_follow 0.000000
¡Interesante! La característica más importante fue la razón de diferencia promedio en el texto de los comentarios recientes. Esto significa que si el texto de los últimos 20 comentarios es muy similar, probablemente sea un bot. Las siguientes características más importantes fueron el karma de comentarios, el karma de enlaces, el número de respuestas a los comentarios recientes y si la cuenta está verificada.
¿Por qué el resto es cero? Limitamos la profundidad de nuestro árbol binario a 3 niveles, por lo que intencionalmente no incluimos todas las características. Cabe destacar que no consideramos los puntajes o el sentimiento de los comentarios anteriores para clasificar a los trolls. O estos trolls fueron bastante educados y obtuvieron un número decente de votos, o las otras características tuvieron un mejor poder discriminatorio.
Echemos un vistazo al árbol de decisión real para obtener más información.
export_graphviz (estimator, out_file = ' tree.dot ', feature_names = data.drop ([‘target’]axis = 1) .columns.values, class_names = np.array ([‘normal’,’bot’,’troll’]), redondeado = Falso, proporción = Falso, precisión = 5, lleno = Verdadero)

¡Ahora podemos tener una idea de cómo funciona este modelo! Es posible que deba hacer un acercamiento para ver los detalles.
Comencemos por la parte superior del árbol. Cuando los comentarios recientes son bastante similares entre sí (la relación de diferencia promedio es alta), entonces es más probable que sea un bot. Cuando tienen comentarios diferentes, poco karma de comentarios y alto karma de enlace, es más probable que sean un troll. Esto podría tener sentido si los trolls usan publicaciones de gatitos para aumentar su karma de enlaces, y luego hacen comentarios desagradables en los foros que son ignorados o rechazados.
Alojando una API
Para que nuestro modelo de aprendizaje automático esté disponible para En el mundo, debemos ponerlo a disposición de nuestro panel de moderador. Podemos hacerlo alojando una API para que llame el tablero.
Para servir nuestra API, utilizamos Flask que es un marco web ligero para Python. Cuando cargamos nuestro modelo de aprendizaje automático, se inicia el servidor. Cuando recibe una solicitud POST que contiene un objeto JSON con los datos del comentario, responde con la predicción.
Ejemplo para un usuario bot :
{
"prohibido": nulo,
"no_follow": verdadero,
"link_id": "t3_aqtwe1",
"dorado": falso,
"autor": "AutoModerator",
"autor_verificado": falso,
“author_comment_karma”: 445850.0,
“author_link_karma”: 1778.0,
“num_comments”: 1.0,
“created_utc”: 1550213389.0,
“score”: 1.0,
“over_18 : falso,
"cuerpo": "¡Hola, gracias por publicar en / r / SwitchHaxing! Lamentablemente, su comentario se ha eliminado debido a la regla 6; publique preguntas en el hilo de preguntas y respuestas fijo. Si usted cree que esto es un error, comuníquese con nosotros a través de Modmail y resuélvalo. * Soy un bot ”,
“ down ”: 0.0,
“ is_submitter ”: false,
“ num_reports ”: nul l,
"controversia": 0.0,
"cuarentena": "falso",
"ups": 1.0,
"is_bot": verdadero,
"is_troll": falso,
"Recent_comments": "[…array of 20 recent comments…]"
}
La respuesta devuelta es:
{
"predicción": "Es un usuario bot"
}
Implementamos nuestro API en Heroku porque hace que sea muy fácil de ejecutar. Simplemente creamos un Procfile con una sola línea que le dice a Heroku qué archivo usar para el servidor web.
web: python app.py $ {port}
Entonces podemos enviar nuestro código a heroku:
git push heroku master
Heroku se encarga de la molestia de descargar requisitos, crear la API, configurar un servidor web, enrutamiento, etc. Ahora podemos acceder a nuestra API en esta URL y usar Cartero para enviar una solicitud de prueba:
https://botidentification.herokuapp.com/
Verlo funcionando
Gracias al gran panel de moderador que escribimos en primera parte de esta serie ahora podemos ver el rendimiento de nuestro modelo operando en comentarios reales. Si aún no lo ha hecho, échele un vistazo aquí: reddit-dashboard.herokuapp.com .

Panel de control en reddit-dashboard.herokuapp.com
Está transmitiendo comentarios reales en vivo desde el subreddit r / politica. Puede ver cada comentario y si el modelo lo calificó como bot, troll o usuario normal.
Puede ver algunos comentarios etiquetados como bots o trolls, pero no es obvio por qué después de inspeccionar su historial de comentarios. Tenga en cuenta que utilizamos un modelo simple para que nuestro tutorial sea más fácil de seguir. La precisión para etiquetar trolls es solo del 58%. Es por eso que lo diseñamos como un filtro para que lo revisen los moderadores humanos.
Si está interesado en jugar con este modelo usted mismo, consulte el código en GitHub en https://github.com/devspotlight/botidentification . Puede intentar mejorar la precisión del modelo utilizando un algoritmo más sofisticado, como un bosque aleatorio. Alerta de spoiler: es posible obtener más del 95% de precisión en los datos de prueba con modelos más sofisticados, pero lo dejaremos como un ejercicio para usted.
Identificación de trolls y bots en Reddit con aprendizaje automático (Parte 2) se publicó originalmente en Towards Data Science en Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.





