Los mejores dataset Machine Learning
¿Cuáles son los mejores dataset Machine Learning?
Después de rastrear la web horas tras horas, hemos creado una excelente hoja de trucos para la alta calidad y diversos dataset machine learning.
Primero veamos un par de consejos a tener en cuenta al momento de buscar datasets:
- Un dataset de alta calidad no debe ser desordenado, ya que no desea perder mucho tiempo limpiando datos.
- Un dataset machine learning de alta calidad no debe tener demasiadas filas o columnas, para que sea fácil de trabajar.
- Primeramente, el limpiador de los datos, el mejor: ya que limpiar un dataset de gran tamaño puede ser increíblemente lento.
- Ciertamente debe haber una pregunta / decisión interesante de responder, que a su vez se puede responder con datos.
Buscadores de Dataset Machine Learning
Google Dataset Search: Similar a cómo funciona Google Scholar, la búsqueda de conjuntos de datos le permite encontrar conjuntos de datos dondequiera que estén alojados, ya sea el sitio de un editor, una biblioteca digital o la página web de un autor.
Por lo tanto es un buscador de conjuntos de datos fenomenal y contiene más de 25 millones de conjuntos de datos.
Kaggle: El sitio de ciencia de datos que contiene una variedad de conjuntos de datos interesantes contribuidos externamente.
 Por lo tanto aquí puede encontrar todo tipo de conjuntos de datos de nicho en su lista maestra desde clasificaciones de ramen a datos de baloncesto a e incluso licencias de mascotas .
Por lo tanto aquí puede encontrar todo tipo de conjuntos de datos de nicho en su lista maestra desde clasificaciones de ramen a datos de baloncesto a e incluso licencias de mascotas .
UCI Machine Learning Repository: Una de las fuentes más antiguas de conjuntos de datos en la web, y una excelente primera parada al buscar conjuntos de datos interesantes.
Aunque los conjuntos de datos son aportados por el usuario y, por lo tanto, tienen diferentes niveles de limpieza, la gran mayoría están limpios. También puede descargar datos directamente desde el repositorio de Aprendizaje automático de la UCI, sin registro.
VisualData: Descubra conjuntos de datos de visión artificial por categoría, permite consultas de búsqueda.
CMU Libraries: Puede obtener conjuntos de datos de alta calidad gracias a la colección de Huajin Wang, CMU.
Dataset Machine Learning: Datasets Generales
Datasets del Gobierno Público
Data.gov : Desde este sitio se permite descargar datos de varias agencias gubernamentales de los EE. UU.
Por lo tanto los datos pueden variar desde presupuestos gubernamentales hasta puntajes de desempeño escolar. Sin embargo, tenga cuidado: gran parte de los datos requieren investigación adicional.
Atlas del ambiente alimentario: Puede obtener datos sobre cómo las elecciones locales de alimentos afectan la dieta en los EE. UU.
Finanzas del sistema escolar: Posee una encuesta de las finanzas de los sistemas escolares en los Estados Unidos.
Datos de enfermedades crónicas: Contiene datos sobre indicadores de enfermedades crónicas en áreas de los Estados Unidos.
El Centro Nacional de Estadísticas de Educación de EE. UU.: Contiene datos sobre instituciones educativas y datos demográficos de educación de los EEUU y también de todo el mundo.
El Servicio de Datos del Reino Unido: Contiene la mayor recopilación de datos sociales, económicos y de población.
Datos de EE. UU.: Contiene una visualización completa de los datos públicos de los EE. UU.
Datasets de Finanzas y Economía
Quandl: Una buena fuente de recursos económicos y financieros: Contiene datos útiles para construir modelos que permitan predecir indicadores económicos o precios de acciones.
Datos abiertos del Banco Mundial: Posee un conjuntos de datos que abarcan datos demográficos de la población y una gran cantidad de indicadores económicos y de desarrollo de todo el mundo.
Datos del FMI: Contiene datos que publica el Fondo Monetario Internacional sobre finanzas internacionales, tasas de deuda, reservas de divisas, precios de productos básicos e inversiones.
Financial Times Datos de mercado: Contiene información actualizada sobre mercados financieros de todo el mundo y también están incluidos índices de precios de acciones, materias primas y divisas.
Google Trends:Examinar y analizar datos en Internet
American Economic Association (AEA): Es una buena fuente para encontrar datos macro económicos de los EE. UU.
Dataset Machine Learning de Computer Vision
xView: xView es uno de los dataset machine learning de imágenes aéreas más masivos disponibles públicamente. Por lo tanto contiene imágenes de escenas complejas de todo el mundo, anotadas mediante cuadros delimitadores.
ImageNet: Posee el dataset machine learning de imágenes más grande para visión artificial. Por lo tanto proporciona una base de datos de imágenes accesible que está organizada jerárquicamente, según WordNet.
Kinetics-700: Contiene un dataset machine learning a gran escala de URL de video de Youtube. Incluyendo acciones centradas en el ser humano, por lo tanto contiene más de 700.000 vídeos.
Google’s Open Images: Corresponde a un vasto dataset machine learning de Google AI que contiene más de 10 millones de imágenes.
Cityscapes Dataset: Contiene un conjunto de datos de código abierto para proyectos de visión artificial que contiene anotaciones de alta calidad a nivel de píxeles de secuencias de video tomadas en 50 calles de ciudades diferentes. Por lo tanto el conjunto de datos es útil en la segmentación semántica y el entrenamiento de redes neuronales profundas para comprender la escena urbana.
IMDB-Wiki dataset: El dataset machine learning de IMDB-Wiki es uno de los conjuntos de datos de código abierto más extensos para imágenes de rostros con género y edad etiquetados. Entonces las imágenes se recopilan de IMDB y Wikipedia y tiene más de cinco millones de imágenes etiquetadas.
Color Detection Dataset: El dataset machine learning contiene un archivo CSV que tiene 865 nombres de colores con sus correspondientes valores RGB (rojo, verde y azul) del color, como así también el valor hexadecimal del color.
Stanford Dogs Dataset: Contiene 20,580 imágenes y 120 categorías de razas de perros diferentes.
Dataset Machine Learning de Análisis de Sentimiento
Dataset machine learning de análisis de sentimiento de multidominio : Un conjunto de datos un poco más antiguo que presenta reseñas de productos de Amazon.
IMDB reviews : Contiene un conjunto de datos más pequeño y relativamente pequeño para la clasificación de sentimientos binarios incluye 25,000 críticas de películas.
Stanford Sentiment Treebank: Conjunto de datos de sentimiento estándar con anotaciones de sentimiento.
Sentimiento140 : Dataset machine learning popular, que utiliza 160,000 tweets con emoticones previamente eliminados.
Twitter US Airline Sentiment: Posee datos de Twitter de las aerolíneas estadounidenses desde febrero de 2015, clasificados como tweets positivos, negativos y neutrales.
Dataset Machine Learning de Procesamiento del Lenguaje Natural (NPL)
HotspotQA : Contiene pregunta que responde al dataset con naturaIidad, preguntas de múltiples saltos, con una fuerte supervisión de los datos de apoyo para permitir sistemas de respuesta a preguntas más explicables.
Enron: Posee datos de correo electrónico de la alta gerencia de Enron, organizados en carpetas.
Amazon Reviews : Contiene alrededor de 35 millones de revisiones de Amazon que abarcan 18 años, por ese motivo los datos incluyen información del producto y del usuario, calificaciones y la revisión de texto simple.
Rotten Tomatoes Reviews: Archivo de más de 480,000 críticas de críticos (fresh or rotten).
Google Books Ngrams : Contiene una colección de palabras de los libros de Google.
Blogger Corpus: Contiene una colección de 681,288 publicaciones de blog recopiladas de blogger.com, entonces cada blog contiene un mínimo de 200 apariciones de palabras en inglés de uso común.
Datos de enlaces de Wikipedia : Contiene el texto completo de Wikipedia, asimismo este dataset contiene casi 1.9 mil millones de palabras de más de 4 millones de artículos como también puede buscar por palabra, frase o parte de un párrafo.
Lista de libros electrónicos de Gutenberg : Contiene una lista anotada de libros electrónicos del Proyecto Gutenberg.
Hansards text chunks del parlamento canadiense : 1.3 millones de pares de textos de los registros del 36.o parlamento canadiense.
Jeopardy : Posee un archivo de más de 200,000 preguntas del concurso. Jeopardy.
SMS Spam Collection en inglés : Contiene un dataset que consta de 5,574 mensajes SMS de spam en inglés.
Yelp Reviews : Contiene un conjunto de datos abierto publicado por Yelp, contiene más que 5 millones de revisiones.
Spambase de UCI : Corresponde a un gran conjunto de datos de correo electrónico no deseado, útil para el filtrado de correo no deseado.
Datasets de Auto-Conducción (Conducción Autónoma o self driving)
Berkeley DeepDrive BDD100k: El dataset machine learning más grande para la IA autodirigida que contiene más de 100,000 videos de más de 1,100 horas de conducción en diferentes momentos del día y condiciones climáticas. Por lo tanto contiene imágenes anotadas que provienen de las áreas de Nueva York y San Francisco.
Baidu Apolloscapes: Posee un gran conjunto de datos que define 26 elementos semánticos diferentes, tales como autos, bicicletas, peatones, edificios, farolas, etc.
Comma.ai: Posee más de 7 horas de conducción en carretera, incluye la velocidad del automóvil, la aceleración, el ángulo de la dirección y las coordenadas del GPS.
Coche robótico de Oxford: Más de 100 repeticiones de la misma ruta a través de Oxford, Reino Unido, capturadas durante un año. Por lo tanto el conjunto de datos captura diferentes combinaciones de clima, tráfico y peatones, junto con cambios a largo plazo como construcción y obras viales.
Conjunto de datos de paisaje urbano: Posee un gran conjunto de datos que registra escenas de calles urbanas en 50 diferentes
CSSAD Dataset: Este conjunto de datos es útil para la percepción y navegación de vehículos autónomos.
KUL Belgium Traffic Sign Dataset: Posee más de 10000 anotaciones de señales de tráfico de miles de señales de tráfico físicamente distintas en la región de Flanders en Bélgica.
MIT AGE Lab: Contiene una muestra de las más de 1,000 horas de conjuntos de datos de sensores múltiples recolectados en AgeLab.
LISA: Laboratory for Intelligent & Safe Automobiles, UC San Diego Datasets: Este dataset machine learning incluye señales de tráfico, detección de vehículos, semáforos y patrones de trayectoria.
Bosch Small Traffic Light Dataset: Dataset de pequeños semáforos para Aprendizaje profundo.
LaRa Traffic Light Recognition : Dataset de semáforos, se toman datos de París.
Conjuntos de datos WPI: Dataset machine learning de semáforos, detección de peatones y carriles.
Datasets Clínicos
Conjunto de datos de COVID-19: Correspondiente al Instituto Allen de investigación de IA, que ha publicado un vasto dataset de investigación de más de 45 000 artículos académicos sobre COVID-19.
MIMIC-III: Contiene dataset machine learning disponible de forma abierta desarrollado por el laboratorio de MIT para fisiología computacional, que incluye datos de salud no identificados asociados con ~ 40,000 pacientes de cuidados críticos. También incluye datos demográficos, signos vitales, pruebas de laboratorio, medicamentos y más.
Datasets de Sistemas de Recomendación
MovieLens: Contiene dataset machine learning de calificación del sitio web de MovieLens.
Jester: Contiene 4,1 Millones de valoraciones continuas (-10,00 a +10,00) de 100 chistes de 73.421 usuarios y se utiliza principalmente para el filtro colaborativo.
Million Song Dataset: Se puede utilizar tanto para filtrado colaborativo como basado en contenido.
Nota
Si conoce otros conjuntos de datos públicos de alta calidad para recomendar a las personas para la investigación y la aplicación del aprendizaje automático, o bien para aprendizaje y ciencia de datos, etc. Entonces siéntase libre de sugerirlos junto con las razones y por qué deberían incluirse en los comentarios a continuación.
Las analizaremos e incluiremos en esta lista, además también háganos saber su experiencia con el uso de cualquiera de estos conjuntos de datos en la sección de comentarios.
¡Feliz Aprendizaje automático !
Fuentes:
[1] https://cloud.google.com/public-datasets/
[2] https: //guides.library.cmu .edu / c.php? g = 844845 & p = 6191907
[4] https://github.com/takeitallsource/awesome-autonomous-vehicles# conjuntos de datos
[5] https://medium.com/startup-grind/fueling-the-ai-gold-rush-7ae438505bc2
[6] www.dataquest.io/blog/free-datasets-for-projects/
[7] https://gengo.ai/datasets/the-best-25-datasets-for- natural-language-processing /
[8] https://github.com/awesomedata/awesome-public-datasets#machinelearning
[10] https://www.cmu.edu/ira/CDS/index.html
[11] Conjuntos de datos y sugerencias de proyectos | Andrew W. Moore | http://www.cs.cmu.edu/~awm/15781/project/data.html
[12] Conjuntos de datos | Repositorio de aprendizaje automático | MIT | https://ocw.mit.edu/courses/sloan-school-of-management/15-097-prediction-machine-learning-and-statistics-spring-2012/datasets/
[13] Conjuntos de datos | MIT Lincoln Laboratory | https://www.ll.mit.edu/r-d/datasets
[14] Stanford Large Network Dataset Collection | Universidad de Stanford | https://snap.stanford.edu/data/
[15] Stanford Common Dataset | Universidad de Stanford | https://snap.stanford.edu/data/
[16] Datalab | UC Berkeley | http://www.lib.berkeley.edu/libraries/data-lab
[17] Explorando conjuntos de datos | Ciencia de datos en Berkeley | https://datascience.berkeley.edu/open-data-sets/
[18] DeepDrive | UC Berkeley | https://bdd-data.berkeley.edu/

Gráfico de conocimiento en machine learning
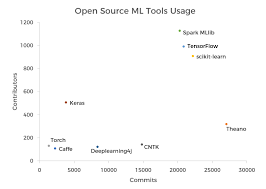
Aprendizaje automático de código abierto: TensorFlow, Theano, Torch, scikit-learn, Caffe
