
Las métricas de regresión en aprendizaje automático ml y cada modelo de Machine Learning que la utiliza intenta resolver un problema con un objetivo diferente utilizando un conjunto de datos diferente y, por lo tanto, es importante comprender el contexto antes de elegir una métrica.
Generalmente, las respuestas a la siguiente pregunta nos ayudan a elegir la métrica apropiada:
- Tipo de tarea: ¿Regresión? ¿Clasificación?
- ¿Objetivo de negocio?
- ¿Cuál es la distribución de la variable objetivo?
Bueno, en este post, discutiré la utilidad de cada métrica de error según el objetivo y el problema que intentemos resolver. Esta parte se enfoca solo en métricas de evaluación de regresión.
Métricas de regresión en aprendizaje automático ml:
- (MSE) – Error cuadrático medio
- (RMSE) -Error cuadrático medio
- (MAE) -Error absoluto medio
- (R²) – R al cuadrado
- R cuadrado ajustado (R²)
- (MSPE) – Error de porcentaje cuadrático medio
- (MAPE) – Error porcentual absoluto medio
- (RMSLE) – Error logarítmico cuadrático medio
Aprendizaje automático ml: Error cuadrático medio (MSE)
Es quizás la métrica más simple y común para la evaluación de regresión, pero también es probablemente la menos útil. Se define por la ecuación.
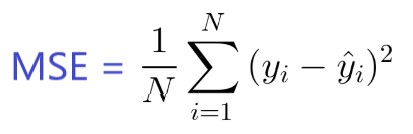
Donde yᵢ es el resultado real esperado y ŷᵢ es la predicción del modelo.
MSE básicamente mide el error cuadrado promedio de nuestras predicciones. Para cada punto, calcula la diferencia cuadrada entre las predicciones y el objetivo y luego promedia esos valores.
Cuanto mayor sea este valor, peor es el modelo. Nunca es negativo, ya que estamos cuadrando los errores de predicción individuales antes de sumarlos, pero sería cero para un modelo perfecto.
Ventaja:
Útil si tenemos valores inesperados que nos deberían interesar. Muy alto o bajo valor que debemos prestar atención.
Desventaja:
Si hacemos una predicción muy mala, la cuadratura empeorará aún más el error y puede sesgar la métrica para sobreestimar la maldad del modelo. Este es un comportamiento particularmente problemático si tenemos datos ruidosos (es decir, los datos que por cualquier motivo no son del todo confiables).
Incluso un modelo “perfecto” puede tener un MSE alto en esa situación. Por lo que es difícil juzgar qué tan bien modelo está realizando.
Por otro lado, si todos los errores son pequeños, o más bien, más pequeños que 1, se siente el efecto contrario: podemos subestimar la maldad del modelo.
Tenga en cuenta que si queremos tener una predicción constante, la mejor será el valor medio de los valores objetivo. Se puede encontrar estableciendo la derivada de nuestro error total con respecto a esa constante a cero, y descúbrela a partir de esta ecuación.
Aprendizaje automático ml: Error cuadrático medio (RMSE)
RMSE es solo la raíz cuadrada de MSE. La raíz cuadrada se introduce para hacer que la escala de los errores sea igual a la escala de los objetivos.
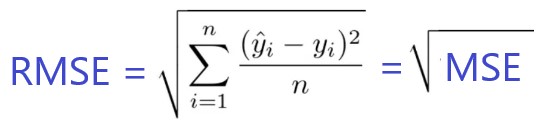
Ahora, es muy importante entender en qué sentido RMSE es similar a MSE y cuál es la diferencia.
Primero, son similares en términos de sus minimizadores, cada minimizador de MSE es también un minimizador para RMSE y viceversa, ya que la raíz cuadrada es una función que no disminuye.
Por ejemplo, si tenemos dos conjuntos de predicciones, A y B, y decimos que el MSE de A es mayor que el MSE de B, entonces podemos estar seguros de que RMSE de A es mayor que RMSE de B. Y también funciona en la dirección opuesta .
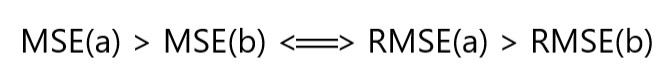
¿Qué significa para nosotros?
Significa que, si la métrica objetivo es RMSE, aún podemos comparar nuestros modelos utilizando MSE, ya que MSE ordenará los modelos de la misma manera que RMSE. Así podemos optimizar MSE en lugar de RMSE.
De hecho, es más fácil trabajar con MSE, por lo que todos usan MSE en lugar de RMSE. También un poco de diferencia entre los dos para los modelos basados en gradientes.
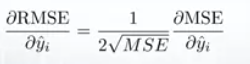
Significa que viajar a lo largo del gradiente MSE es equivalente a viajar a lo largo del gradiente RMSE, pero con una tasa de flujo diferente y la tasa de flujo depende de la puntuación de MSE en sí.
Entonces, aunque RMSE y MSE son realmente similares en términos de puntuación de modelos, pueden no ser intercambiables de forma inmediata para los métodos basados en gradientes. Probablemente tengamos que ajustar algunos parámetros como la tasa de aprendizaje.
Aprendizaje automático ml: Error absoluto medio (MAE)
En MAE, el error se calcula como un promedio de diferencias absolutas entre los valores objetivo y las predicciones. El MAE es una puntuación lineal, lo que significa que todas las diferencias individuales se ponderan por igual en el promedio. Por ejemplo, la diferencia entre 10 y 0 será el doble de la diferencia entre 5 y 0. Sin embargo, lo mismo no es cierto para RMSE. Matemáticamente, se calcula utilizando esta fórmula:
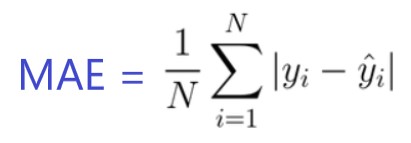
Lo importante de esta métrica es que penaliza errores enormes que no tan mal como lo hace MSE. Por lo tanto, no es tan sensible a los valores atípicos como el error cuadrático medio.
El MAE se usa ampliamente en finanzas, donde el error de $ 10 suele ser exactamente dos veces peor que el error de $ 5. Por otro lado, la métrica de MSE piensa que el error de $ 10 es cuatro veces peor que el error de $ 5. MAE es más fácil de justificar que RMSE.
Otra cosa importante acerca de MAE es sus gradientes con respecto a las predicciones. El gradiend es una función de pasos y toma -1 cuando Y_hat es más pequeño que el objetivo y +1 cuando es más grande.
Ahora, el gradiente no se define cuando la predicción es perfecta, porque cuando Y_hat es igual a Y, no podemos evaluar el gradiente. No está definido.
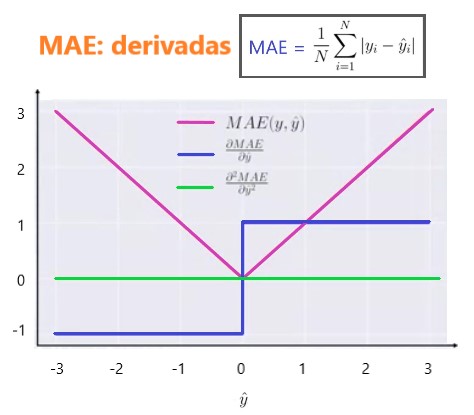
Entonces, formalmente, el MAE no es diferenciable, pero de hecho, con qué frecuencia sus predicciones miden perfectamente el objetivo.
Incluso si lo hacen, podemos escribir una condición de IF simple y un cero de retorno cuando sea el caso y, de lo contrario, a través del gradiente. También sepa que la segunda derivada es cero en todas partes y no está definida en el punto cero.
Tenga en cuenta que si queremos tener una predicción constante, la mejor será el valor de la mediana de los valores objetivo. Se puede encontrar estableciendo la derivada de nuestro error total con respecto a esa constante a cero, y descúbrela a partir de esta ecuación.
Métricas de regresión en aprendizaje automático ml: R al cuadrado (R²)
Ahora, ¿qué pasa si le dije que MSE para mis predicciones de modelos es 32? ¿Debo mejorar mi modelo o es lo suficientemente bueno? ¿O si mi MSE era 0,4?.
En realidad, es difícil darse cuenta si nuestro modelo es bueno o no al observar los valores absolutos de MSE o RMSE. Probablemente querremos medir cómo Mucho nuestro modelo es mejor que la línea de base constante.
El coeficiente de determinación, o R² (a veces leído como R-dos), es otra medida que podemos usar para evaluar un modelo y está estrechamente relacionada con la MSE, pero tiene la ventaja de estar libre de escala , no importa si Los valores de salida son muy grandes o muy pequeños, el R² siempre estará entre -∞ y 1.
Cuando R² es negativo, significa que el modelo es peor que predecir la media.
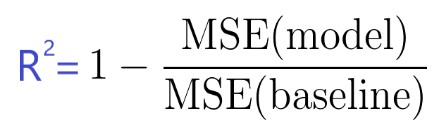
La MSE del modelo se calcula como anteriormente, mientras que la MSE de la línea de base se define como:
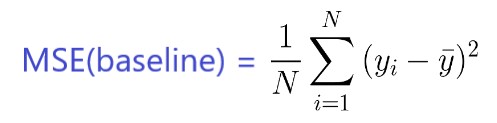
Donde la y con una barra es la media de la y observada.
Para dejarlo más claro, se puede considerar a esta MSE de referencia como la MSE que obtendría el modelo más simple posible .
El modelo más simple posible sería predecir siempre el promedio de todas las muestras. Un valor cercano a 1 indica un modelo con error cercano a cero, y un valor cercano a cero indica un modelo muy cercano a la línea de base.
En conclusión, R² es la proporción entre lo bueno que es nuestro modelo y lo bueno que es el modelo medio ingenuo.
Error común: muchos artículos en la web indican que el rango de R² se encuentra entre 0 y 1, lo que no es realmente cierto. El valor máximo de R² es 1, pero el mínimo puede ser menos infinito.
Por ejemplo, considere un modelo realmente malo que predice un valor altamente negativo para todas las observaciones a pesar de que y_actual es positivo.
En este caso, R² será menor que 0. Este es un escenario altamente improbable pero la posibilidad aún existe.
Aprendizaje automático ml: MAE vs MSE
Declaré que el MAE es más robusto (menos sensible a los valores atípicos) que el MSE, pero esto no significa que siempre sea mejor usar el MAE.
Las siguientes preguntas te ayudan a decidir:
- ¿Tiene valores atípicos (outliers) en los datos?
- Utilice MAE
- ¿Estás seguro de que son valores atípicos (outliers)?
- Utilice MAE
- ¿O simplemente son valores inesperados que todavía deberían preocuparnos?
- Utilice MSE
Resumen
En este artículo, discutimos varias métricas de regresión en aprendizaje automatico más importantes. Primero discutimos, Error cuadrático medio y nos dimos cuenta de que la mejor constante es el valor objetivo medio.
Root Mean Square Error y R² son muy similares a MSE desde la perspectiva de la optimización. Luego discutimos el error absoluto absoluto y cuándo las personas prefieren usar MAE en lugar de MSE.
Te recomiendo que tomes un tiempo antes de comenzar un proyecto y pienses en la métrica apropiada, definitivamente te ayudará mucho.
Si te gusta este artículo también puedes leer otros dos temas interesantes de la Parte 2 que continua con las Métricas de regresión (MSE) Metricas de regresión en aprendizaje automático ml y con la Parte 3 para conocer mas sobre la Seleccion Métricas de clasificación de aprendizaje automático ml.
Si desea aprender más sobre el mundo del aprendizaje automático ml, también puede seguirme en Instagram envíeme un correo electrónico directamente o búsqueme en linkedin .